The State of Transfer Learning in NLP
This post expands on the NAACL 2019 tutorial on Transfer Learning in NLP. It highlights key insights and takeaways and provides updates based on recent work.

Update 16.10.2020: Added Chinese and Spanish translations.
This post expands on the NAACL 2019 tutorial on Transfer Learning in NLP. The tutorial was organized by Matthew Peters, Swabha Swayamdipta, Thomas Wolf, and me. In this post, I highlight key insights and takeaways and provide updates based on recent work. You can see the structure of this post below:
The slides, a Colaboratory notebook, and code of the tutorial are available online.
Introduction
For an overview of what transfer learning is, have a look at this blog post. Our go-to definition throughout this post will be the following, which is illustrated in the diagram below:
Transfer learning is a means to extract knowledge from a source setting and apply it to a different target setting.
In the span of little more than a year, transfer learning in the form of pretrained language models has become ubiquitous in NLP and has contributed to the state of the art on a wide range of tasks. However, transfer learning is not a recent phenomenon in NLP. One illustrative example is progress on the task of Named Entity Recognition (NER), which can be seen below.
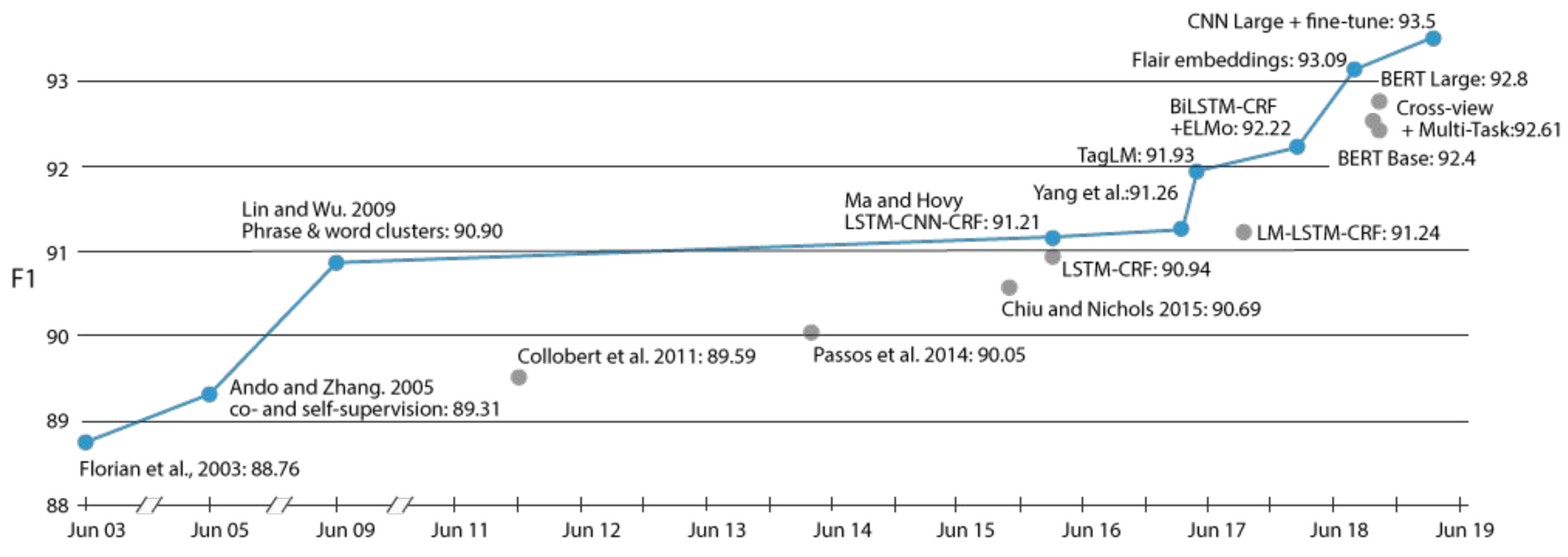
Throughout its history, most of the major improvements on this task have been driven by different forms of transfer learning: from early self-supervised learning with auxiliary tasks (Ando and Zhang, 2005) and phrase & word clusters (Lin and Wu, 2009) to the language model embeddings (Peters et al., 2017) and pretrained language models (Peters et al., 2018; Akbik et al., 2018; Baevski et al., 2019) of recent years.
