Optimization for Deep Learning Highlights in 2017
Different gradient descent optimization algorithms have been proposed in recent years but Adam is still most commonly used. This post discusses the most exciting highlights and most promising recent approaches that may shape the way we will optimize our models in the future.

This post discusses the most exciting highlights and most promising directions in optimization for Deep Learning.
Table of contents:
- Improving Adam
- Decoupling weight decay
- Fixing the exponential moving average
- Tuning the learning rate
- Warm restarts
- SGD with restarts
- Snapshot ensembles
- Adam with restarts
- Learning to optimize
- Understanding generalization
Deep Learning ultimately is about finding a minimum that generalizes well -- with bonus points for finding one fast and reliably. Our workhorse, stochastic gradient descent (SGD), is a 60-year old algorithm (Robbins and Monro, 1951) [1], that is as essential to the current generation of Deep Learning algorithms as back-propagation.
Different optimization algorithms have been proposed in recent years, which use different equations to update a model's parameters. Adam (Kingma and Ba, 2015) [2] was introduced in 2015 and is arguably today still the most commonly used one of these algorithms. This indicates that from the Machine Learning practitioner's perspective, best practices for optimization for Deep Learning have largely remained the same.
New ideas, however, have been developed over the course of this year, which may shape the way we will optimize our models in the future. In this blog post, I will touch on the most exciting highlights and most promising directions in optimization for Deep Learning in my opinion. Note that this blog post assumes a familiarity with SGD and with adaptive learning rate methods such as Adam. To get up to speed, refer to this blog post for an overview of existing gradient descent optimization algorithms.
Improving Adam
Despite the apparent supremacy of adaptive learning rate methods such as Adam, state-of-the-art results for many tasks in computer vision and NLP such as object recognition (Huang et al., 2017) [3] or machine translation (Wu et al., 2016) [4] have still been achieved by plain old SGD with momentum. Recent theory (Wilson et al., 2017) [5] provides some justification for this, suggesting that adaptive learning rate methods converge to different (and less optimal) minima than SGD with momentum. It is empirically shown that the minima found by adaptive learning rate methods perform generally worse compared to those found by SGD with momentum on object recognition, character-level language modeling, and constituency parsing. This seems counter-intuitive given that Adam comes with nice convergence guarantees and that its adaptive learning rate should give it an edge over the regular SGD. However, Adam and other adaptive learning rate methods are not without their own flaws.
Decoupling weight decay
One factor that partially accounts for Adam's poor generalization ability compared with SGD with momentum on some datasets is weight decay. Weight decay is most commonly used in image classification problems and decays the weights \(\theta_t\) after every parameter update by multiplying them by a decay rate \(w_t\) that is slightly less than \(1\):
\(\theta_{t+1} = w_t \: \theta_t \)
This prevents the weights from growing too large. As such, weight decay can also be understood as an \(\ell_2\) regularization term that depends on the weight decay rate \(w_t\) added to the loss:
\(\mathcal{L}_\text{reg} = \dfrac{w_t}{2} |\theta_t |^2_2 \)
Weight decay is commonly implemented in many neural network libraries either as the above regularization term or directly to modify the gradient. As the gradient is modified in both the momentum and Adam update equations (via multiplication with other decay terms), weight decay no longer equals \(\ell_2\) regularization. Loshchilov and Hutter (2017) [6] thus propose to decouple weight decay from the gradient update by adding it after the parameter update as in the original definition.
The SGD with momentum and weight decay (SGDW) update then looks like the following:
\(
\begin{align}
\begin{split}
v_t &= \gamma v_{t-1} + \eta g_t \\
\theta_{t+1} &= \theta_t - v_t - \eta w_t \theta_t
\end{split}
\end{align}
\)
where \(\eta\) is the learning rate and the third term in the second equation is the decoupled weight decay. Similarly, for Adam with weight decay (AdamW) we obtain:
\(
\begin{align}
\begin{split}
m_t &= \beta_1 m_{t-1} + (1 - \beta_1) g_t \\
v_t &= \beta_2 v_{t-1} + (1 - \beta_2) g_t^2\\
\hat{m}_t &= \dfrac{m_t}{1 - \beta^t_1} \\
\hat{v}_t &= \dfrac{v_t}{1 - \beta^t_2} \\
\theta_{t+1} &= \theta_{t} - \dfrac{\eta}{\sqrt{\hat{v}_t} + \epsilon} \hat{m}_t - \eta w_t \theta_t
\end{split}
\end{align}
\)
where \(m_t\) and \(\hat{m}_t\) and \(v_t\) and \(\hat{v}_t\) are the biased and bias-corrected estimates of the first and second moments respectively and \(\beta_1\) and \(\beta_2\) are their decay rates, with the same weight decay term added to it. The authors show that this substantially improves Adam’s generalization performance and allows it to compete with SGD with momentum on image classification datasets.
