Unsupervised Cross-lingual Representation Learning
This post expands on the ACL 2019 tutorial on Unsupervised Cross-lingual Representation Learning. It highlights key insights and takeaways and provides updates based on recent work, particularly unsupervised deep multilingual models.

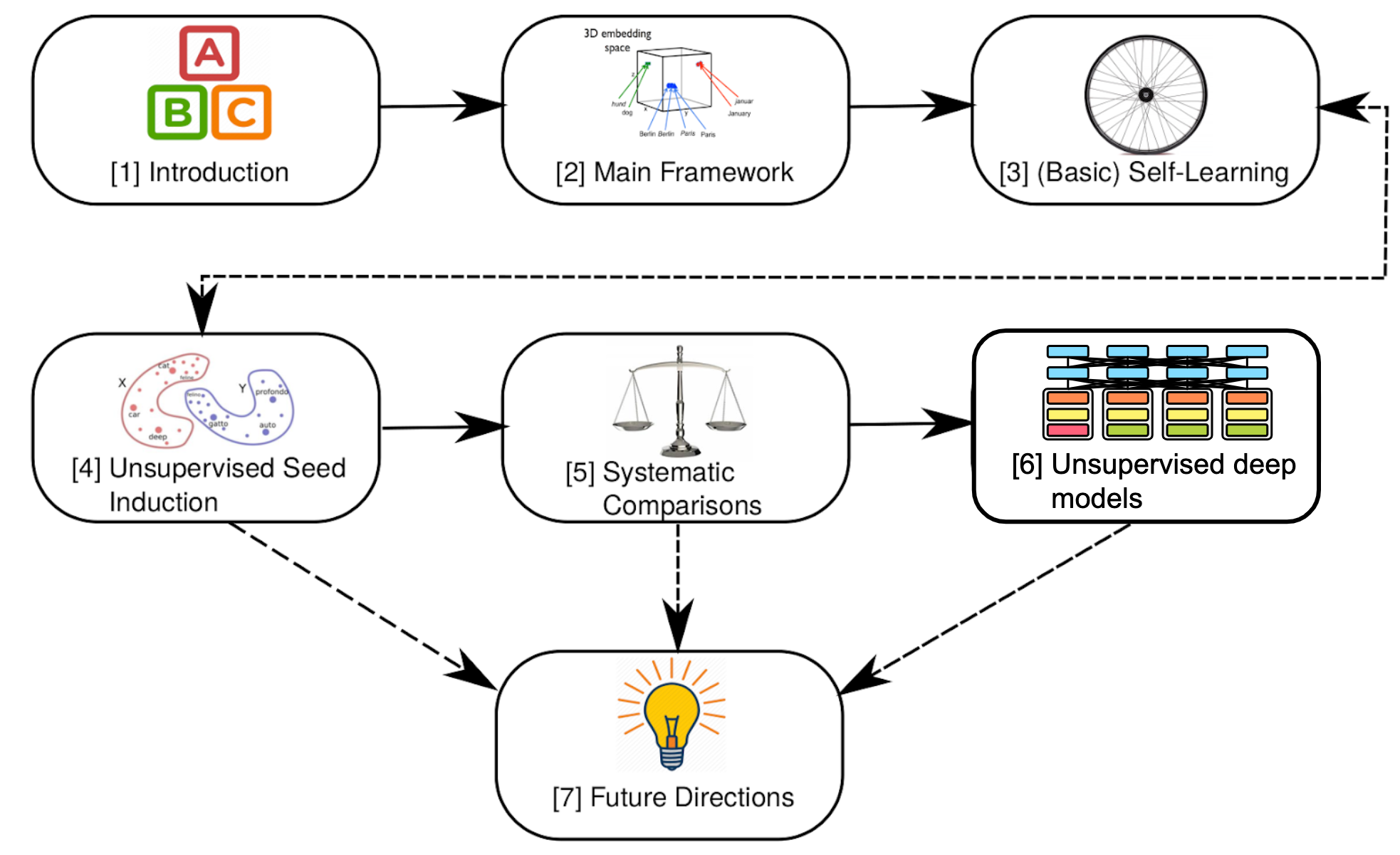
This post expands on the ACL 2019 tutorial on Unsupervised Cross-lingual Representation Learning.
The tutorial was organised by Ivan Vulić, Anders Søgaard, and me. In this post, I highlight key insights and takeaways and provide additional context and updates based on recent work. In particular, I cover unsupervised deep multilingual models such as multilingual BERT. You can see the structure of this post below:
The slides of the tutorial are available online.
Introduction
Cross-lingual representation learning can be seen as an instance of transfer learning, similar to domain adaptation. The domains in this case are different languages.
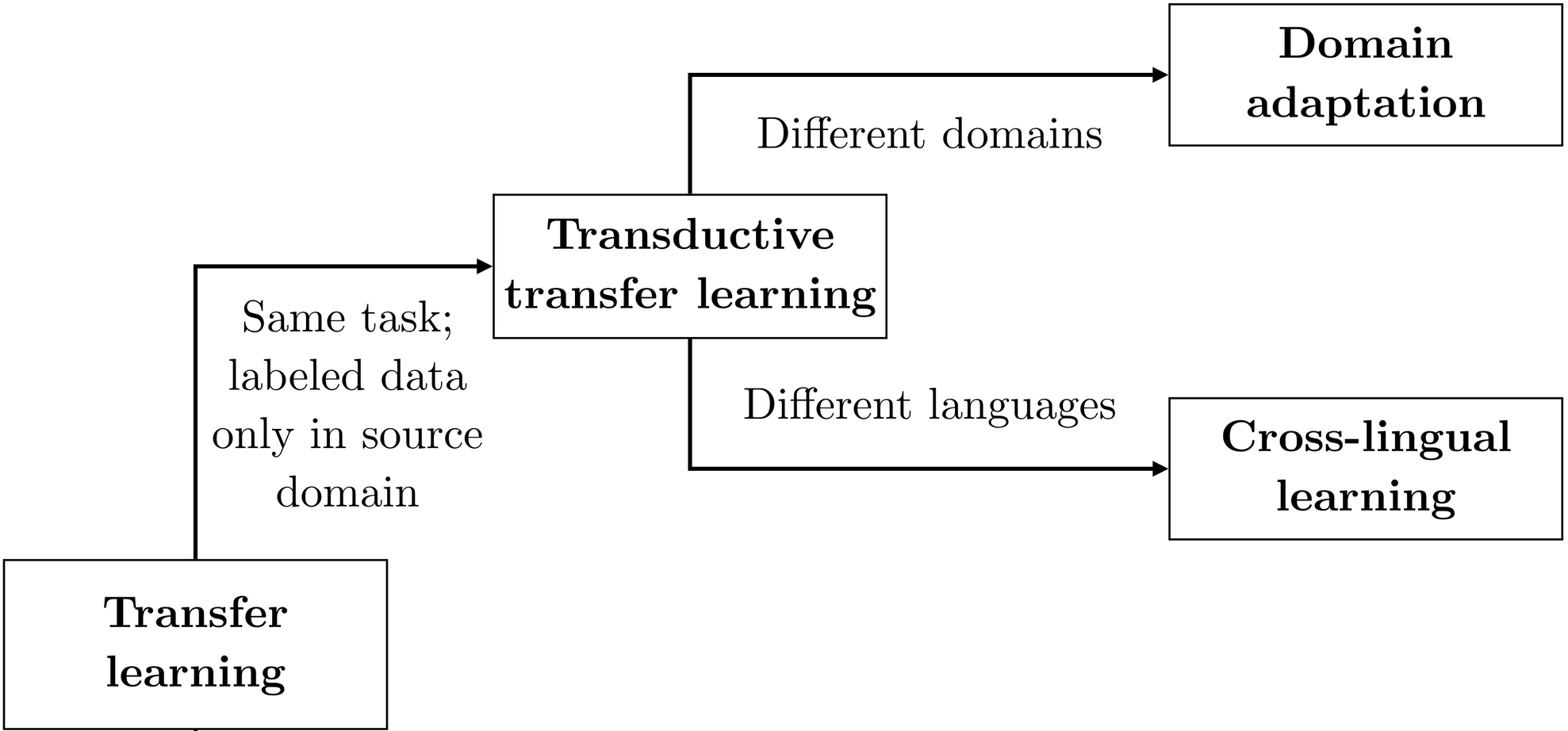
Methods from domain adaptation have also been applied to cross-lingual transfer (Prettenhofer & Stein, 2011, Wan et al., 2011). For a clearer distinction between domain adaptation and cross-lingual learning, have a look at this section.
