10 ML & NLP Research Highlights of 2019
This post gathers ten ML and NLP research directions that I found exciting and impactful in 2019.


This post gathers ten ML and NLP research directions that I found exciting and impactful in 2019.
For each highlight, I summarise the main advances that took place this year, briefly state why I think it is important, and provide a short outlook to the future.
The full list of highlights is here:
- Universal unsupervised pretraining
- Lottery tickets
- The Neural Tangent Kernel
- Unsupervised multilingual learning
- More robust benchmarks
- ML and NLP for science
- Fixing decoding errors in NLG
- Augmenting pretrained models
- Efficient and long-range Transformers
- More reliable analysis methods
1) Universal unsupervised pretraining
What happened? Unsupervised pretraining was prevalent in NLP this year, mainly driven by BERT (Devlin et al., 2019) and other variants. A whole range of BERT variants have been applied to multimodal settings, mostly involving images and videos together with text (for an example see the figure below). Unsupervised pretraining has also made inroads into domains where supervision had previously reigned supreme. In biology, Transformer language models have been pretrained on protein sequences (Rives et al., 2019). In computer vision, approaches leveraged self-supervision including CPC (Hénaff et al., 2019), MoCo (He et al., 2019), and PIRL (Misra & van der Maaten, 2019) as well as strong generators such as BigBiGAN (Donahue & Simonyan, 2019) to improve sample efficiency on ImageNet and image generation. In speech, representations learned with a multi-layer CNN (Schneider et al., 2019) or bidirectional CPC (Kawakami et al., 2019) outperform state-of-the-art models with much less training data.
Why is it important? Unsupervised pretraining enables training models with much fewer labelled examples. This opens up new applications in many different domains where data requirements were previously prohibitive.
What's next? Unsupervised pretraining is here to stay. While the biggest advances have been achieved so far in individual domains, it will be interesting to see a focus towards tighter integration of multiple modalities.

2) Lottery tickets
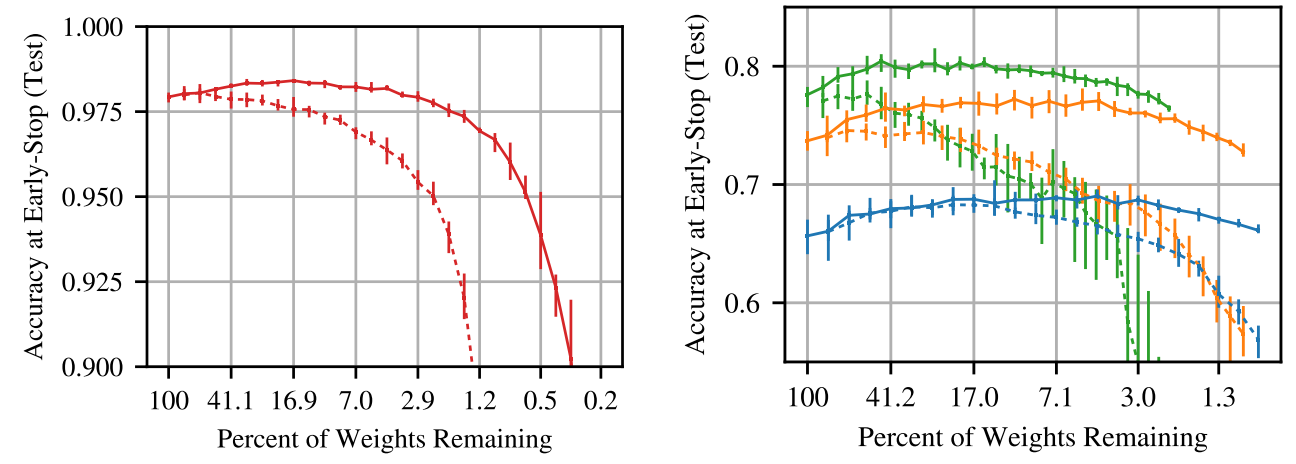
What happened? Frankle and Carbin (2019) identified winning tickets, subnetworks in dense, randomly-initialised, feed-forward networks that are so well initialised that training them in isolation achieves similar accuracy to training the full network, as can be seen below. While the initial pruning procedure only worked on small vision tasks, later work (Frankle et al., 2019) applied the pruning early in training instead of at initialisation, which makes it possible to find small subnetworks of deeper models. Yu et al. (2019) find winning ticket initialisations also for LSTMs and Transformers in NLP and RL models. While winning tickets are still expensive to find, it is promising that they seem to be transferable across datasets and optimisers (Morcos et al., 2019) and domains (Desai et al., 2019).