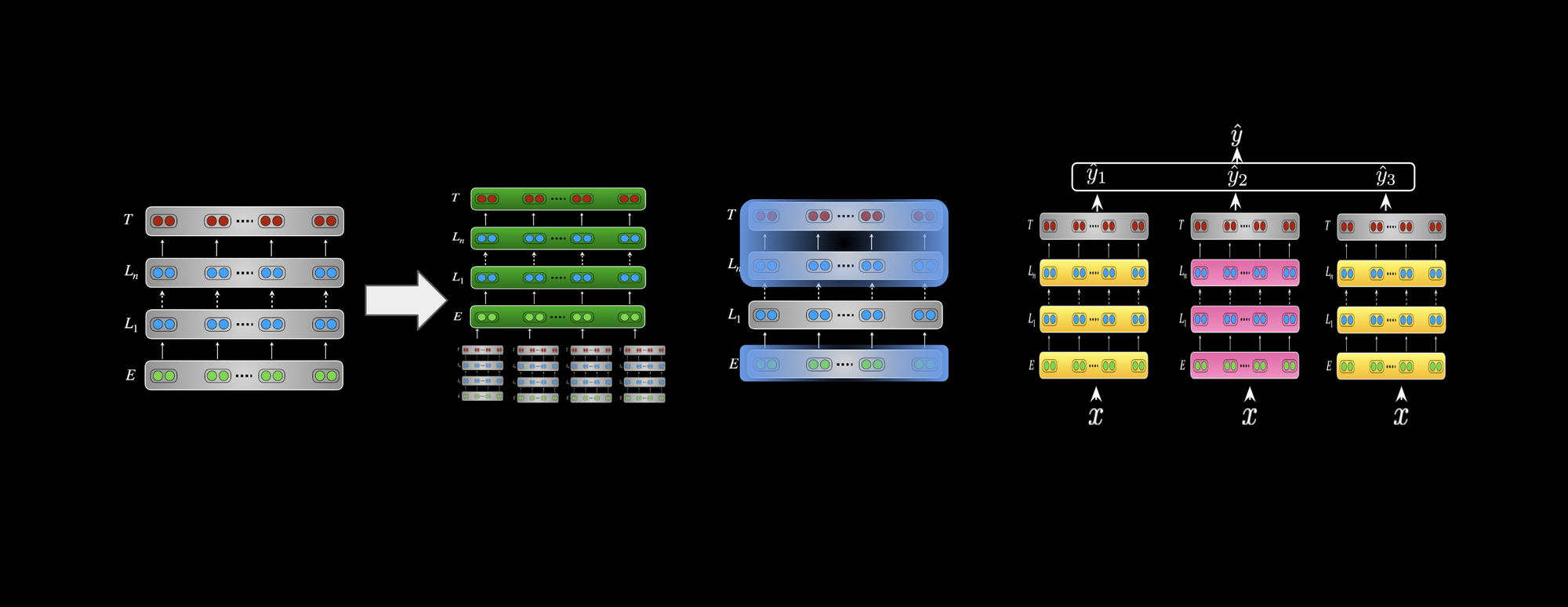
There are different types of transfer learning common in current NLP. These can be roughly classified along three dimensions based on a) whether the source and target settings deal with the same task; and b) the nature of the source and target domains; and c) the order in which the tasks are learned. A taxonomy that highlights the variations can be seen below:
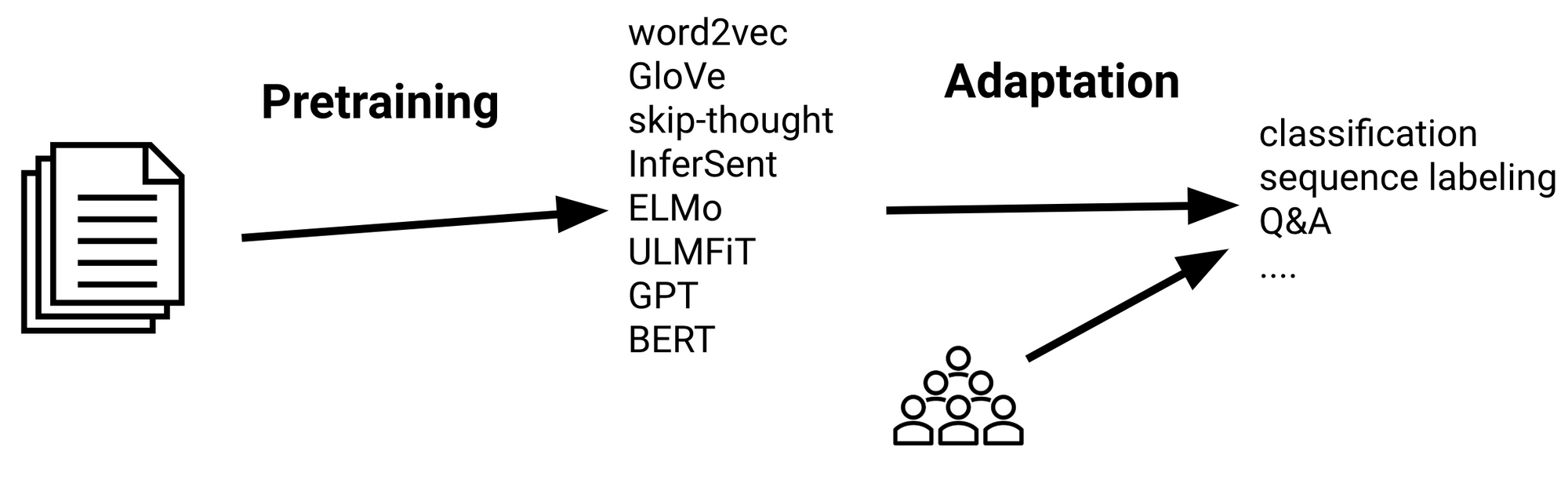
Sequential transfer learning is the form that has led to the biggest improvements so far. The general practice is to pretrain representations on a large unlabelled text corpus using your method of choice and then to adapt these representations to a supervised target task using labelled data as can be seen below.