Viewing cross-lingual learning as a form of transfer learning can help us understand why it might be useful and when it might fail:
- Transfer learning is useful whenever the scenarios between which we transfer share some underlying structure. In a similar vein, languages share commonalities on many levels—from loanwords and cognates on the lexical level, to the structure of sentences on the syntactic level, to the meaning of words on the semantic level. Learning about the structure of one language may therefore help us do better when learning a second language.
- Transfer learning struggles when the source and target settings are too different. Similarly, it is harder to transfer between languages that are dissimilar (e.g. that have different typological features in the World Atlas of Language Structures).
Similar to the broader transfer learning landscape, much of the work on cross-lingual learning over the last years has focused on learning representations of words. While there have been approaches that learn sentence-level representations, only recently are we witnessing the emergence of deep multilingual models. Have a look at this survey for an overview of the history of cross-lingual models. For more on transfer learning, check out this recent post. Cross-lingual learning might be useful—but why should we care about applying NLP to other languages in the first place?
The Digital Language Divide
The language you speak shapes your experience of the world. This is known as the Sapir-Whorf hypothesis and is contested. On the other hand, it is factual that the language you speak shapes your experience of the world online. What language you speak determines your access to information, education, and even human connections. In other words, even though we think of the Internet as being open to anyone, there is a digital language divide between dominant languages (mostly from the western world) and others.
As NLP technologies are becoming more commonplace, this divide extends to the technological level: At best, this means that non-English language speakers do not benefit from the latest features of digital assistants; at worst, algorithms are biased against or discriminate against speakers of non-English languages—we can see occurrences of this already today. To ensure that non-English language speakers are not left behind and at the same time to offset the existing imbalance, we need to apply our models to non-English languages.
The NLP Resource Hierarchy
In current machine learning, the amount of available training data is the main factor that influences an algorithm's performance. Data that is useful for current NLP models can range from unlabelled data in the form of documents online or articles on Wikipedia, labelled data in the form of large curated datasets, or parallel corpora used in machine translation.
We can roughly differentiate between languages with many and languages with few data resources in a hierarchy, which can be seen below.

This approximately corresponds with a language's presence online. Note that many languages cannot be assigned clearly to a single level of the hierarchy. Some languages with few speakers such as Aragonese or Waray-Waray have a disproportionally large Wikipedia, while for others such as Latvian parallel data is available due to their status as an official language. On the other hand, many languages with tens of millions of speakers such as Xhosa and Zulu have barely more than 1,000 Wikipedia articles.
Nevertheless, the existence of such a hierarchy highlights why unsupervised cross-lingual representation learning is promising: for most of the world's languages, no labelled data is available and creating labelled data is expensive as native speakers are under-represented online. In order to train models for such languages, we need to make use of unlabelled data and transfer learning from high-resource languages.
Cross-lingual Representations
Whereas in the past it was necessary to learn language-specific models for every language and preprocessing and features needed to be applied to every language in isolation, cross-lingual representation learning enables us to apply the transfer learning formula of pretraining and adaptation across languages.
In this context, we will talk about a (high-resource) source language \(L_1\) where unlabelled data and labelled data for a particular task are available, and a (low-resource) target language \(L_2\) where only unlabelled data is available. For cross-lingual transfer learning, we add one additional step to the transfer learning recipe above:
- Pretraining: Learn cross-lingual representations that are shared across languages. This is what the rest of this post is about.
- Adaptation: Adapt the model to the labelled data of the desired task in \(L_1\) by learning task-specific parameters on top of the cross-lingual representations. The cross-lingual parameters are often kept fixed (this is the same as feature extraction). As the task-specific parameters are learned on top of cross-lingual ones, they are expected to transfer to the other language.
- Zero-shot transfer: The model, which captures cross-lingual information, can be applied directly to perform inference on data of the target language.
If labelled data in the target language is also available, then the model can be fine-tuned jointly on both languages in Step 2.
Throughout this post, I will focus on approaches that learn cross-lingual representations as the means for transferring across languages. Depending on the task, there are other ways of transferring information across languages such as by domain adaptation (as seen above), annotation projection (Padó & Lapata, 2009; Ni et al., 2017; Nicolai & Yarowsky, 2019), distant supervision (Plank & Agić, 2018) or machine translation (MT; Zhou et al., 2016; Eger et al., 2018).
Why not Machine Translation?
In light of the recent success of massively multilingual and unsupervised machine translation (Lample et al., 2018; Artetxe et al., 2019), an obvious question is why we would not just use MT to translate the training data in our source language to the target language and train a model on the translated data—or translate the test set and apply our source model directly to it, which often works better in practice. If an MT system is available, this can be a strong baseline (Conneau et al., 2018) and unsupervised MT in particular can be useful for low-resource languages (Lample et al., 2018).
However, an MT system for the desired language pair may not be easily available and can be expensive to train. In addition, models trained on machine-translated data often underperform state-of-the-art deep multilingual models. MT struggles with distant language pairs and domain mismatches (Guzmán et al., 2019). It is also not a fit for all tasks; the performance of translation-based models for question answering tasks depends heavily on the translation quality of named entities (Liu et al., 2019). For sequence labelling tasks, MT requires projecting annotations across languages, itself a difficult problem (Akbik & Vollgraf, 2018).
In general, however, MT and the methods described in this post are not at odds but complementary. Cross-lingual word representations are used to initialise unsupervised MT (Artetxe et al., 2019) and cross-lingual representations have been shown to improve neural MT performance (Lample & Conneau, 2019). Techniques from MT such as word alignment have also inspired much work in cross-lingual representation learning (Ruder et al., 2019). Finally, a multilingual model benefits from being fine-tuned on translations of the labelled data in multiple languages (Conneau et al., 2019).
Main Framework
We now discuss how to learn unsupervised representations, starting at the word level. The main framework for learning cross-lingual word embeddings (CLWEs) consists of mapping-based or post-hoc alignment approaches. For an overview of other approaches, have a look at our survey or book on the topic.
Mapping-based methods are currently the preferred approach due to their ease and efficiency of use and conceptual simplicity. They only require monolingual word embeddings trained in each language and then simply learn a linear projection that maps between the embedding spaces. The general framework can be seen in the Figure below.
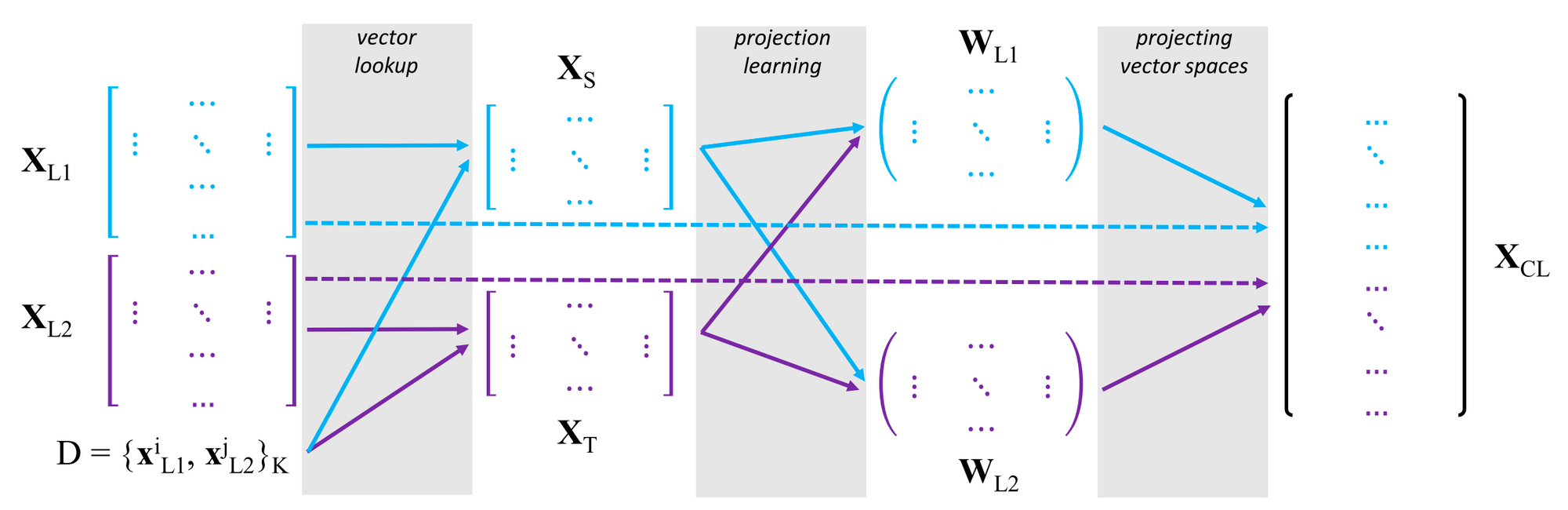
Given monolingual embedding spaces \(\mathbf{X}_{L_1} = \{\mathbf{x}^i_{L_1} \}^{|V_{L_1}|}_{i=1} \) and \(\mathbf{X}_{L_2} = \{\mathbf{x}^j_{L_2} \}^{|V_{L_2}|}_{j=1} \) in two languages where \(\mathbf{x}\) is a word embedding and \(|V|\) is the size of the vocabulary, we perform the following steps (Glavaš et al., 2019):
- Construct a seed translation dictionary. The dictionary \(D = \{w^i_{L_1}, w^j_{L_2} \}^K\) contains \(K\) pairs of words and their translations.