Why is it important? State-of-the-art neural networks are getting larger and more expensive to train and to use for prediction. Being able to consistently identify small subnetworks that achieve comparable performance enables training and inference with much fewer resources. This can speed up model iteration and opens up new applications in on-device and edge computing.
What's next? Identifying winning tickets is currently still too expensive to provide real benefits in low-resource settings. More robust one-shot pruning methods that are less susceptible to noise in the pruning process should mitigate this. Investigating what makes winning tickets special should also help us gain a better understanding of the initialisation and learning dynamics of neural networks.
3) The Neural Tangent Kernel
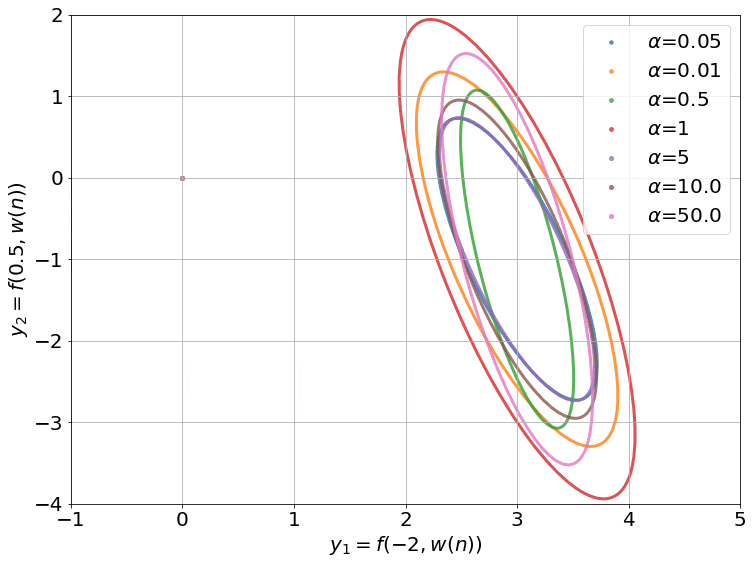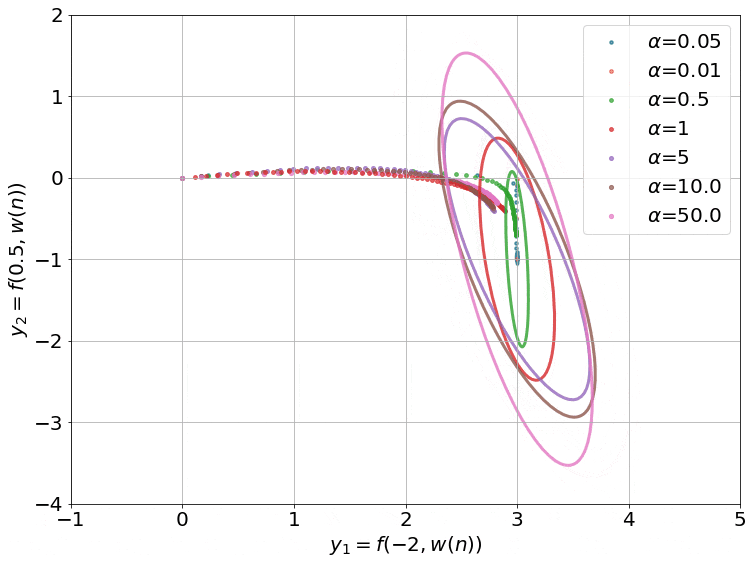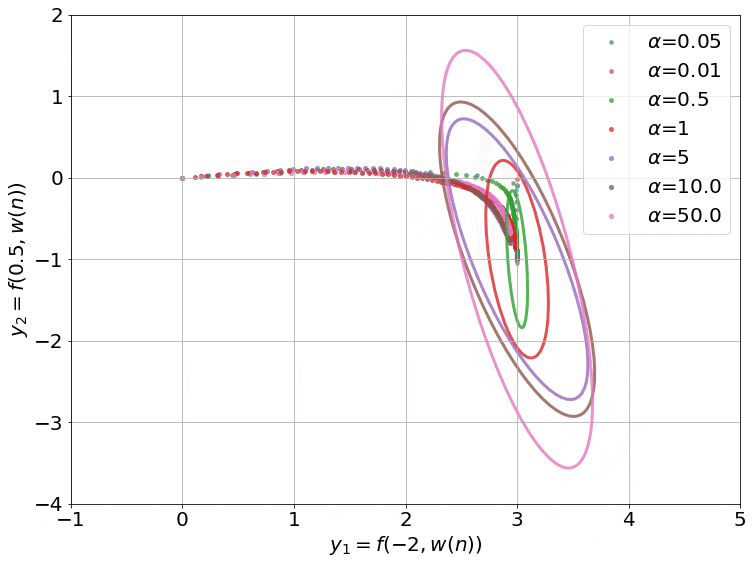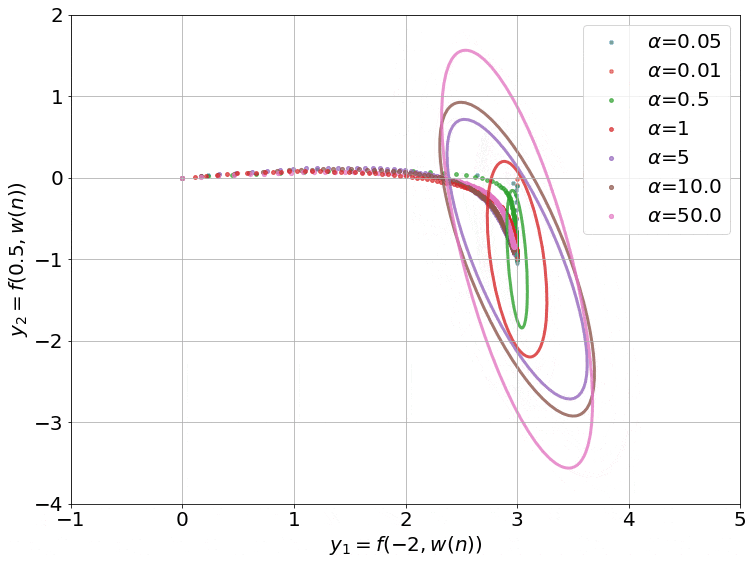
What happened? Somewhat counter-intuitively, very wide (more concretely, infinitely wide) neural networks are easier to study theoretically than narrow ones. It has been shown that in the infinite-width limit, neural networks can be approximated as linear models with a kernel, the Neural Tangent Kernel (NTK; Jacot et al., 2018). Refer to this post for an intuitive explanation of NTK including an illustration of its training dynamics (see the figure below). In practice, such models, have underperformed their finite-depth counterparts (Novak et al., 2019; Allen-Zhu et al., 2019; Bietti & Mairal, 2019), which limits applying the findings to standard methods. Recent work (Li et al., 2019; Arora et al., 2019), however, has significantly reduced the performance gap to standard methods (see Chip Huyen's post for other related NeurIPS 2019 papers).
Why is it important? The NTK is perhaps the most powerful tool at our disposal to analyse the theoretical behaviour of neural networks. While it has its limitations, i.e. practical neural networks still perform better than their NTK counterparts, and insights so far have not translated into empirical gains, it may help us open the black box of deep learning.
What's next? The gap to standard methods seems to be mainly due to benefits of the finite width of such methods, which future work may seek to characterise. This will hopefully also help translating insights from the infinite-width limit to practical settings. Ultimately, the NTK may help us shed light on the training dynamics and generalisation behaviour of neural networks.
