Tracking the Progress in Natural Language Processing
Research in ML and NLP is moving at a tremendous pace, which is an obstacle for people wanting to enter the field. To make working with new tasks easier, this post introduces a resource that tracks the progress and state-of-the-art across many tasks in NLP.

This post introduces a resource to track the progress and state-of-the-art across many tasks in NLP.
Go directly to the document tracking the progress in NLP.
Research in Machine Learning and in Natural Language Processing (NLP) is moving so fast these days, it is hard to keep up. This is an issue for people in the field, but it is an even bigger obstacle for people wanting to get into NLP and those seeking to make the leap from tutorials to reproducing papers and conducting their own research. Without expert guidance and prior knowledge, it can be a painstaking process to identify the most common datasets and the current state-of-the-art for your task of interest.
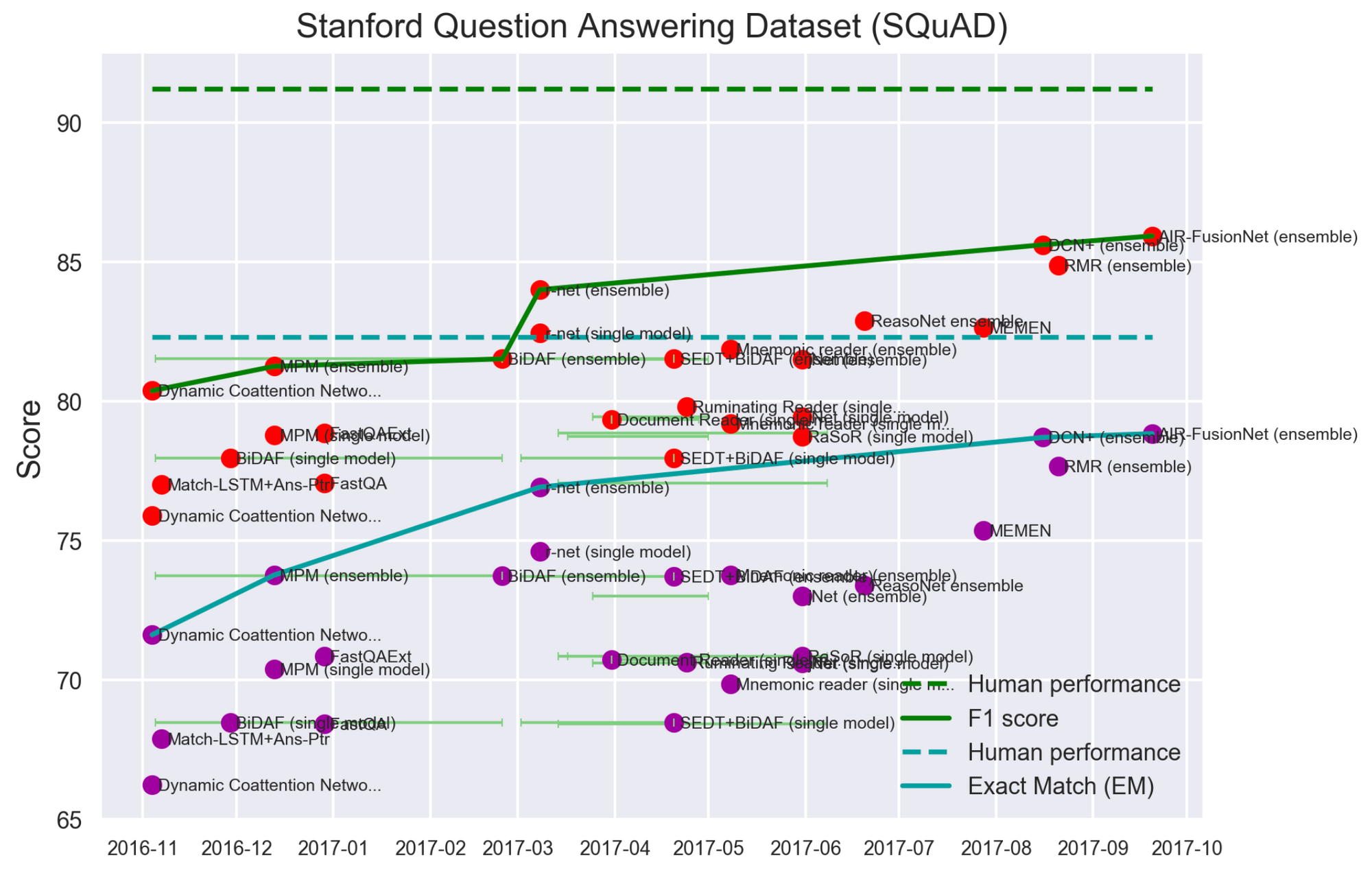
A number of resources exist that could help with this process, but each has deficits: The Association of Computation Linguistics (ACL) has a wiki page tracking the state-of-the-art, but the page is not maintained and contributing is not straightforward. The Electronic Frontier Foundation and the AI Index try to do something similar for all of AI but only cover a few language tasks. The Language Resources and Evaluation (LRE) Map collects language resources presented at LREC and other conferences, but does not allow to break them out by tasks or popularity. Similarly, the International Workshop on Semantic Evaluation (SemEval) hosts a small number of tasks each year, which provide new datasets that typically have not been widely studied before. There are also resources that focus on computer vision and speech recognition as well as this repo, which focuses on all of ML.
As an alternative, I have created a GitHub repository that keeps track of the datasets and the current state-of-the-art for the most common tasks in NLP. The repository is kept as simple as possible to make maintenance and contribution easy. If I missed your favourite task or dataset or your new state-of-the-art result or if I made any error, you can simply submit a pull request.
The aim is to have a comprehensive and up-to-date resource where everyone can see at a glance the state-of-the-art for the tasks they care about. Datasets, which already do a great job at tracking this such as SQuAD or SNLI using a public leaderboard will simply be referenced instead.
My hope is that such a resource will give a broader sense of progress in the field than results in individual papers. It might also make it easier to identify tasks or areas where progress has been lacking. Another benefit is that such a resource may encourage serendipity: chancing upon an interesting new task or method. Finally, a positive by-product of having the state-of-the-art for each task easily accessible may be that it will be harder to justify (accidentally) comparing to weak baselines. For instance, the perplexity of the best baseline on the Penn Treebank varied dramatically across 10 language modeling papers submitted to ICLR 2018 (see below).

Credit for the cover image is due to the Electronic Frontier Foundation.