- Create word-aligned monolingual subspaces. We create subspaces \(\mathbf{X}_S = \{\mathbf{x}i_{L_1}\}K_{i=1} \) and \(\mathbf{X}_T = \{\mathbf{x}j_{L_2}\}K_{j=1} \) where \(\mathbf{X}_S \in \mathbb{R}^{K \times d}\) and \(\mathbf{X}_T \in \mathbb{R}^{K \times d}\) where \(d\) is the dimensionality of the word embeddings. We do this simply by looking up the vectors of the words and their translations in the monolingual embedding spaces, \( \{w^i_{L_1} \} \) from \(\mathbf{X}_{L_1}\) and \( \{w^j_{L_2} \} \) from \(\mathbf{X}_{L_2}\) respectively.
- Learn a mapping between the subspaces to a common space. Specifically, we project the matrices \(\mathbf{X}_S\) and \(\mathbf{X}_T\) into a common space \(\mathbf{X}_{CL}\). In the general setting, we learn two projection matrices \(\mathbf{W}_{L_1} \in \mathbb{R}^{d \times d} \) and \(\mathbf{W}_{L_2} \in \mathbb{R}^{d \times d}\) to project \(\mathbf{X}_{L_1}\) and \(\mathbf{X}_{L_2}\) respectively to the shared space.
We often treat one of the monolingual spaces \(\mathbf{X}_{L_1}\) (typically the English space) as the cross-lingual space \(\mathbf{X}_{CL}\) and only learn a mapping \(\mathbf{W}_{L_2}\) from \(\mathbf{X}_{L_2}\) to this space. The standard approach for learning this mapping is to minimise the Euclidean distance between the representations of words \( \mathbf{X}_T \) and their projected translations \( \mathbf{X}_S\mathbf{W} \) in the dictionary \(D\) (Mikolov et al., 2013):
\(\mathbf{W}_{L_2} = \arg \min_{\mathbf{W}} \| \mathbf{X}_S\mathbf{W} - \mathbf{X}_T \|_2 \)
After having learned this mapping, we can now project a word embedding \(\mathbf{x}_{L_2}\) from \(\mathbf{X}_{L_2}\) simply as \(\mathbf{W}_{L_2} \mathbf{x}_{L_2} \) to the space of \(\ \mathbf{X}_{L_1}\). We can see how this mapping looks like geometrically below.
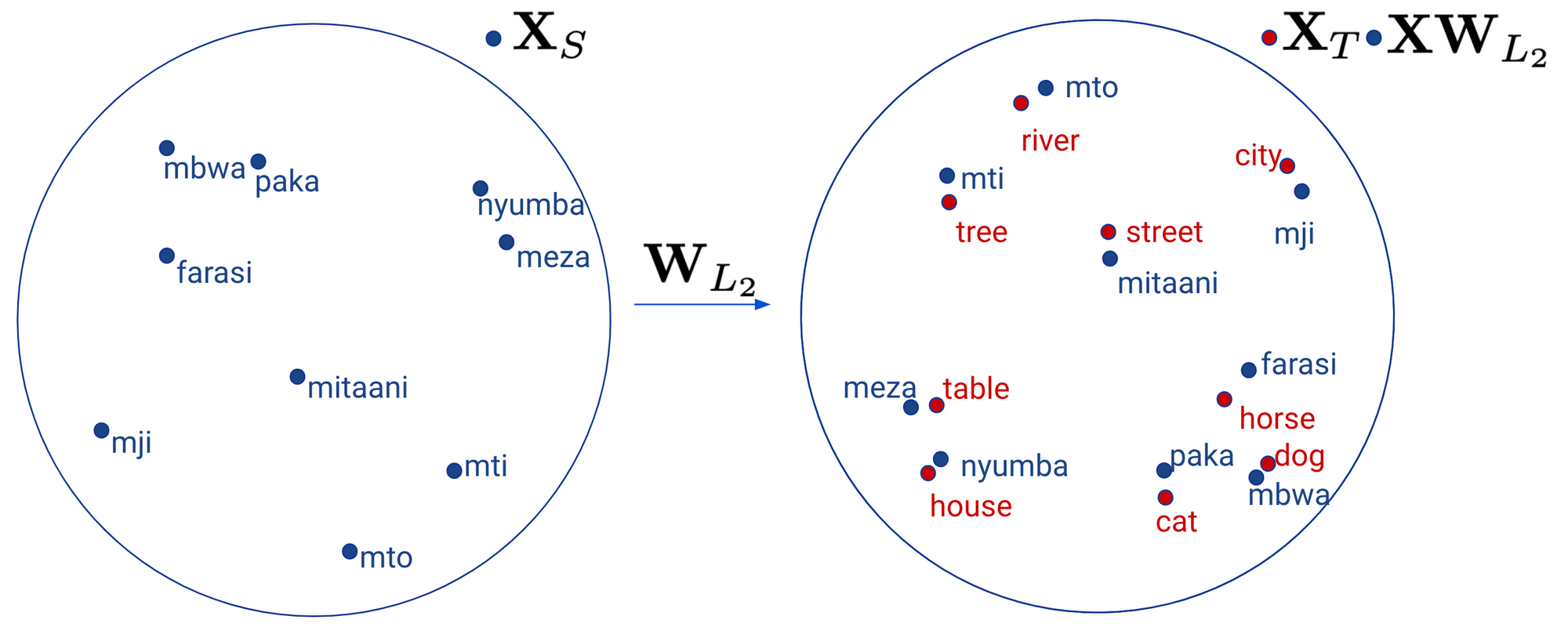
More complex mappings (such as with a deep neural network) have been observed to lead to poorer performance (Mikolov et al., 2013). Better word translation results can be achieved when \(\mathbf{W}_{L_2}\) is constrained to be orthogonal (Xing et al., 2015, Artetxe et al., 2016). Intuitively, this ensures that when \(\mathbf{W}_{L_2}\) vectors are projected to the \(\mathbf{X}_{CL}\) space that the structure of the monolingual embedding space is preserved. If \(\mathbf{W}_{L_2}\) is orthogonal, then the optimisation problem is known as the so-called Procrustes problem (Schönemann, 1966), which has a closed form solution:
\(
\begin{align}
\begin{split}
\mathbf{W}_{L_2} & = \mathbf{UV}^\top, \text{with} \\
\mathbf{U \Sigma V}^\top & = SVD(\mathbf{X}_T \mathbf{X}_S{}^\top)
\end{split}
\end{align}
\)
Almost all projection-based methods, whether they are supervised or unsupervised, solve the Procrustes problem to learn a linear mapping in Step 3. The main part where they differ is in how they obtain the initial seed dictionary in Step 1. Recent supervised approaches (Artetxe et al., 2017) have been shown to achieve reasonable performance using dictionaries of only 25-40 translation pairs. The main idea that enables learning from such limited supervision is bootstrapping or self-learning.