In addition, it decouples the choice of the learning rate from the choice of the weight decay, which enables better hyperparameter optimization as the hyperparameters no longer depend on each other. It also separates the implementation of the optimizer from the implementation of the weight decay, which contributes to cleaner and more reusable code (see e.g. the fast.ai AdamW/SGDW implementation).
Fixing the exponential moving average
Several recent papers (Dozat and Manning, 2017; Laine and Aila, 2017) [7],[8] empirically find that a lower \(\beta_2\) value, which controls the contribution of the exponential moving average of past squared gradients in Adam, e.g. \(0.99\) or \(0.9\) vs. the default \(0.999\) worked better in their respective applications, indicating that there might be an issue with the exponential moving average.
An ICLR 2018 submission formalizes this issue and pinpoints the exponential moving average of past squared gradients as another reason for the poor generalization behaviour of adaptive learning rate methods. Updating the parameters via an exponential moving average of past squared gradients is at the heart of adaptive learning rate methods such as Adadelta, RMSprop, and Adam. The contribution of the exponential average is well-motivated: It should prevent the learning rates to become infinitesimally small as training progresses, the key flaw of the Adagrad algorithm. However, this short-term memory of the gradients becomes an obstacle in other scenarios.
In settings where Adam converges to a suboptimal solution, it has been observed that some minibatches provide large and informative gradients, but as these minibatches only occur rarely, exponential averaging diminishes their influence, which leads to poor convergence. The authors provide an example for a simple convex optimization problem where the same behaviour can be observed for Adam.
To fix this behaviour, the authors propose a new algorithm, AMSGrad that uses the maximum of past squared gradients rather than the exponential average to update the parameters. The full AMSGrad update without bias-corrected estimates can be seen below:
\(
\begin{align}
\begin{split}
m_t &= \beta_1 m_{t-1} + (1 - \beta_1) g_t \\
v_t &= \beta_2 v_{t-1} + (1 - \beta_2) g_t^2\\
\hat{v}_t &= \text{max}(\hat{v}_{t-1}, v_t) \\
\theta_{t+1} &= \theta_{t} - \dfrac{\eta}{\sqrt{\hat{v}_t} + \epsilon} m_t
\end{split}
\end{align}
\)
The authors observe improved performance compared to Adam on small datasets and on CIFAR-10.
Tuning the learning rate
In many cases, it is not our models that require improvement and tuning, but our hyperparameters. Recent examples for language modelling demonstrate that tuning LSTM parameters (Melis et al., 2017) [9] and regularization parameters (Merity et al., 2017) [10] can yield state-of-the-art results compared to more complex models.
An important hyperparameter for optimization in Deep Learning is the learning rate \(\eta\). In fact, SGD has been shown to require a learning rate annealing schedule to converge to a good minimum in the first place. It is often thought that adaptive learning rate methods such as Adam are more robust to different learning rates, as they update the learning rate themselves. Even for these methods, however, there can be a large difference between a good and the optimal learning rate (psst... it's \(3e-4\)).
Zhang et al. (2017) [11] show that SGD with a tuned learning rate annealing schedule and momentum parameter is not only competitive with Adam, but also converges faster. On the other hand, while we might think that the adaptivity of Adam's learning rates might mimic learning rate annealing, an explicit annealing schedule can still be beneficial: If we add SGD-style learning rate annealing to Adam, it converges faster and outperforms SGD on Machine Translation (Denkowski and Neubig, 2017) [12].
In fact, learning rate annealing schedule engineering seems to be the new feature engineering as we can often find highly-tuned learning rate annealing schedules that improve the final convergence behaviour of our model. An interesting example of this is Vaswani et al. (2017) [13]. While it is usual to see a model's hyperparameters being subjected to large-scale hyperparameter optimization, it is interesting to see a learning rate annealing schedule as the focus of the same attention to detail: The authors use Adam with \(\beta_1=0.9\), a non-default \(\beta_2=0.98\), \(\epsilon = 10^{-9}\), and arguably one of the most elaborate annealing schedules for the learning rate \(\eta\):
\(\eta = d_\text{model}^{-0.5} \cdot \min(step\text{_}num^{-0.5}, step\text{_}num \cdot warmup\text{_}steps^{-1.5}) \)
where \(d_\text{model}\) is the number of parameters of the model and \(warmup\text{_}steps = 4000\).