4) Unsupervised multilingual learning
What happened? Cross-lingual representations had mostly focused on the word level for many years (see this survey). Building on advances in unsupervised pretraining, this year saw the development of deep cross-lingual models such as multilingual BERT, XLM (Conneau & Lample, 2019), and XLM-R (Conneau et al., 2019). Even though these models do not use any explicit cross-lingual signal, they generalise surprisingly well across languages—even without a shared vocabulary or joint training (Artetxe et al., 2019; Karthikeyan et al., 2019; Wu et al., 2019). For an overview, have a look at this post. Such deep models also brought improvements in unsupervised MT (Song et al., 2019; Conneau & Lample, 2019), which hit its stride last year (see highlights of 2018) and saw improvements from a more principled combination of statistical and neural approaches (Artetxe et al., 2019). Another exciting development is the bootstrapping of deep multilingual models from readily available pretrained representations in English (Artetxe et al., 2019; Tran, 2020), which can be seen below.
Why is it important? Ready-to-use cross-lingual representations enable training of models with fewer examples for languages other than English. Furthermore, if labelled data in English is available, these methods enable essentially free zero-shot transfer. They may finally help us gain a better understanding of the relationships between different languages.
What's next? It is still unclear why these methods work so well without any cross-lingual supervision. Gaining a better understanding of how these methods work will likely enable us to design more powerful methods and may also reveal insights about the structure of different languages. In addition, we should not only focus on zero-shot transfer but also consider learning from few labelled examples in the target language (see this post).
5) More robust benchmarks
There is something rotten in the state of the art.
—Nie et al. (2019) paraphrasing Shakespeare
What happened? Recent NLP datasets such as HellaSWAG (Zellers et al., 2019) are created to be difficult for state-of-the-art models to solve. Examples are filtered by humans to explicitly retain only those where state-of-the-art models fail (see below for an example). This process of human-in-the-loop adversarial curation can be repeated multiple times such as in the recent Adversarial NLI (Nie et al., 2019) benchmark to enable the creation of datasets that are much more challenging for current methods.
Why is it important? Many researchers have observed that current NLP models do not learn what they are supposed to but instead adopt shallow heuristics and exploit superficial cues in the data (described as the Clever Hans moment). As datasets become more robust, we would hope that models will be forced to eventually learn the true underlying relations in the data.
What's next? As models become better, most datasets will need to be continuously improved or will quickly become outdated. Dedicated infrastructure and tools will be necessary to facilitate this process. In addition, appropriate baselines should be run including simple methods and models using different variants of the data (such as with incomplete input) so that initial versions of datasets are as robust as possible.

6) ML and NLP for science
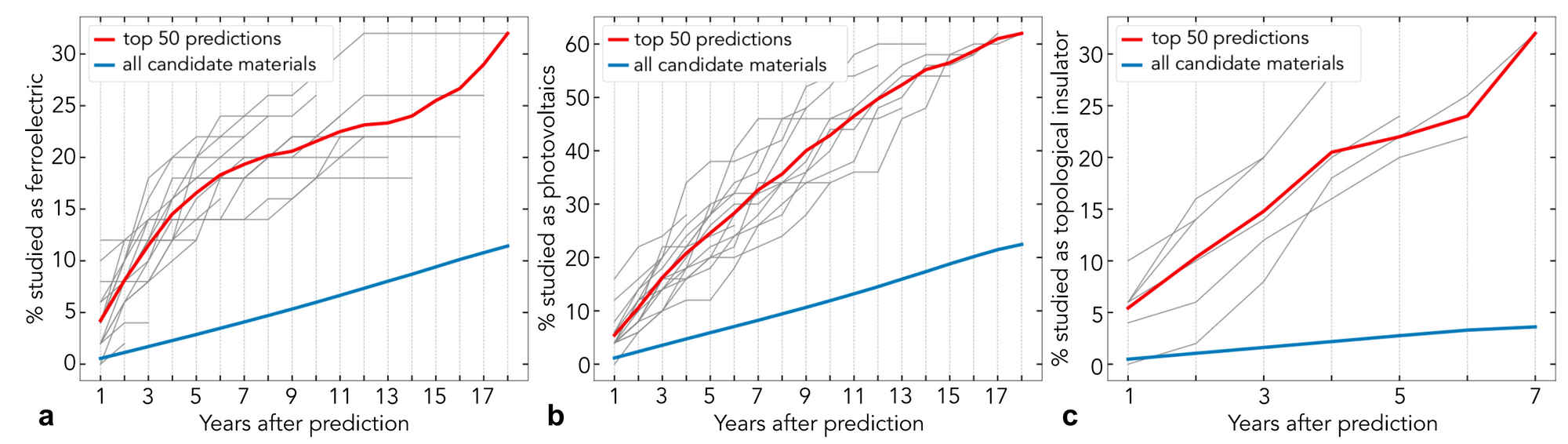
What happened? There have been some major advances of ML being applied to fundamental science problems. My highlights were the application of deep neural networks to protein folding and to the Many-Electron Schrödinger Equation (Pfau et al., 2019). On the NLP side, it is exciting to see what impact even standard methods can have when combined with domain expertise. One study used word embeddings to analyse latent knowledge in the materials science literature (Tshitoyan et al., 2019), which can be used to predict which materials will have certain properties (see the figure below). In biology, a lot of data such as genes and proteins is sequential in nature. It is thus a natural fit for NLP methods such as LSTMs and Transformers, which have been applied to protein classification (Strodthoff et al., 2019; Rives et al., 2019).