Self-learning
Starting from a seed dictionary, recent approaches employ a self-learning procedure (Artetxe et al., 2017), which can be seen below.
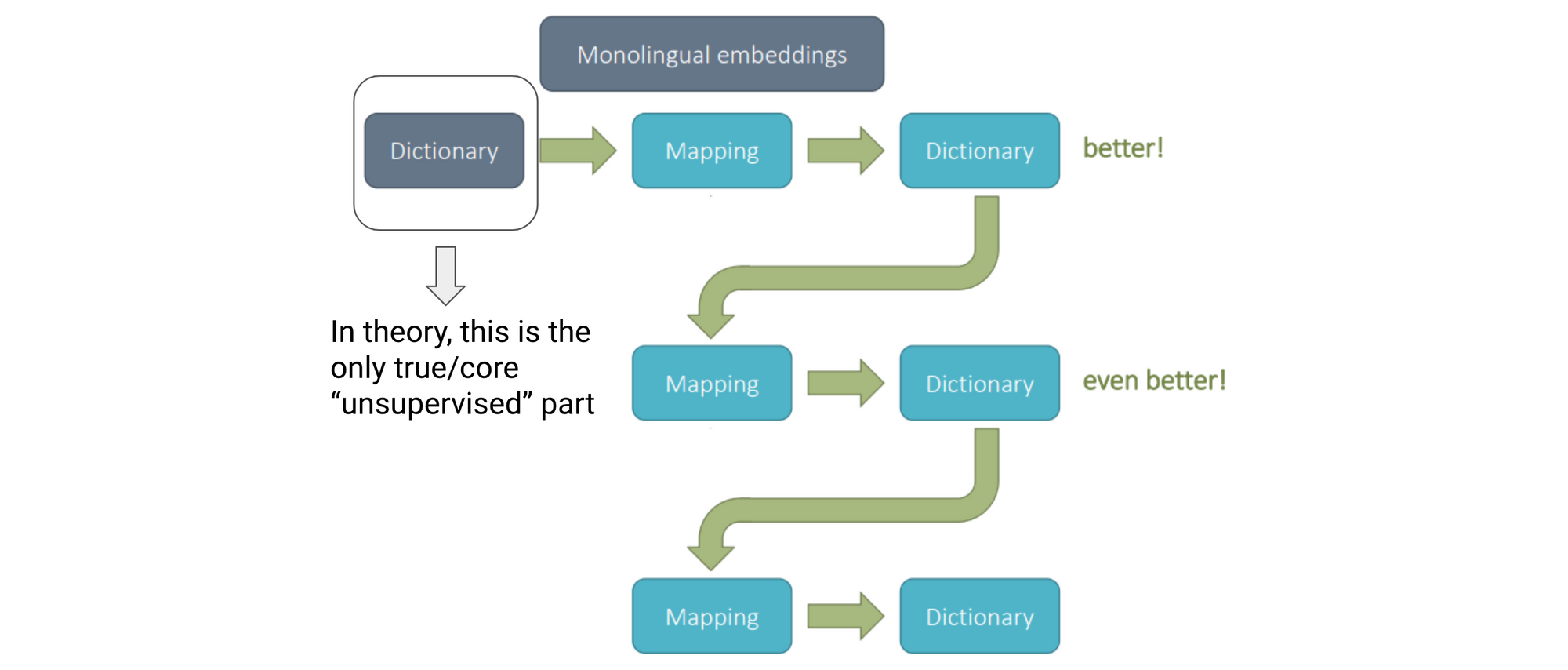
We learn an initial mapping based on the seed dictionary and use this mapping to project \(\mathbf{X}_{L_2}\) vectors to the target space \(\mathbf{X}_{CL}\). In this cross-lingual space, \(L_1\) words should be close to their translations in \(L_2\). We can now use the \(L_1\) words and their nearest neighbours in \(L_2\) to build our new dictionary. In practice, people often only consider frequent words and mutual nearest neighbours, i.e. words that are nearest neighbours from both \(L_1\) and \(L_2\) directions (Vulić et al., 2016; Lample et al., 2018).
The framework that is typically used in practice consists of additional components (Artetxe et al., 2018) that can be seen in the Figure below.
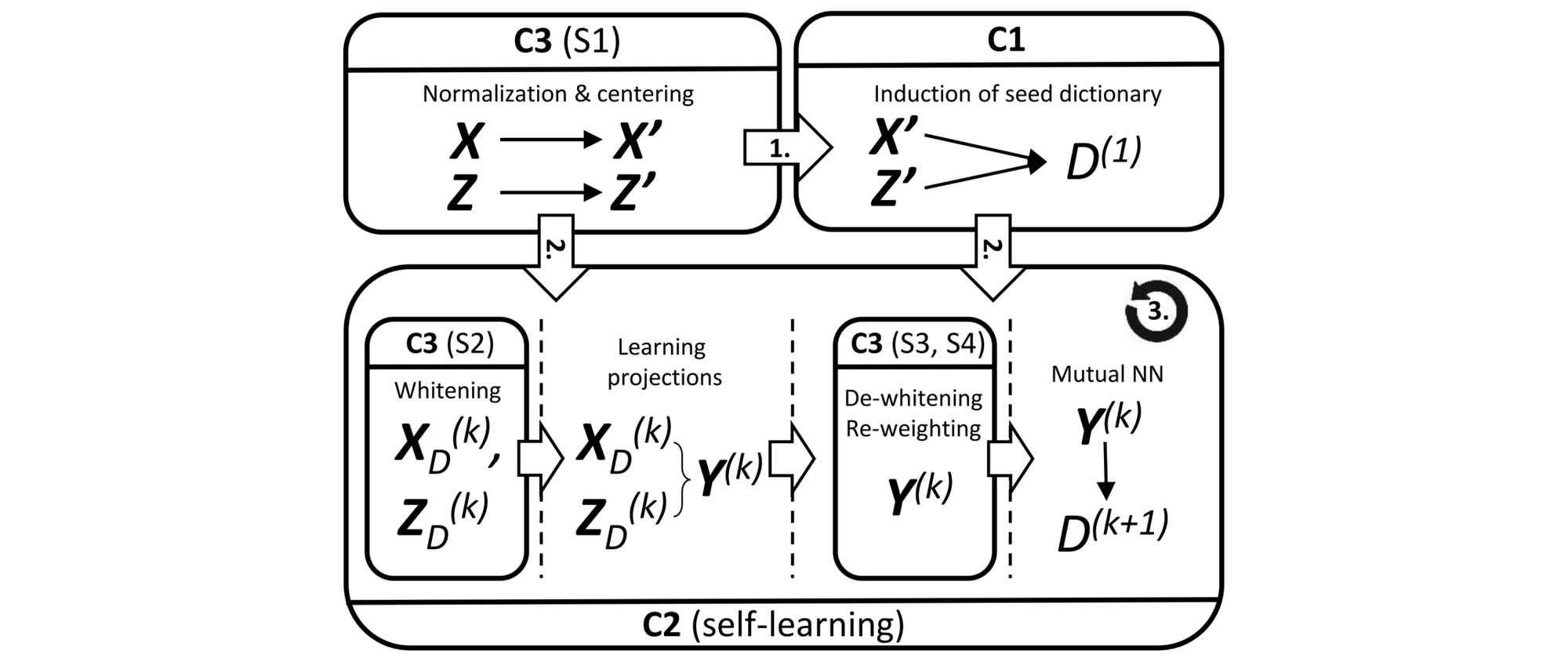
In particular, beyond the induction of the initial seed dictionary (C1), the learning of the projections, and the self-learning (C3), there are several pre- and post-processing steps that are often used in practice. You can have a look at the slides or refer to Artetxe et al. (2018) for an overview.
Unsupervised Seed Induction
Unsupervised seed induction aims to find a good initial dictionary that we can use to bootstrap the self-learning loop. We can differentiate approaches based on whether they learn an initial mapping by minimising the distance between the \(\mathbf{X}_{L_1}\) or \(\mathbf{X}_{L_2}\) spaces—often with an adversarial component—or whether they rely on a non-adversarial approach.