Another recent paper by Smith et al. (2017) [14] demonstrates an interesting connection between the learning rate and the batch size, two hyperparameters that are typically thought to be independent of each other: They show that decaying the learning rate is equivalent to increasing the batch size, while the latter allows for increased parallelism. Conversely, we can reduce the number of model updates and thus speed up training by increasing the learning rate and scaling the batch size. This has ramifications for large-scale Deep Learning, which can now repurpose existing training schedules with no hyperparameter tuning.
Warm restarts
SGD with restarts
Another effective recent development is SGDR (Loshchilov and Hutter, 2017) [15], an SGD alternative that uses warm restarts instead of learning rate annealing. In each restart, the learning rate is initialized to some value and is scheduled to decrease. Importantly, the restart is warm as the optimization does not start from scratch but from the parameters to which the model converged during the last step. The key factor is that the learning rate is decreased with an aggressive cosine annealing schedule, which rapidly lowers the learning rate and looks like the following:
\(\eta_t = \eta_{min}^i + \dfrac{1}{2}(\eta_{max}^i - \eta_{min}^i)(1 + \text{cos}(\dfrac{T_{cur}}{T_i}\pi)) \)
where \(\eta_{min}^i\) and \(\eta_{max}^i\) are ranges for the learning rate during the \(i\)-th run, \(T_{cur}\) indicates how many epochs passed since the last restart, and \(T_i\) specifies the epoch of the next restart. The warm restart schedules for \(T_i=50\), \(T_i=100\), and \(T_i=200\) compared with regular learning rate annealing are shown in Figure 1.

The high initial learning rate after a restart is used to essentially catapult the parameters out of the minimum to which they previously converged and to a different area of the loss surface. The aggressive annealing then enables the model to rapidly converge to a new and better solution. The authors empirically find that SGD with warm restarts requires 2 to 4 times fewer epochs than learning rate annealing and achieves comparable or better performance.
Learning rate annealing with warm restarts is also known as cyclical learning rates and has been originally proposed by Smith (2017) [16]. Two more articles by students of fast.ai (which has recently started to teach this method) that discuss warm restarts and cyclical learning rates can be found here and here.
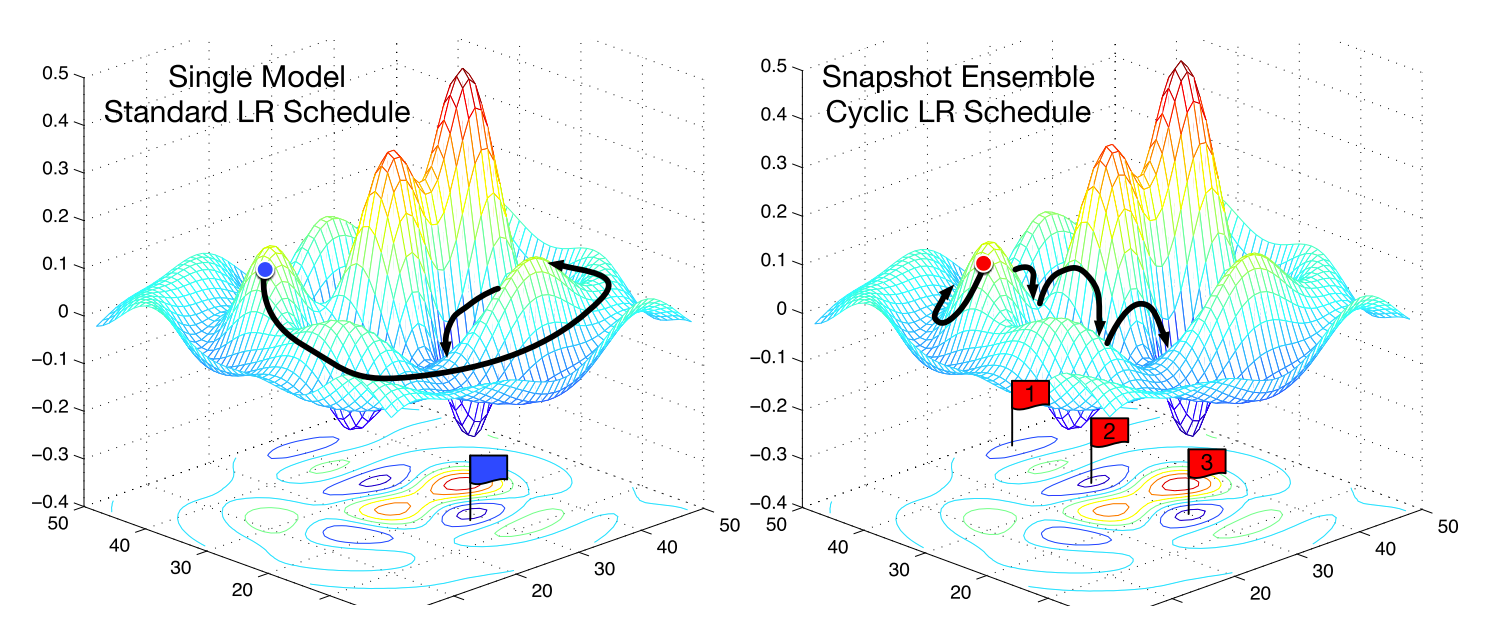
Snapshot ensembles
Snapshot ensembles (Huang et al., 2017) [17] are a clever, recent technique that uses warm restarts to assemble an ensemble essentially for free when training a single model. The method trains a single model until convergence with the cosine annealing schedule that we have seen above. It then saves the model parameters, performs a warm restart, and then repeats these steps \(M\) times. In the end, all saved model snapshots are ensembled. The common SGD optimization behaviour on an error surface compared to the behaviour of snapshot ensembling can be seen in Figure 2.

