Learning to select data for transfer learning
Domain adaptation methods typically seek to identify features that are shared between the domains or learn representations that are general enough to be useful for both domains. This post discusses a complementary approach to domain adaptation that selects data that is useful for training the model.

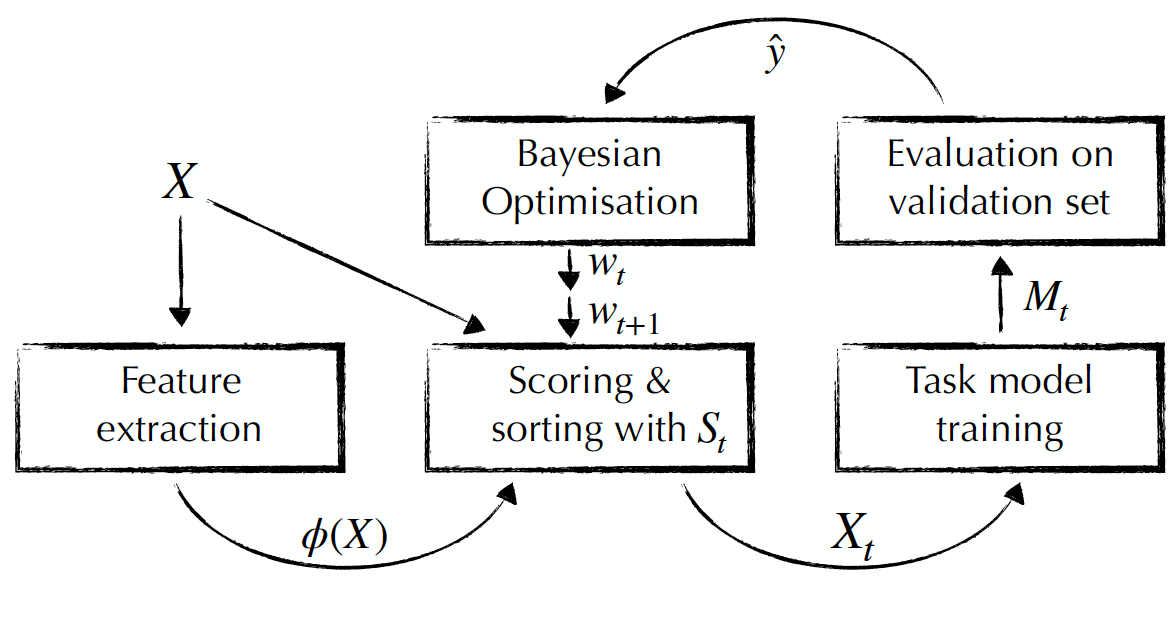
This post discusses how Bayesian Optimization can be used to select relevant training data for domain adaptation.
This post originally appeared on the AYLIEN blog.
Introduction
In Machine Learning, the common assumption is that the data our model is applied to is the same, i.e. comes from the same distribution as the data we used for training. This assumption is revealed to be false as soon as we apply our models to the real world: many of the data sources we encounter will be very different from our original training data. In practice, this causes the performance of our model to deteriorate significantly.
Domain adaptation is a prominent approach to transfer learning that can help to bridge this discrepancy between the training and test data. Domain adaptation is a type of transfer learning, which I have written about here. Domain adaptation methods typically seek to identify features that are shared between the domains or learn representations that are general enough to be useful for both domains. In this blog post, I will discuss the motivation for, and the findings of the recent paper that I published with Barbara Planck. In it, we outline a complementary approach to domain adaptation – rather than learning a model that can adapt between the domains, we will learn to select data that is useful for training our model.
Preventing Negative Transfer
The main motivation behind selecting data for transfer learning is to prevent negative transfer. Negative transfer occurs if the information from our source training data is not only unhelpful but actually counter-productive for doing well on our target domain. The classic example for negative transfer comes from sentiment analysis: if we train a model to predict the sentiment of book reviews, we can expect the model to do well on domains that are similar to book reviews. Transferring a model trained on book reviews to reviews of electronics, however, results in negative transfer, as many of the terms our model learned to associate with a certain sentiment for books, e.g. “page-turner”, “gripping”, or — worse — “dangerous” and “electrifying”, will be meaningless or have different connotations for electronics reviews.
In the classic scenario of adapting from one source to one target domain, the only thing we can do about this is to create a model that is capable of disentangling these shifts in meaning. However, adapting between two very dissimilar domains still fails frequently or leads to painfully poor performance.
In the real world, we typically have access to multiple data sources. In this case, one thing that we can do is to train our model on the data that is most helpful for our target domain. It is unclear, however, what the best way to determine the helpfulness of source data with respect to a target domain is. Existing work generally relies on measures of similarity between the source and the target domain.
Bayesian Optimization for Data Selection
Our hypothesis is that the best way to select training data for transfer learning depends on the task and the target domain. In addition, while existing measures only consider data in relation to the target domain, we also argue that some training examples are inherently more helpful than others.
For these reasons, we propose to learn a data selection measure for transfer learning. We do this using Bayesian Optimization, a framework that has been used successfully to optimize hyperparameters in neural networks and which can be used to optimize any black-box function. We learn this function by defining several features relating to the similarity of the training data to the target domain as well as to its diversity. Over the course of several iterations, the data selection model then learns the importance of each of those features for the relevant task.
Evaluation & Conclusion
We evaluate our approach on three tasks, sentiment analysis, part-of-speech tagging, and dependency parsing and compare our approach to random selection as well as existing methods that select either the most similar source domain or the most similar training examples.
For sentiment analysis on reviews, training on the most similar domain is a strong baseline as review categories are clearly delimited. We significantly improve upon this baseline and demonstrate that diversity complements similarity. We even achieve performance competitive with a state-of-the-art domain adaptation approach, despite not performing any adaptation.
We observe smaller, but consistent improvements for part-of-speech tagging and dependency parsing. Lastly, we evaluate how well learned measures transfer across models, tasks, and domains. We find that learning a data selection measure can be learned with a simpler model, which is used as a proxy for a state-of-the-art model. Transfer across domains is robust, while transfer across tasks holds — as one would expect — for related tasks such as POS tagging and parsing, but fails for dissimilar tasks, e.g. parsing and sentiment analysis.
In the paper, we demonstrate the importance of selecting relevant data for transfer learning. We show that taking into account task and domain-specific characteristics and learning an appropriate data selection measure outperforms off-the-shelf metrics. We find that diversity complements similarity in selecting appropriate training data and that learned measures can be transferred robustly across models, domains, and tasks.
This work will be presented at the 2017 Conference on Empirical Methods in Natural Language Processing. More details can be found in the paper here.