Adversarial approaches
Adversarial approaches are inspired by generative adversarial networks (GANs). The generator is parameterised by our projection matrix \(\mathbf{W}_{L_2}\) while the discriminator is a separate neural network that tries to discriminate between true embeddings from \(\mathbf{X}_{L_2}\) and projected embeddings \(\mathbf{W}_{L_1} \mathbf{X}_{L_1}\) as can be seen below.
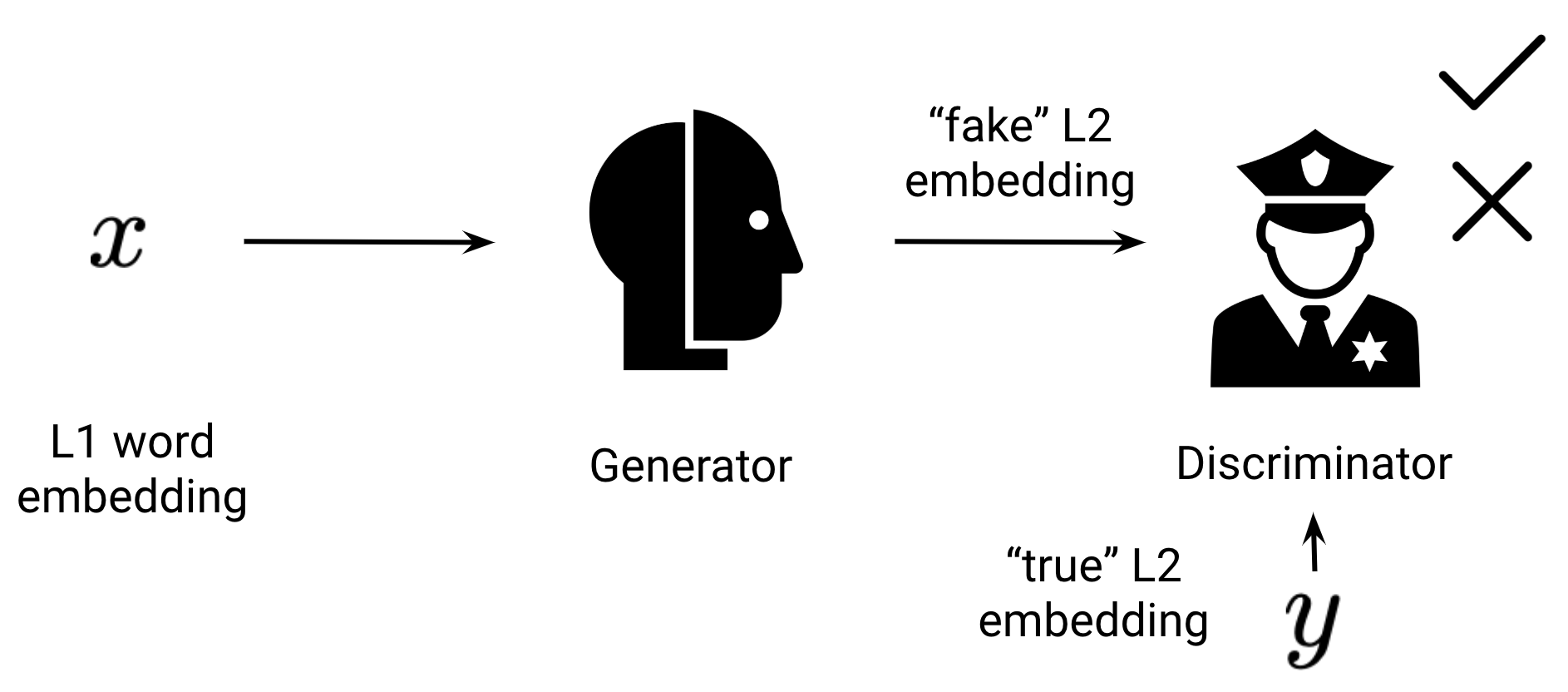
In order to fool the discriminator, the generator has to transform \(\mathbf{X}_{L_1}\) in such a way that it matches the distribution of \(\mathbf{X}_{L_2}\). The underlying hypothesis is that the transformation that makes the distributions as similar as possible also puts words close to their translations in the cross-lingual space \(\mathbf{X}_{CL}\). GANs can be notoriously brittle. The first approach that worked more robustly in certain settings was proposed by Conneau et al. (2018).
Other ways have been proposed to minimise the distance between the distributions of \(\mathbf{X}_{L_1}\) and \(\mathbf{X}_{L_2}\) that leverage Wasserstein GANs, Earth Mover's distance, and optimal transport. For more details about these approaches and their connections, have a look at the corresponding slides.
Weak supervision and second-order similarity
Another strategy for obtaining a seed lexicon is through the use of heuristics. If the writing systems of two languages share the same alphabet, then there will be many words that are spelled the same in both languages, many of them named entities such as "New York" and "Barack Obama". A list of pairs of such identically spelled words can be used as a weakly supervised seed dictionary (Søgaard et al., 2018). Even if languages do not share alphabets, many languages still use Arabic numerals, which can be used as a seed dictionary (Artetxe et al., 2017).
Such a weakly supervised seed dictionary is available for most language pairs and works surprisingly well, often outperforming purely unsupervised approaches. Intuitively, despite being noisy, a dictionary consisting of identically spelled words provides a sufficient number of anchor points for learning an initial mapping.
Still, it would be useful to have a seed dictionary that is independent of a language's writing system. Rather than requiring that translations should be similar (e.g. spelled the same), we can go one step further and require that translations should be similar to other words across languages in the same way (Artetxe et al. 2018). In other words, the similarity distributions of translations within each language should be similar.
Specifically, if we calculate the cosine similarity of one word with all other words in the same language, sort the values, and normalise, we obtain the following distributions for "two", "due" and "cane":
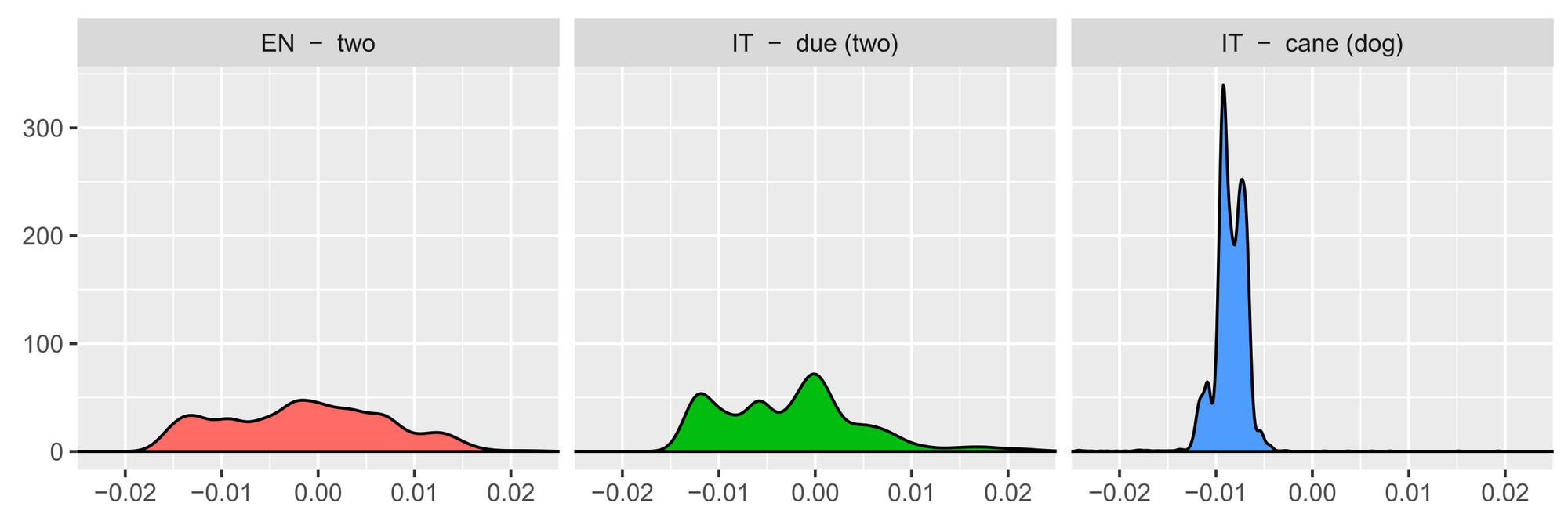
The intralingual similarity distributions of translations such as "two" and "due" should be more similar compared to other words such as "cane". Based on this insight, we can use the nearest neighbours of our similarity distributions across languages as the initial dictionary. This notion of second-order similarity (the similarity of similarity distributions) is a powerful concept and is also leveraged by distance metrics such as the Gromov-Wasserstein distance.
