NeurIPS 2023 Primer
A round-up of 20 exciting NeurIPS 2023 papers related to LLMs.

NeurIPS 2023, arguably this year’s biggest AI conference takes place in two weeks from Dec 10–16 in New Orleans. 3586 papers were accepted to the conference, which are available online.
In this post, I’ll discuss a selection of 20 papers related to natural language processing (NLP) that caught my eye, with a focus on oral and spotlight papers. Here are the main trends I observed:
- Most NLP work at NeurIPS is related to large language models (LLMs). While there are some papers that do not employ LLMs or use a different setting (see Suhr & Artzi below, for instance), papers still presented their contributions in the context of LLMs.
- Synthetic setups to analyze LLM properties are becoming more common. This is because it is computationally prohibitive to run many different pre-training experiments. Investigated properties range from the emergence of in-context learning and learning using global statistics to chain-of-thought reasoning.
- Aligning models based on human preferences received a lot of attention. Papers particularly focused on improving RLHF and studying alignment to specific personality traits and beliefs.
- A comprehensive understanding of in-context learning still remains elusive. Papers studied different aspects of in-context learning such as whether it persists during training and using a Bayesian perspective.
- Reasoning is still challenging with current models. Papers focused on improving performance on various types of reasoning tasks including pragmatic, graph-based, algorithmic, compositional, and planning-based reasoning.
- External tools are increasingly used to improve LLMs’ reasoning abilities. These range from external verifiers to code execution modules.
Note that some of the methods proposed in these papers such as DPO and QLoRA have already been successfully used in LLM applications.
This post was first published in NLP News.
Rethinking LLMs
This is one of my favorite topics as these papers encourage us to rethink our fundamental assumptions regarding LLMs and provide new insights and perspectives on their inner workings.
Lexinvariant Language Models (Huang et al.). One of the fundamental characteristics of LMs that hasn’t changed since the first neural LM paper is the one-to-one mapping between tokens and embeddings. This paper studies whether language modeling can also be done with models that are ‘lexinvariant’, i.e., that do not have fixed token embeddings but assign the lexical permutation of each sequence the same probability. This seems like a strong limitation—but it can serve as a useful inductive bias for recovering substitution cyphers (via an MLP probe) and in-context symbol manipulation. In practice, tokens are encoded using random Gaussian vectors and sampled so that the same token has the same representation within a sequence but different representations across sequences. While this method is mainly of theoretical interest, using it as regularization by using random embeddings only for a subset of tokens improves results on some BIG-bench tasks.
Learning from Human Feedback
Given the proliferation of different pre-trained LLMs, researchers and practitioners are increasingly looking to improve the next step in the LLM pipeline: learning from human feedback, which is important for maximizing performance on downstream tasks but also for LLM alignment.
Direct Preference Optimization: Your Language Model is Secretly a Reward Model (Rafailov et al.). Reinforcement learning from human feedback (RLHF) is the preferred approach to update LLMs to align with target preferences but is quite complex (it requires first training a reward model and then updating the LLM with RL based on the reward model) and can be unstable. This paper proposes Direct Preference Optimization (DPO), which shows that the same objective can be optimized via a simple classification-based objective on the preference data—without any RL! An important component of the objective is a dynamic, per-example importance weight. DPO has the potential to make aligning LLMs with human preferences much more seamless—and will thus be important for safety research.
Fine-Grained Human Feedback Gives Better Rewards for Language Model Training (Wu et al.). This paper addresses another limitation of RLHF, which does not allow the integration of more fine-grained feedback regarding which parts of the generated response are erroneous. The paper proposes Fine-grained RLHF, which a) uses a dense reward model (a reward for every output sentence rather than for the entire output) and b) incorporates multiple reward models for diverse feedback. They experiment on detoxification and long-form question answering where they see improved results compared to RLHF and supervised fine-tuning. Importantly, as providing human preference judgements for RLHF is a complex annotation task, providing more fine-grained feedback is actually not more time-intensive. Expect to see more approaches experimenting with various reward models at different granularities.
Continual Learning for Instruction Following from Realtime Feedback (Suhr & Artzi). This paper tackles continual learning from human feedback in a collaborative 3D world environment. They demonstrate a simple approach using a contextual bandit to update the model’s policy using binary rewards. Over 11 rounds of training and deployment, instruction execution accuracy improves from 66.7% to 82.1%. Empirically, in this setting, the feedback data provides a similar amount of learning signal as the supervised data. While their setting differs from the standard text-based scenario, it provides a sketch for how instruction-following agents can continually learn from human feedback. In the future, we will likely see approaches that utilize more expressive feedback such as via natural language.