The success of ensembling in general relies on the diversity of the individual models in the ensemble. Snapshot ensembling thus relies on the cosine annealing schedule's ability to enable the model to converge to a different local optimum after every restart. The authors demonstrate that this holds in practice, achieving state-of-the-art results on CIFAR-10, CIFAR-100, and SVHN.
Adam with restarts
Warm restarts did not work originally with Adam due to its dysfunctional weight decay, which we have seen before. After fixing weight decay, Loshchilov and Hutter (2017) similarly extend Adam to work with warm restarts. They set \(\eta_{min}^i=0\) and \(\eta_{max}^i=1\), which yields:
\(\eta_t = 0.5 + 0.5 \: \text{cos}(\dfrac{T_{cur}}{T_i}\pi))\)
They recommend to start with an initially small \(T_i\) (between \(1%\) and \(10%\) of the total number of epochs) and multiply it by a factor of \(T_{mult}\) (e.g. \(T_{mult}=2\)) at every restart.
Learning to optimize
One of the most interesting papers of last year (and reddit's "Best paper name of 2016" winner) was a paper by Andrychowicz et al. (2016) [18] where they train an LSTM optimizer to provide the updates to the main model during training. Unfortunately, learning a separate LSTM optimizer or even using a pre-trained LSTM optimizer for optimization greatly increases the complexity of model training.
Another very influential learning-to-learn paper from this year uses an LSTM to generate model architectures in a domain-specific language (Zoph and Quoc, 2017) [19]. While the search process requires vast amounts of resources, the discovered architectures can be used as-is to replace their existing counterparts. This search process has proved effective and found architectures that achieve state-of-the-art results on language modeling and results competitive with the state-of-the-art on CIFAR-10.
The same search principle can be applied to any other domain where key processes have been previously defined by hand. One such domain are optimization algorithms for Deep Learning. As we have seen before, optimization algorithms are more similar than they seem: All of them use a combination of an exponential moving average of past gradients (as in momentum) and of an exponential moving average of past squared gradients (as in Adadelta, RMSprop, and Adam) (Ruder, 2016) [20].
Bello et al. (2017) [21] define a domain-specific language that consists of primitives useful for optimization such as these exponential moving averages. They then sample an update rule from the space of possible update rules, use this update rule to train a model, and update the RNN controller based on the performance of the trained model on the test set. The full procedure can be seen in Figure 3.