Systematic Comparisons
Unsupervised cross-lingual word embeddings are theoretically interesting. They can teach us how to better leverage monolingual data across languages. We can also use them to learn more about how different languages relate to each other.
However, supervision in the form of translation pairs is available for many languages and weak supervision is readily available. Unsupervised methods are thus only of practical interest if they are able to outperform to their supervised counterparts.
Initial papers claimed that unsupervised methods are indeed competitive and even outperform the basic supervised Procrustes method. Recent studies, however, control for the additional components in the framework and compare unsupervised and supervised methods on equal footing. The picture that has emerged is that current unsupervised methods generally underperform supervised methods with 500-1,000 seed translation pairs (Glavaš et al., 2019; Vulić et al., 2019) as can be seen in the Figure below.
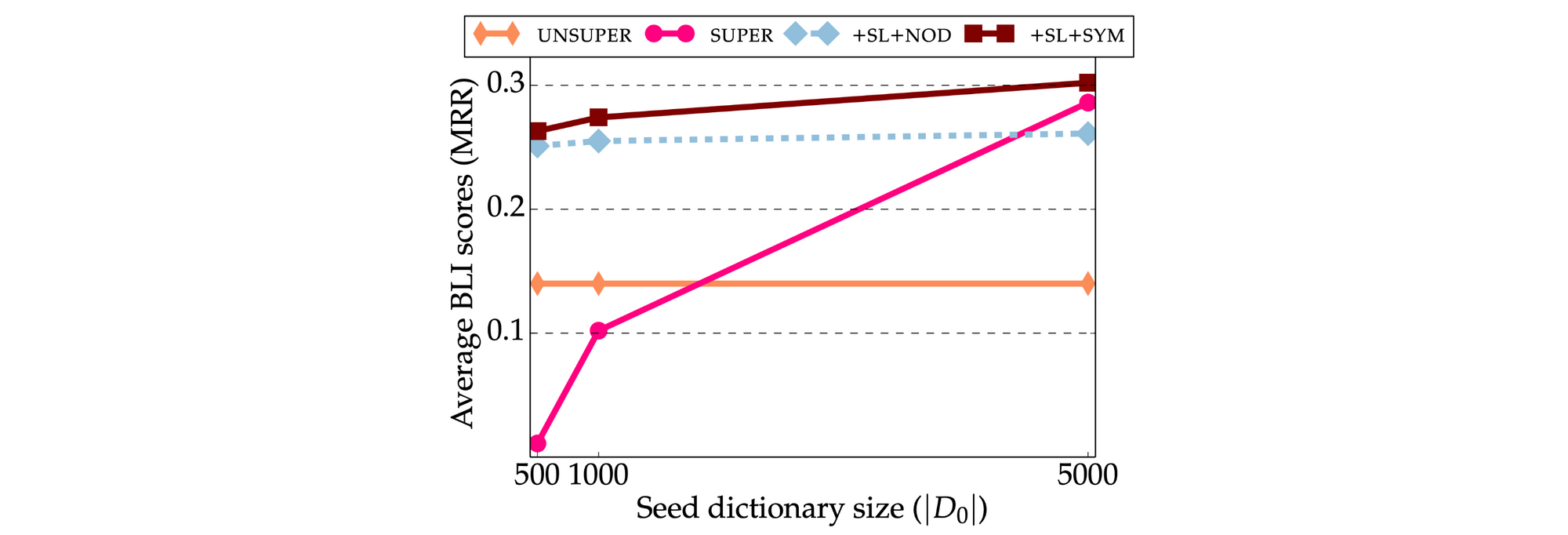
Moreover, even the most robust unsupervised mapping-based approaches fail for many language pairs. This has to do with the topology of the monolingual embedding spaces: Unsupervised methods rely on the assumption that the embedding spaces are approximately isomorphic, i.e. that they have similar structure (Søgaard et al., 2018). If this is not the case, then the unsupervised seed induction step fails.
The structure of embedding spaces can be different if embeddings belong to dissimilar languages but also if they were trained on different domains or using different algorithms (Søgaard et al., 2018; Hartmann et al., 2018). Different methods such as a combination of several independent linear maps (Nakashole, 2018), iterative normalisation (Zhang et al., 2019), or incrementally adding new languages to the multilingual space (Heymann et al., 2019) have been proposed to align such non-isomorphic embedding spaces. Recent work has also shown that—controlling for additional components—the standard GAN approach is competitive with more advanced GANs such as Wasserstein GAN and with the second-order similarity initialisation (Hartmann et al., 2019).
Unsupervised Deep Models
Supervised deep models that learn from parallel sentences or documents have been proposed before (see Sections 7 and 8 of this survey). In light of the success of pretrained language models, similar techniques have recently been applied to train unsupervised deep cross-lingual representations.
Joint models
The most prominent example in this line of work is multilingual BERT (mBERT), a BERT-base model that was jointly trained on the corpora of 104 languages with a shared vocabulary of 110k subword tokens.
mBERT is trained using masked language modelling (MLM)—with no explicit supervision—but has nevertheless been shown to learn cross-lingual representations that generalise surprisingly well to other languages via zero-shot transfer (Pires et al., 2019; Wu & Dredze, 2019). This generalisation ability has been attributed to three factors: 1) identical subwords in the shared vocabulary acting as anchor points for learning an alignment (similar to the weak supervision of CLWEs); 2) joint training across multiple languages that spreads this effect; and 3) deep cross-lingual representations that go beyond vocabulary memorisation and generalise across languages.
Recent work (Artetxe et al., 2019; Anonymous et al., 2019; Wu et al., 2019), however, shows that a shared vocabulary is not required for learning unsupervised deep cross-lingual representations. Artetxe et al. (2019) additionally demonstrate that joint training is unnecessary and identify the vocabulary size per language as an important factor: Multilingual models with larger vocabulary sizes consistently perform better.
Extensions to mBERT augment it with a supervised objective (Lample and Conneau, 2019), which is inspired by bilingual skip-gram approaches and can be seen in the Figure below. Others add auxiliary pre-training tasks such as cross-lingual word recovery and paraphrase detection (Huang et al., 2019), encourage representations of translations to be similar (Anonymous, 2019), and scale it up (Conneau et al., 2019). Joint training has been applied not only to Transformers but also to LSTM-based methods where initialisation with CLWEs has been found useful (Mulcaire et al., 2019).
Mapping-based approaches
The mapping-based approaches that we discussed previously have also been applied to the contextual representations of deep bilingual models. The main assumption behind these methods is that contextual representations—similar to their non-contextual counterparts—can also be aligned via a linear transformation. As can be seen in the Figure below, contextual representations cluster and have similar distributions across languages.