LLM Alignment
In order to ensure that LLMs are most useful, it is crucial to align them with the specific guidelines, safety policies, personality traits and beliefs that are relevant for a given downstream setting. To do this, we first need to understand what tendencies LLMs already encode—and then develop methods to steer them appropriately.
Evaluating and Inducing Personality in Pre-trained Language Models (Jiang et al.). This paper proposes to assess the personality of LLMs based on the Big Five personality traits known from psychology. Building on existing questionnaires, they create multiple-choice question answering examples where the LLM must choose how accurately statements such as “You love to help others” describe it. Each statement is associated with a personality trait. Crucially, it is less important whether a model scores highly on a specific trait but whether it exhibits a consistent personality, that is, whether it responds similarly to all questions associated with the trait. Only the largest models exhibit consistent personality traits that are similar to those of humans. It will be interesting to better understand under what conditions personality traits emerge and how consistent personalities can be encoded in smaller models.
In-Context Impersonation Reveals Large Language Models' Strengths and Biases (Salewski et al.). There has been a lot of anecdotal evidence that prompting LLMs to impersonate domain experts (e.g., “you are an expert programmer”, etc) improved models’ capabilities. This paper studies such in-context impersonation across different tasks and finds indeed that LLMs impersonating domain experts perform better than LLMs impersonating non-domain experts. Impersonation is also useful to detect implicit biases. For instance, LLMs impersonating a man describe cars better than ones prompted to be a woman (based on CLIP’s ability to match an image to a category using the generated description of the category). Overall, impersonation is a useful tool to analyze LLMs—but may reinforce biases when used for (system) prompts.
Evaluating the Moral Beliefs Encoded in LLMs (Scherer et al.). This paper studies how moral beliefs are encoded in LLMs with regard to both high-ambiguity (“Should I tell a white lie?”) and low-ambiguity scenarios (“Should I stop for a pedestrian on the road?”) scenarios. They evaluate 28 (!) different LLMs and find that a) in unambiguous scenarios most models align with commonsense while in ambiguous cases, most models express uncertainty; b) models are sensitive to the wording of the question; and c) some models exhibit clear preferences in ambiguous scenarios—and closed-source models have similar preferences. While the evaluation relies on a heuristic mapping of output sequences to actions, the data is useful for further research of LLMs’ moral beliefs.
LLM Pre-training
Pre-training is the most compute-intensive part of LLM pipelines and is thus harder to study at scale. Nevertheless, innovations such as new scaling laws improve our understanding of pre-training and inform future training runs.
Scaling Data-Constrained Language Models (Muennighoff et al.). As the amount of text online is limited, this paper investigates scaling laws in data-constrained regimes, in contrast to the scaling laws by Hoffmann et al. (2022), which focused on scaling without repeating data. The authors observe that training for up to 4 epochs on repeated data performs similarly to training on unique data. With more repetition, however, the value of additional training rapidly diminishes. In addition, augmenting the pre-training data with code meaningfully increases the pre-training data size. In sum, whenever we don’t have infinite amounts of pre-training data, we should train smaller models for more (up to 4) epochs.
LLM Fine-tuning
Fine-tuning large models with back-propagation is expensive so these papers propose methods to make fine-tuning more efficient, either using parameter-efficient fine-tuning methods or without computing gradients (zeroth-order optimization).
QLoRA: Efficient Finetuning of Quantized LLMs (Dettmers et al.). This paper proposes QLoRA, a more memory-efficient (but slower) version of LoRA that uses several optimization tricks to save memory. They train a new model, Guanaco, that is fine-tuned only on a single GPU for 24h and outperforms previous models on the Vicuna benchmark. Overall, QLoRA enables using much fewer GPU memory for fine-tuning LLMs. Concurrently, other methods such as 4-bit LoRA quantization have been developed that achieve similar results.
Fine-Tuning Language Models with Just Forward Passes (Malladi et al.). This paper proposes a memory-efficient zeroth-order optimizer (MeZO) as a more memory-efficient version of a classic zeroth-order optimizer that uses differences of loss values to estimate gradients. In practice, the method achieves similar performance to fine-tuning on several tasks but requires 100x more optimization steps (while being faster at each iteration). Nevertheless, it is surprising that such zeroth-order optimization works with very large models in the first place, demonstrating the robustness of such models, and is an interesting direction for future work.
Emergent Abilities and In-context Learning
Certain abilities of LLMs such as in-context learning and arithmetic reasoning have been shown to be present only in the largest models. It is still unclear how these abilities are acquired during training and what specific properties lead to their emergence, motivating many studies in this area.