Why is it important? Science is arguably one of the most impactful application domains for ML. Solutions can have a large impact on many other domains and can help solve real-world problems.
What's next? From modelling energy in physics problems (Greydanus et al., 2019) to solving differential equations (Lample & Charton, 2020), ML methods are constantly being applied to new applications in science. It will be interesting to see what the most impactful of these will be in 2020.
7) Fixing decoding errors in NLG
What happened? Despite ever more powerful models, natural language generation (NLG) models still frequently produce repetitions or gibberish as can be seen below. This was shown to be mainly a result of the maximum likelihood training. I was excited to see improvements that aim to ameliorate this and are orthogonal to advances in modelling. Such improvements came in the form of new sampling methods, such as nucleus sampling (Holtzman et al., 2019) and new loss functions (Welleck et al., 2019). Another surprising finding was that better search does not lead to better generations: Current models rely to some extent on an imperfect search and beam search errors. In contrast, an exact search most often returns an empty translation in the case of machine translation (Stahlberg & Byrne, 2019). This shows that advances in search and modelling must often go hand in hand.
Why is it important? Natural language generation is one of the most general tasks in NLP. In NLP and ML research, most papers focus on improving the model, while other parts of the pipeline are typically neglected. For NLG, it is important to remind ourselves that our models still have flaws and that it may be possible to improve the output by fixing the search or the training process.
What's next? Despite more powerful models and successful applications of transfer learning to NLG (Song et al., 2019; Wolf et al., 2019), model predictions still contain many artefacts. Identifying and understanding the causes of such artefacts is an important research direction.

8) Augmenting pretrained models
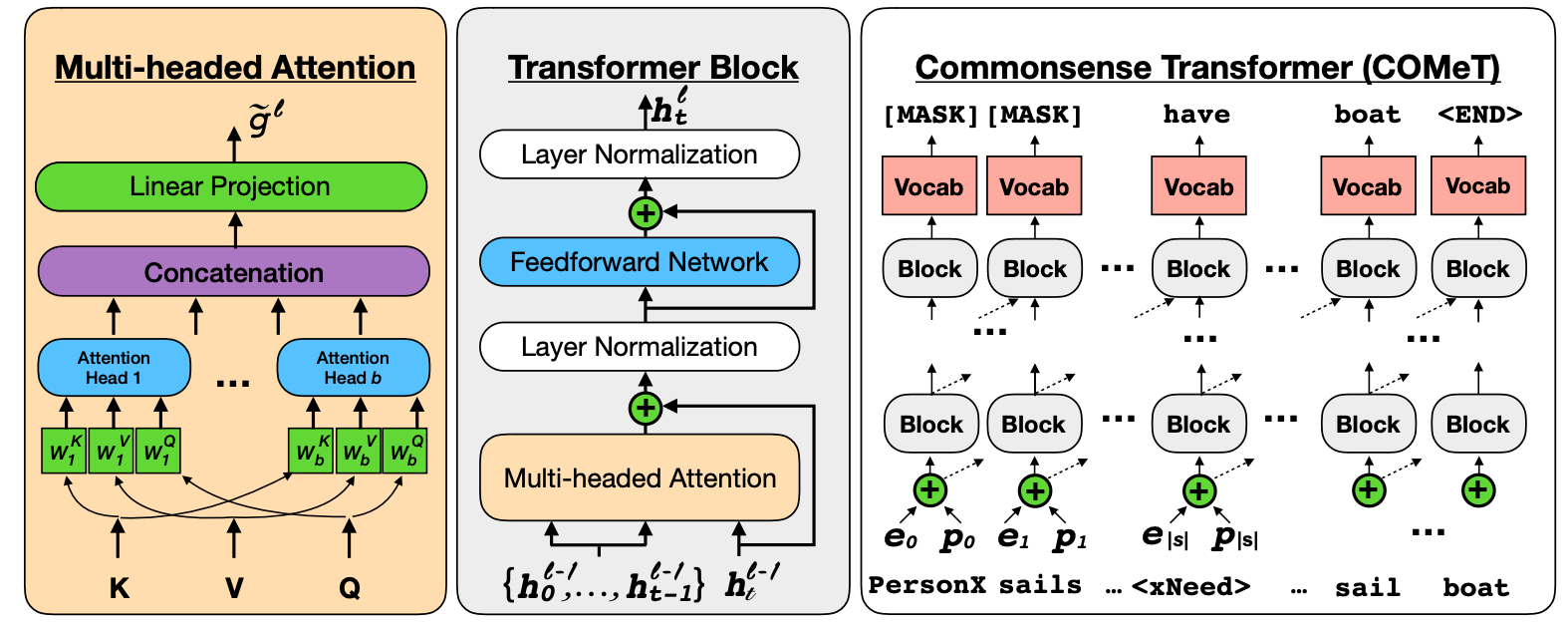
