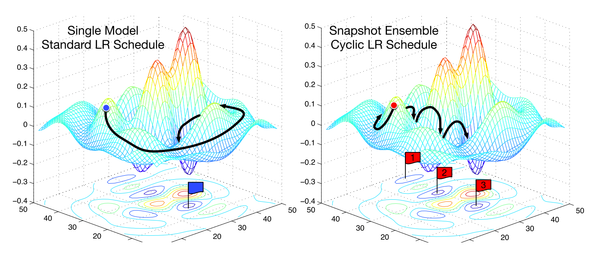
optimization Optimization for Deep Learning Highlights in 2017 Different gradient descent optimization algorithms have been proposed in recent years but Adam is still most commonly used. This post discusses the most exciting highlights and most promising recent approaches that may shape the way we will optimize our models in the future.
optimization An overview of gradient descent optimization algorithms Gradient descent is the preferred way to optimize neural networks and many other machine learning algorithms but is often used as a black box. This post explores how many of the most popular gradient-based optimization algorithms such as Momentum, Adagrad, and Adam actually work.