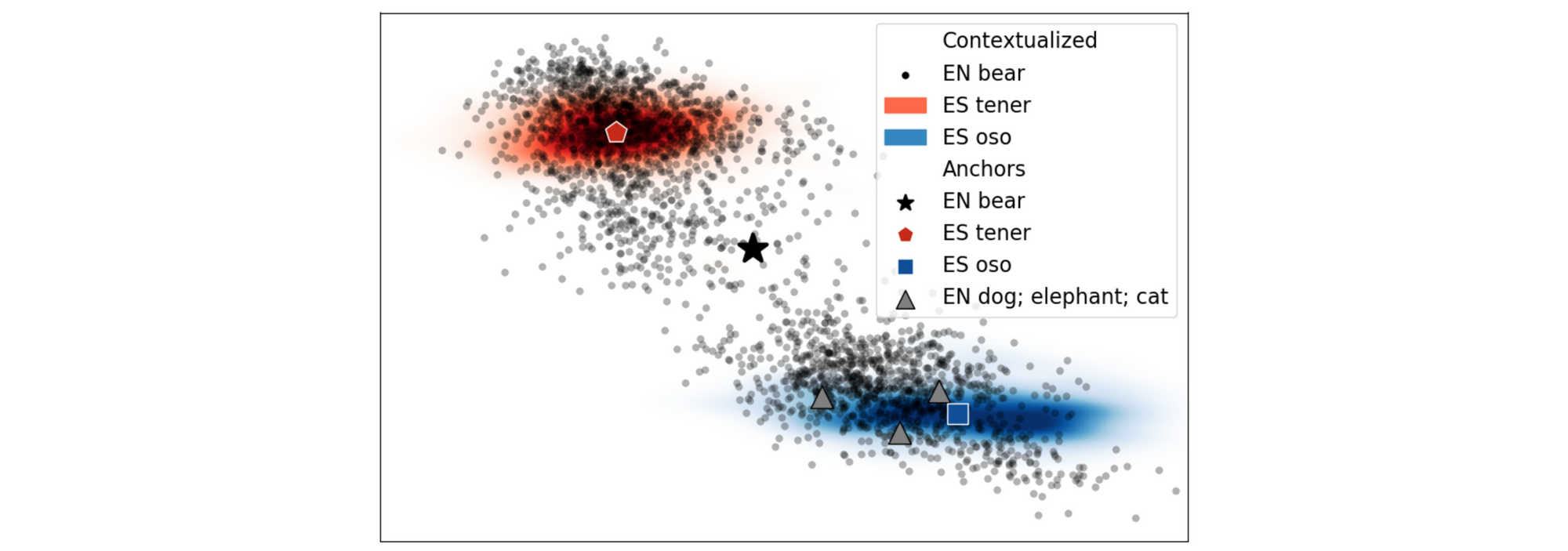
For contextual representations, the mapping can be done either on the token level or on the type level. On the token level, contextual representations of tokens in both languages can be aligned using word alignment information in parallel data (Aldarmaki & Diab, 2019). On the type level, an aggregate representation of a word's contextual representations such as its mean can be used as its type embeddings (Schuster et al., 2019). Type embeddings across languages can then be aligned using the same mapping-based approaches as before. Liu et al. (2019) perform further analyses and find that type-level alignment performs best. Mapping-based methods have also recently been applied to BERT-based representations (Anonymous et al., 2019; Wu et al., 2019).
Rather than learning a mapping between two existing pretrained models in \(L_1\) and \(L_2\), we can apply a model that was pretrained in a high-resource language \(L_1\) to a low-resource language \(L_2\) much more easily by simply learning token-level embeddings in \(L_2\) while keeping the model body fixed (Artetxe et al., 2019, Anonymous et al., 2019). The full process can be seen below. This alignment to a monolingual model may avoid the non-isomorphism of fixed monolingual vector spaces and the resulting model is competitive with jointly trained models.
Future Directions
Benchmarks
A standard task for evaluating CLWEs is bilingual lexicon induction (BLI), which evaluates the quality of the cross-lingual embedding space by determining whether words are nearest neighbours of their translations in a test dictionary. Recently, several researchers have identified issues with the standard MUSE dictionaries (Conneau et al., 2018) for this task, which only represent frequent words and are not morphologically diverse (Czarnowska et al., 2019; Kementchedjhieva et al., 2019). BLI performance on words with lower frequency ranks drops off drastically as can be seen below.
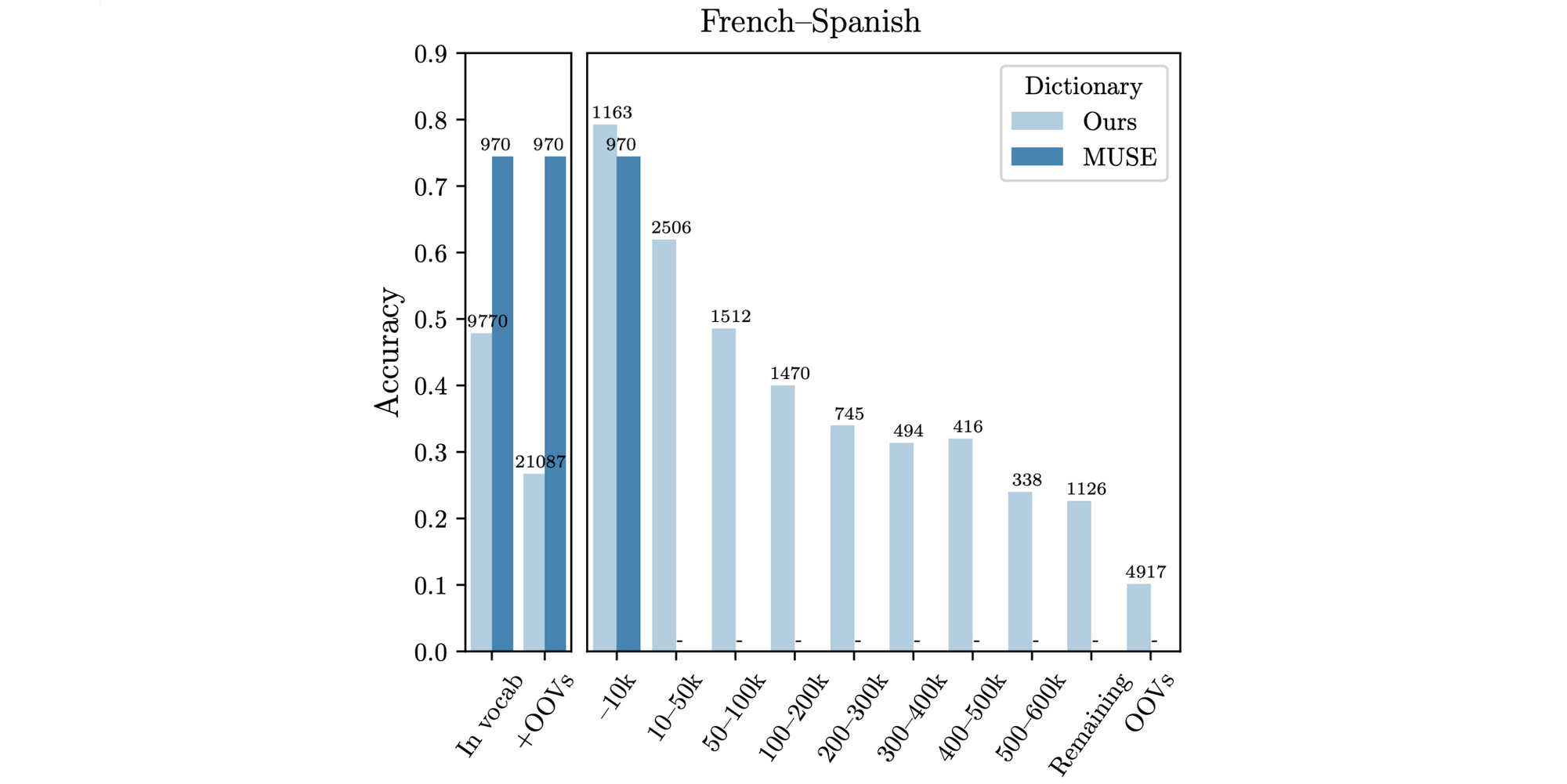
We are ultimately interested in applying our methods to downstream tasks in low-resource languages. While BLI correlates well with certain downstream tasks for mapping-based approaches (Glavaš et al., 2019), the correlation is weaker for methods that are not based on an orthogonal transformation. Downstream evaluation is thus important to accurately gauge the performance of novel methods in the future.
However, even existing cross-lingual downstream tasks have their problems. Cross-lingual document classification, a classic task for the evaluation of cross-lingual representations (Klementiev et al., 2012), mostly requires superficial keyword-matching and CLWEs outperform deep representations (Artetxe et al., 2019). A more recent multilingual benchmark, XNLI (Conneau et al., 2018) may be plagued by similar artefacts as the MultiNLI dataset from which it has been derived (Gururangan et al., 2018).
On the whole, we need more challenging benchmarks for evaluating multilingual models. Question answering might be a good candidate as it is a common probe for language understanding and has been shown to be harder to exploit. Recently, several cross-lingual question answering datasets have been proposed, including XQuAD (Artetxe et al., 2019), which extends SQuAD 1.1. to ten other languages, the open-domain XQA (Liu et al., 2019), and MLQA (Lewis et al., 2019).