What happened? I was excited to see approaches that equip pretrained models with new capabilities. Some methods augment a pretrained model with a knowledge base in order to improve modelling of entity names (Liu et al., 2019) and the recall of facts (Logan et al., 2019). Others enable it to perform simple arithmetic reasoning (Andor et al., 2019) by giving it access to a number of predefined executable programs. As most models have a weak inductive bias and learn most of their knowledge from data, another way to extend a pretrained model is by augmenting the training data itself, e.g. to capture common sense (Bosselut et al., 2019) as can be seen below.
Why is it important? Models are becoming more powerful but there are many things that a model cannot learn from text alone. Particularly when dealing with more complex tasks, the available data may be too limited to learn explicit reasoning using facts or common sense and a stronger inductive bias may often be necessary.
What's next? As models are being applied to more challenging problems, it will increasingly become necessary for modifications to be compositional. In the future, we might combine powerful pretrained models with learnable compositional programs (Pierrot et al., 2019).
9) Efficient and long-range Transformers
What happened? This year saw several improvements to the Transformer (Vaswani et al., 2017) architecture. The Transformer-XL (Dai et al., 2019) and the Compressive Transformer (Rae et al., 2020), which can be seen below enable it to better capture long-range dependencies. Many approaches sought to make the Transformer more efficient mostly using different—often sparse—attention mechanisms, such as adaptively sparse attention (Correia et al., 2019), adaptive attention spans (Sukhbaatar et al., 2019), product-key attention (Lample et al., 2019), and locality-sensitive hashing (Kitaev et al., 2020). On the Transformer-based pretraining front, there have been more efficient variants such as ALBERT (Lan et al., 2020), which employs parameter sharing and ELECTRA (Clark et al., 2020), which uses a more efficient pretraining task. There were also more efficient pretrained models that did not utilise a Transformer, such as the unigram document model VAMPIRE (Gururangan et al., 2019) and the QRNN-based MultiFiT (Eisenschlos et al., 2019). Another trend was the distillation of large BERT models into smaller ones (Tang et al., 2019; Tsai et al., 2019; Sanh et al., 2019).