Are Emergent Abilities of Large Language Models a Mirage? (Schaeffer et al.). Emergent abilities are abilities that are present in large-scale models but not in smaller models and are hard to predict. Rather than being a product of models’ scaling behavior, this paper argues that emergent abilities are mainly an artifact of the choice of metric used to evaluate them. Specifically, nonlinear and discontinuous metrics can lead to sharp and unpredictable changes in model performance. Indeed, the authors find that when accuracy is changed to a continuous metric for arithmetic tasks where emergent behavior was previously observed, performance improves smoothly instead. So while emergent abilities may still exist, they should be properly controlled and researchers should consider how the chosen metric interacts with the model.
The Transient Nature of Emergent In-Context Learning in Transformers (Singh et al.). Chan et al. (2022) have previously shown that the distributional properties of language data (specifically, ‘burstiness’ and a highly skewed distribution) play an important role in the emergence of in-context learning (ICL) in LLMs. Prior work also generally assumes that once the ICL ability has been acquired, it is retained by the model as learning progresses. This paper uses Omniglot, a synthetic image few-shot dataset to show cases where ICL emerges—only to be subsequently lost while the loss continues to decrease. On the other hand, L2 regularization seems to help the model retain its ICL ability. It is still unclear, however, how ICL emerges and if transience can be observed during LLM pre-training on real-world natural language data.
Why think step by step? Reasoning emerges from the locality of experience (Prystawski et al.). This paper investigates why and how chain-of-thought reasoning (Wei et al., 2022) is useful in LLMs using a synthetic setup. Similar to Chan et al. (2022), they study distributional properties of the pretraining data. They find that chain-of-thought reasoning is only useful when the training data is locally structured. In other words, when examples are about closely connected topics as is common in natural language. They find that chain-of-thought reasoning is helpful because it incrementally chains local statistical dependencies that are frequently observed in training. It is still unclear, however, when chain-of-thought reasoning emerges during training and what are the properties of downstream tasks where it is most useful.
Large Language Models Are Latent Variable Models: Explaining and Finding Good Demonstrations for In-Context Learning (Wang et al.). This paper frames in-context learning with LLMs as topic modeling where the generated tokens are conditioned on a latent topic (concept) variable, which captures format and task information. To make this computationally efficient, they use a smaller LM to learn the latent concepts via prompt tuning on the full demonstration data. They then select the examples that achieve the highest probability under the prompt-tuned model as demonstrations for in-context learning, which improves over other selection baselines. This is a further data point that shows that examples that are probable based on a latent concept of a task are useful demonstrations. This likely isn’t the full picture, however, and it will be interesting to see how this formulation relates to other data similarity and diversity measures.
Birth of a Transformer: A Memory Viewpoint (Bietti et al.). This study investigates how LLMs learn in-context learning as well as the ability to use more general knowledge in a synthetic setup. The setup consists of sequences generated by a bigram LM where some bigrams require the local context to infer them while others require global statistics. They find that two-layer transformers (but not one-layer transformers) develop an induction head consisting of a “circuit” of two attention heads to predict in-context bigrams. They then freeze some of the layers to study the model’s training dynamics, finding that global bigrams are learned first and that the induction head learns appropriate memories in a top-down fashion. Overall, this paper sheds further light on how in-context learning can emerge in LMs.
Reasoning
Reasoning tasks that require the systematic chaining or composition of different pieces of information are one of the most important problems for current LLMs to solve. Their challenging nature and the diversity of domains where they are relevant makes them a fruitful area for research.
On the Planning Abilities of Large Language Models - A Critical Investigation (Valmeekam et al.). Planning and sequential decision making are important for a wide range of applications. This paper studies whether LLMs can generate simple plans for commonsense planning tasks2. Used on their own, only 12% of the plans generated by the best LLM are directly executable. However, when combined with an automated planning algorithm that can identify and remove errors in the LLM-generated plan, LLMs do much better than using a random or empty initial plan. LLMs plans can also be improved via prompting based on feedback from an external verifier. On the other hand, the benefits of LLMs disappear when action names are unintelligible and cannot be easily inferred with common sense, which indicates a lack of abstract reasoning ability. Overall, while initial plans of LLMs can be useful as a starting point, LLM-based planning currently works best mainly in conjunction with external tools.
Can Language Models Solve Graph Problems in Natural Language? (Wang et al.) The authors create NLGraph, a benchmark of graph-based reasoning problems described in natural language and evaluate LLMs on it. They find that LLMs demonstrate impressive preliminary graph reasoning abilities—37–58% above random baselines. However, in-context learning and advanced prompting strategies (chain-of-thought prompting and others) are mostly ineffective on more complex graph problems and LLMs are susceptible to spurious correlations. More specialized graph prompting strategies, however, improve results. Expect to see combinations of standard graph-based methods (such as those applied to FB15k) and LLMs and research on methods scaling LLMs to larger graphs.