In particular, they discover two update equations, PowerSign and AddSign. The update equation for PowerSign is the following:
\( \theta_{t+1} = \theta_{t} - \alpha^{f(t)*
\text{sign}(g_t)*\text{sign}(m_t)}*g_t \)
where \(\alpha\) is a hyperparameter that is often set to \(e\) or \(2\), \(f(t)\) is either \(1\) or a decay function that performs linear, cyclical or decay with restarts based on time step \(t\), and \(m_t\) is the moving average of past gradients. The common configuration uses \(\alpha=e\) and no decay. We can observe that the update scales the gradient by \(\alpha^{f(t)}\) or \(1/\alpha^{f(t)}\) depending on whether the direction of the gradient and its moving average agree. This indicates that this momentum-like agreement between past gradients and the current one is a key piece of information for optimizing Deep Learning models.
AddSign in turn is defined as follows:
\( \theta_{t+1} = \theta_{t} - \alpha + f(t) * \text{sign}(g_t) * \text{sign}(m_t)) * g_t\)
with \(\alpha\) often set to \(1\) or \(2\). Similar to the above, this time the update scales \(\alpha + f(t)\) or \(\alpha - f(t)\) again depending on the agreement of the direction of the gradients. The authors show that PowerSign and AddSign outperform Adam, RMSprop, and SGD with momentum on CIFAR-10 and transfer well to other tasks such as ImageNet classification and machine translation.
Understanding generalization
Optimization is closely tied to generalization as the minimum to which a model converges defines how well the model generalizes. Advances in optimization are thus closely correlated with theoretical advances in understanding the generalization behaviour of such minima and more generally of gaining a deeper understanding of generalization in Deep Learning.
However, our understanding of the generalization behaviour of deep neural networks is still very shallow. Recent work showed that the number of possible local minima grows exponentially with the number of parameters (Kawaguchi, 2016) [22]. Given the huge number of parameters of current Deep Learning architectures, it still seems almost magical that such models converge to solutions that generalize well, in particular given that they can completely memorize random inputs (Zhang et al., 2017) [23].
Keskar et al. (2017) [24] identify the sharpness of a minimum as a source for poor generalization: In particular, they show that sharp minima found by batch gradient descent have high generalization error. This makes intuitive sense, as we generally would like our functions to be smooth and a sharp minima indicates a high irregularity in the corresponding error surface. However, more recent work suggests that sharpness may not be such a good indicator after all by showing that local minima that generalize well can be made arbitrarily sharp (Dinh et al., 2017) [25]. A Quora answer by Eric Jang also discusses these articles.
An ICLR 2018 submission demonstrates through a series of ablation analyses that a model's reliance on single directions in activation space, i.e. the activation of single units or feature maps is a good predictor of its generalization performance. They show that this holds across models trained on different datasets and for different degrees of label corruption. They find that dropout does not help to resolve this, while batch normalization discourages single direction reliance.
While these findings indicate that there is still much we do not know in terms of Optimization for Deep Learning, it is important to remember that convergence guarantees and a large body of work exists for convex optimization and that existing ideas and insights can also be applied to non-convex optimization to some extent. The large-scale optimization tutorial at NIPS 2016 provides an excellent overview of more theoretical work in this area (see the slides part 1, part 2, and the video).
Conclusion
I hope that I was able to provide an impression of some of the compelling developments in optimization for Deep Learning over the past year. I've undoubtedly failed to mention many other approaches that are equally important and noteworthy. Please let me know in the comments below what I missed, where I made a mistake or misrepresented a method, or which aspect of optimization for Deep Learning you find particularly exciting or underexplored.
Hacker News
You can find the discussion of this post on HN here.