Why is it important? The Transformer architecture has been influential since its inception. It is a part of most state-of-the-art models in NLP and has been successfully applied to many other domains (see Sections 1 and 6). Any improvement to the Transformer architecture may thus have strong ripple effects.
What's next? It will take some time for these improvements to trickle down to the practitioner but given the prevalence and ease of use of pretrained models, more efficient alternatives will likely be adopted quickly. Overall, we will hopefully see a continuing focus on model architectures that emphasise efficiency, with sparsity being one of the key trends.
10) More reliable analysis methods
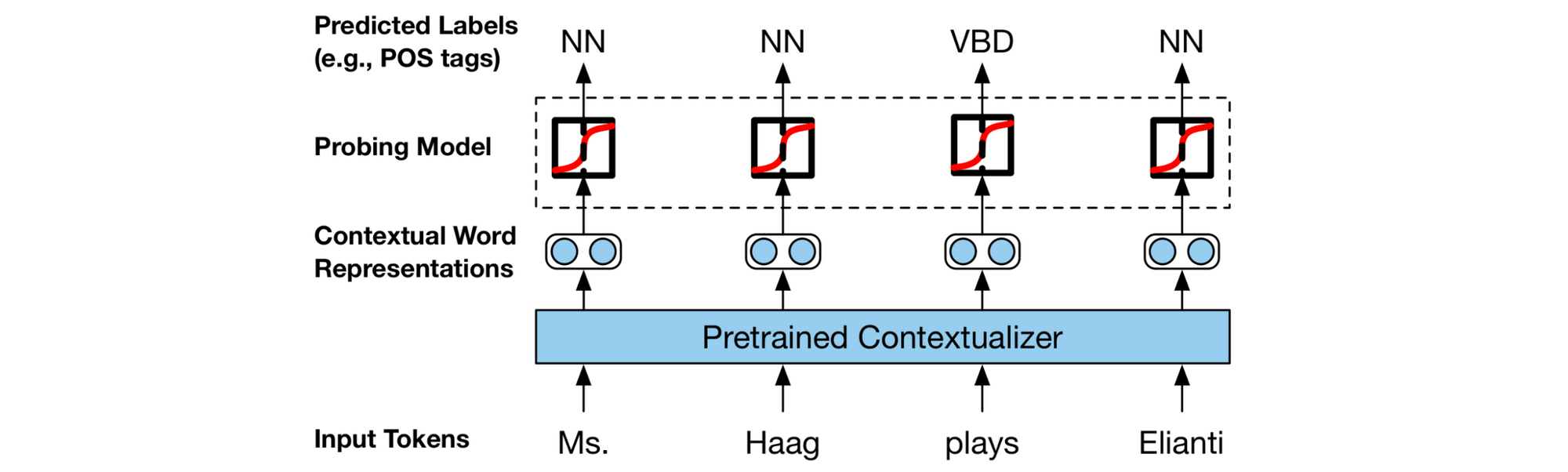
What happened? A key trend for me this year was the increasing number of papers analysing models. In fact, several of my favourite papers this year were such analysis papers. An early highlight was the excellent survey of analysis methods by Belinkov & Glass (2019). This year was also the first one (in my memory) where many papers were dedicated to analysing a single model, BERT (such papers are known as BERTology). In this context, probes (see the figure below), which aim to understand whether a model captures morphology, syntax, etc. by predicting certain properties have become a common tool. I particularly appreciated papers that make probes more reliable (Liu et al., 2019; Hewitt & Liang, 2019). Reliability is also a theme in the ongoing conversation on whether attention provides meaningful explanations (Jain & Wallace, 2019; Wiegreffe & Pinter, 2019; Wallace, 2019). The continuing interest in analysis methods is perhaps best exemplified by the new ACL 2020 track on Interpretability and Analysis of Models in NLP.
Why is it important? State-of-the-art methods are used as black boxes. In order to develop better models and to use them in the real world, we need to understand why models make certain decisions. However, our current methods to explain models' predictions are still limited.
What's next? We need more work on explaining predictions that goes beyond visualisation, which is often unreliable. An important trend in this direction are human-written explanations that are being provided by more datasets (Camburu et al., 2018; Rajani et al., 2019; Nie et al., 2019).