Understanding representations
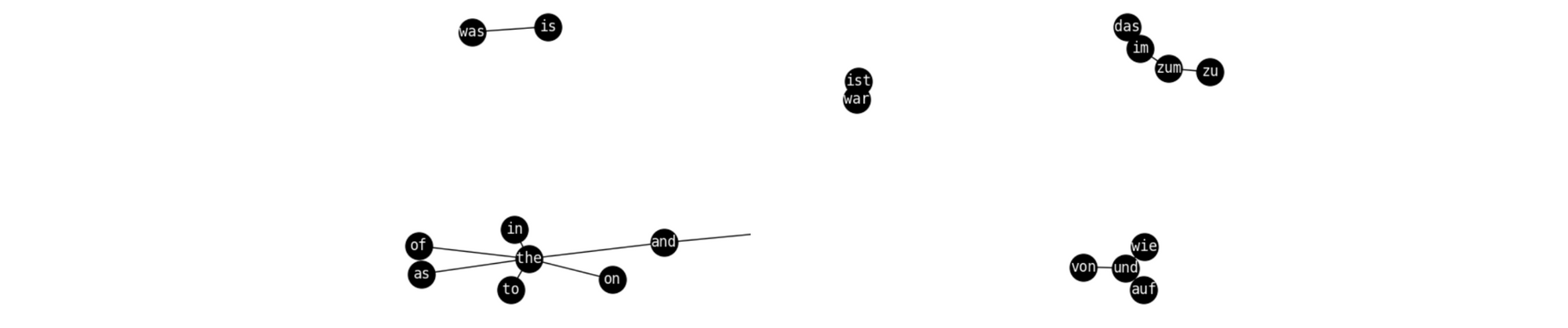
Benchmarks are also important for better understanding the representations that our models learn. Along these lines, it is still unclear what makes monolingual embedding spaces non-isomorphic. Even embedding spaces between similar languages are not strictly isomorphic as can be seen below. Similar issues might affect the spaces of deep contextual representations. Identifying the cause of this phenomenon may help us gain a better understanding of our learning algorithms and the biases they encode in their representations. It may also shed light on the semantic similarities and differences between languages.
There have been several studies analysing what CLWEs learn but it is still mostly unclear what representations learned by unsupervised deep multilingual models capture. As token-level alignment to a deep monolingual model achieves competitive results (Artetxe et al., 2019), deep multilingual models may still mostly learn lexical alignment. If this is the case, we need better methods that incentivise learning deep multilingual representations. Parallel data improves performance in practice (Lample & Conneau, 2019), but for low-resource languages we would like to use as little supervision as possible.
Deep representations from an English BERT model can be transferred to another language without any modification (besides learning new token embeddings; Artetxe et al., 2019). Consequently, it should be interesting to analyse what cross-lingual information monolingual models capture. In order to gain new insights, however, we need better benchmarks and evaluation protocols for the analysis of cross-lingual knowledge.
Practical considerations
In the end, we'd like to learn cross-lingual representations in order to apply them to downstream tasks in low-resource languages. In light of this, we should not forget practical concerns of such low-resource scenarios. While zero-shot transfer is a focus of current methods, zero-shot transfer is not free. It requires access to training data from the same task and distribution in a high-resource language. We should thus continue investing in approaches that can be trained with few samples in a target language and that combine the best of both the monolingual and cross-lingual worlds, for instance via cross-lingual bootstrapping that can be seen below (Eisenschlos et al., 2019).
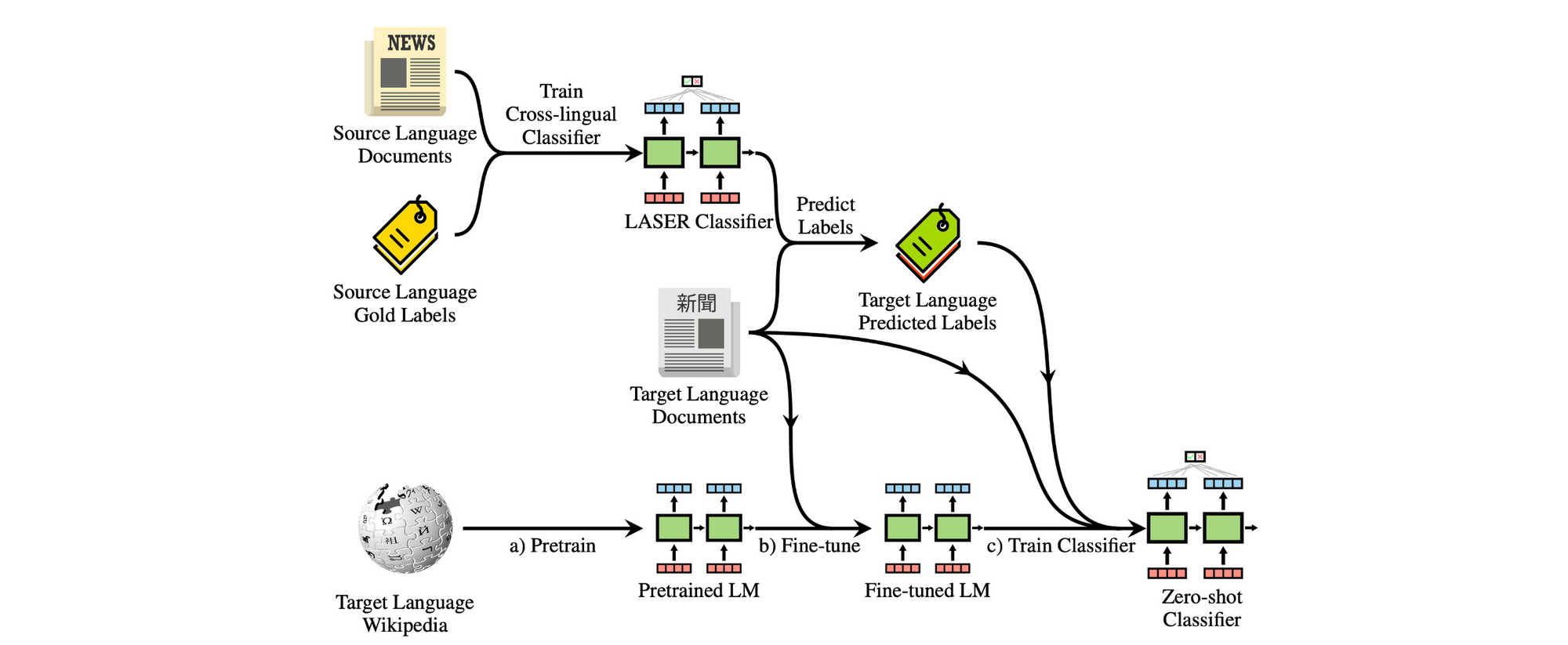
In addition, recent deep multilingual models are large and expensive to train. Training smaller multilingual models, for instance via distillation (Tsai et al., 2019), will be key for deployment in resource-constrained scenarios.
Recent wide-coverage parallel corpora such as JW-300 (Agić & Vulić, 2019) and WikiMatrix (Schwenk et al., 2019) enable the training of massively multilingual or supervised systems for many new low-resource languages where parallel data was previously not available. However, these resources still do not cover languages where only few unlabelled data is available. In order to apply our methods to tasks in such languages, we need to develop approaches that can learn representations from a limited number of samples. Resources that provide limited data (mostly dictionaries) for a large number of languages are the ASJP database, PanLex, and BabelNet.
Finally, while CLWEs underperform deep multilingual models on more challenging benchmarks (Artetxe et al., 2019), they are still preferred for easier tasks such as document classification due to their efficiency and ease of use. In addition, they serve as a useful initialisation to kick-start the training of deep models (Mulcaire et al., 2019; Anonymous et al., 2019) and of unsupervised NMT models (Artetxe et al., 2019). Consequently, they may be a useful foundation for the development of more resource and parameter-efficient deep multilingual models.
Citation
If you found this post helpful, consider citing the tutorial as:
@inproceedings{ruder2019unsupervised,
title={Unsupervised Cross-Lingual Representation Learning},
author={Ruder, Sebastian and S{\o}gaard, Anders and Vuli{\'c}, Ivan},
booktitle={Proceedings of ACL 2019, Tutorial Abstracts},
pages={31--38},
year={2019}
}