Robbins, H., & Monro, S. (1951). A stochastic approximation method. The annals of mathematical statistics, 400-407. ↩︎
Kingma, D. P., & Ba, J. L. (2015). Adam: a Method for Stochastic Optimization. International Conference on Learning Representations. ↩︎
Huang, G., Liu, Z., Weinberger, K. Q., & van der Maaten, L. (2017). Densely Connected Convolutional Networks. In Proceedings of CVPR 2017. ↩︎
Wu, Y., Schuster, M., Chen, Z., Le, Q. V, Norouzi, M., Macherey, W., … Dean, J. (2016). Google’s Neural Machine Translation System: Bridging the Gap between Human and Machine Translation. arXiv Preprint arXiv:1609.08144. ↩︎
Wilson, A. C., Roelofs, R., Stern, M., Srebro, N., & Recht, B. (2017). The Marginal Value of Adaptive Gradient Methods in Machine Learning. arXiv Preprint arXiv:1705.08292. Retrieved from http://arxiv.org/abs/1705.08292 ↩︎
Loshchilov, I., & Hutter, F. (2017). Fixing Weight Decay Regularization in Adam. arXiv Preprint arXi1711.05101. Retrieved from http://arxiv.org/abs/1711.05101 ↩︎
Dozat, T., & Manning, C. D. (2017). Deep Biaffine Attention for Neural Dependency Parsing. In ICLR 2017. Retrieved from http://arxiv.org/abs/1611.01734 ↩︎
Laine, S., & Aila, T. (2017). Temporal Ensembling for Semi-Supervised Learning. In Proceedings of ICLR 2017. ↩︎
Melis, G., Dyer, C., & Blunsom, P. (2017). On the State of the Art of Evaluation in Neural Language Models. In arXiv preprint arXiv:1707.05589. ↩︎
Merity, S., Shirish Keskar, N., & Socher, R. (2017). Regularizing and Optimizing LSTM Language Models. arXiv Preprint arXiv:1708.02182. Retrieved from https://arxiv.org/pdf/1708.02182.pdf ↩︎
Zhang, J., Mitliagkas, I., & Ré, C. (2017). YellowFin and the Art of Momentum Tuning. In arXiv preprint arXiv:1706.03471. ↩︎
Denkowski, M., & Neubig, G. (2017). Stronger Baselines for Trustable Results in Neural Machine Translation. In Workshop on Neural Machine Translation (WNMT). Retrieved from https://arxiv.org/abs/1706.09733 ↩︎
Vaswani, A., Shazeer, N., Parmar, N., Uszkoreit, J., Jones, L., Gomez, A. N., … Polosukhin, I. (2017). Attention Is All You Need. In Advances in Neural Information Processing Systems. ↩︎
Smith, S. L., Kindermans, P.-J., & Le, Q. V. (2017). Don’t Decay the Learning Rate, Increase the Batch Size. In arXiv preprint arXiv:1711.00489. Retrieved from http://arxiv.org/abs/1711.00489 ↩︎
Loshchilov, I., & Hutter, F. (2017). SGDR: Stochastic Gradient Descent with Warm Restarts. In Proceedings of ICLR 2017. https://doi.org/10.1002/fut ↩︎
Smith, Leslie N. "Cyclical learning rates for training neural networks." In Applications of Computer Vision (WACV), 2017 IEEE Winter Conference on, pp. 464-472. IEEE, 2017. ↩︎
Huang, G., Li, Y., Pleiss, G., Liu, Z., Hopcroft, J. E., & Weinberger, K. Q. (2017). Snapshot Ensembles: Train 1, get M for free. In Proceedings of ICLR 2017. ↩︎
Andrychowicz, M., Denil, M., Gomez, S., Hoffman, M. W., Pfau, D., Schaul, T., & de Freitas, N. (2016). Learning to learn by gradient descent by gradient descent. In Advances in Neural Information Processing Systems. Retrieved from http://arxiv.org/abs/1606.04474 ↩︎
Zoph, B., & Le, Q. V. (2017). Neural Architecture Search with Reinforcement Learning. In ICLR 2017. ↩︎
Ruder, S. (2016). An overview of gradient descent optimization algorithms. arXiv Preprint arXiv:1609.04747. ↩︎
Bello, I., Zoph, B., Vasudevan, V., & Le, Q. V. (2017). Neural Optimizer Search with Reinforcement Learning. In Proceedings of the 34th International Conference on Machine Learning. ↩︎
Kawaguchi, K. (2016). Deep Learning without Poor Local Minima. In Advances in Neural Information Processing Systems 29 (NIPS 2016). Retrieved from http://arxiv.org/abs/1605.07110 ↩︎
Zhang, C., Bengio, S., Hardt, M., Recht, B., & Vinyals, O. (2017). Understanding deep learning requires rethinking generalization. In Proceedings of ICLR 2017. ↩︎
Keskar, N. S., Mudigere, D., Nocedal, J., Smelyanskiy, M., & Tang, P. T. P. (2017). On Large-Batch Training for Deep Learning: Generalization Gap and Sharp Minima. In Proceedings of ICLR 2017. Retrieved from http://arxiv.org/abs/1609.04836 ↩︎
Dinh, L., Pascanu, R., Bengio, S., & Bengio, Y. (2017). Sharp Minima Can Generalize For Deep Nets. In Proceedings of the 34th International Conference on Machine Learning. ↩︎