The Goldilocks of Pragmatic Understanding: Fine-Tuning Strategy Matters for Implicature Resolution by LLMs (Ruis et al.). This paper studies whether LLMs exhibit a particular type of pragmatic inference, implicature3. The authors evaluate whether models can understand implicature by measuring whether they assign a higher probability to a statement that contains the correct inference compared to the incorrect one. They find that both instruction tuning and chain-of-thought prompting are important for such pragmatic understanding and that the largest model, GPT-4 reaches human-level performance. We will likely see more work on different types of pragmatic understanding as these are crucial for seamless and human-like conversations.
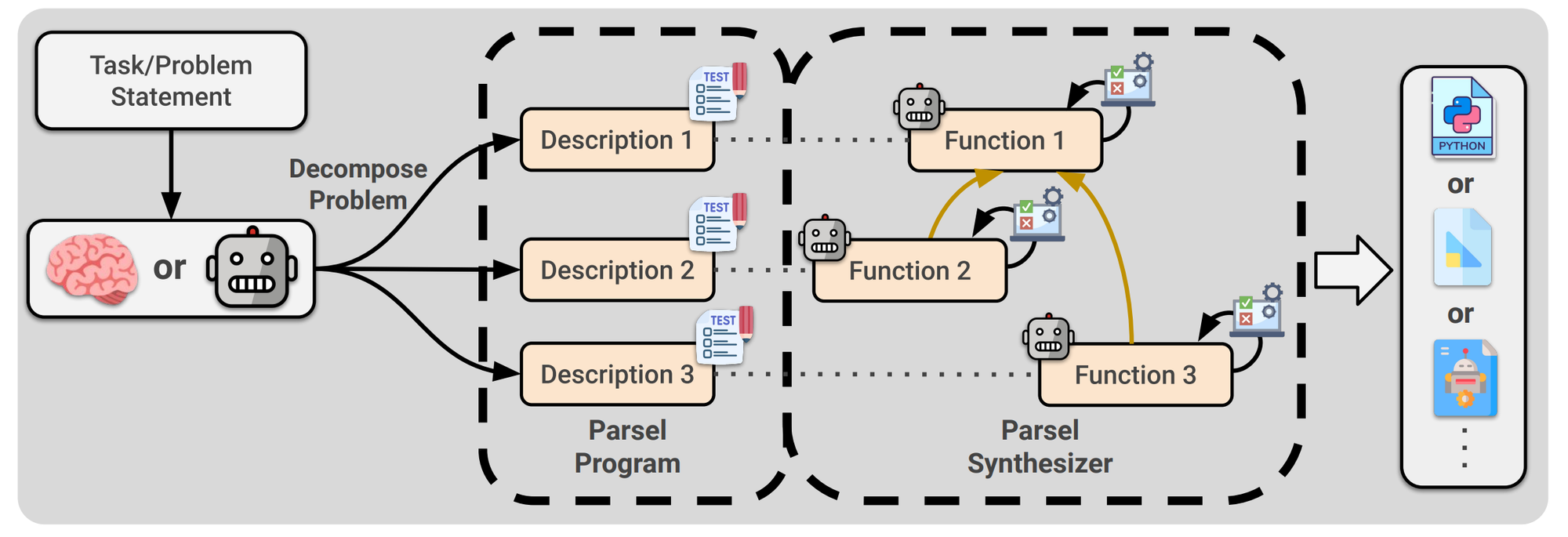
Parsel🐍: Algorithmic Reasoning with Language Models by Composing Decompositions (Zelikman et al.). This paper introduces Parsel, a framework to implement complex programs with code LLMs. An LLM is first used to generate natural language function descriptions in a simple intermediate language. For each function description, the model then generates implementation candidates. The function candidates are then tested against input-output constraints and composed to form the final program. Using GPT-4 as LLM, this framework increased performance on HumanEval from 67% to 85%. This is a great example of how LLMs can be used as a building block together with domain-specific knowledge and tools for much improved performance. In addition, expect to see more work on breaking down complex decision problems into subproblems that are more easily solvable using LLMs.
Faith and Fate: Limits of Transformers on Compositionality (Dziri et al.). This paper investigates the compositional reasoning abilities of LLMs. They formulate compositional reasoning tasks as computation graphs in order to quantify their complexity. They find that full computation subgraphs appear significantly more frequently in the training data for correctly predicted test examples than for incorrectly predicted ones, indicating that models learn to match subgraphs rather than developing systematic reasoning skills. Using a scratchpad and grokking (training beyond overfitting) similarly do not improve performance on more complex problems. Overall, current LLMs still struggle with composing operations into correct reasoning paths.