Major themes
Several major themes can be observed in how this paradigm has been applied:
From words to words-in-context Over time, representations incorporate more context. Early approaches such as word2vec (Mikolov et al., 2013) learned a single representation for every word independent of its context. Later approaches then scaled these representations to sentences and documents (Le and Mikolov, 2014; Conneau et al., 2017). Current approaches learn word representations that change based on the word's context (McCann et al., 2017; Peters et al., 2018).
LM pretraining Many successful pretraining approaches are based on variants of language modelling (LM). Advantages of LM are that it does not require any human annotation and that many languages have enough text available to learn reasonable models. In addition, LM is versatile and enables learning both sentence and word representations with a variety of objective functions.
From shallow to deep Over the last years, state-of-the-art models in NLP have become progressively deeper. Up to two years ago, the state of the art on most tasks was a 2-3 layer deep BiLSTM, with machine translation being an outlier with 16 layers (Wu et al., 2016). In contrast, current models like BERT-Large and GPT-2 consist of 24 Transformer blocks and recent models are even deeper.
Pretraining vs target task The choice of pretraining and target tasks is closely intertwined. For instance, sentence representations are not useful for word-level predictions, while span-based pretraining is important for span-level predictions. On the whole, for the best target performance, it is beneficial to choose a similar pretraining task.
Pretraining
Why does language modelling work so well?
The remarkable success of pretrained language models is surprising. One reason for the success of language modelling may be that it is a very difficult task, even for humans. To have any chance at solving this task, a model is required to learn about syntax, semantics, as well as certain facts about the world. Given enough data, a large number of parameters, and enough compute, a model can do a reasonable job. Empirically, language modelling works better than other pretraining tasks such as translation or autoencoding (Zhang et al. 2018; Wang et al., 2019).
A recent predictive-rate distortion (PRD) analysis of human language (Hahn and Futrell, 2019) suggests that human language—and language modelling—has infinite statistical complexity but that it can be approximated well at lower levels. This observation has two implications: 1) We can obtain good results with comparatively small models; and 2) there is a lot of potential for scaling up our models. For both implications we have empirical evidence, as we can see in the next sections.
Sample efficiency
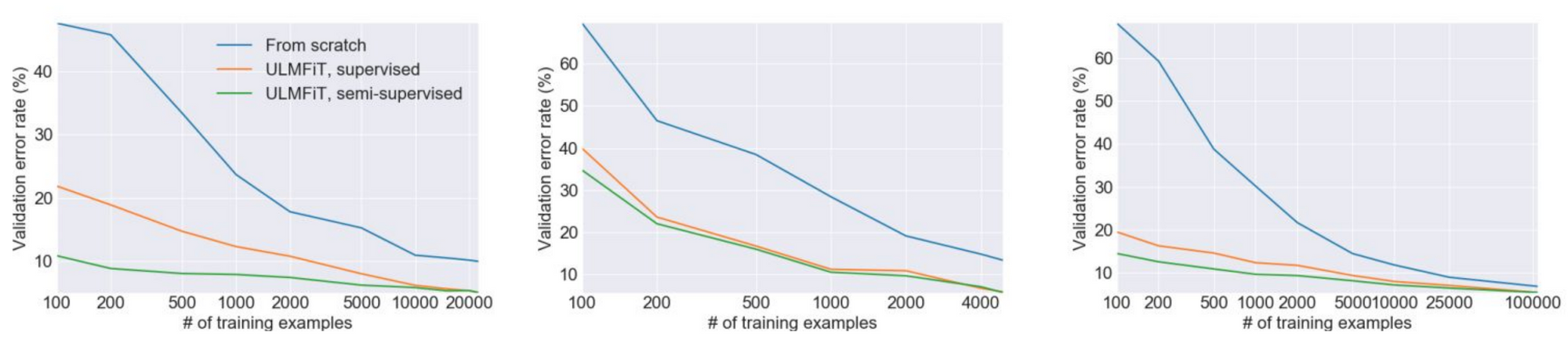
One of the main benefits of pretraining is that it reduces the need for annotated data. In practice, transfer learning has often been shown to achieve similar performance compared to a non-pretrained model with 10x fewer examples or more as can be seen below for ULMFiT (Howard and Ruder, 2018).
Scaling up pretraining
Pretrained representations can generally be improved by jointly increasing the number of model parameters and the amount of pretraining data. Returns start to diminish as the amount of pretraining data grows huge. Current performance curves such as the one below, however, do not indicate that we have reached a plateau. We can thus expect to see even bigger models trained on more data.
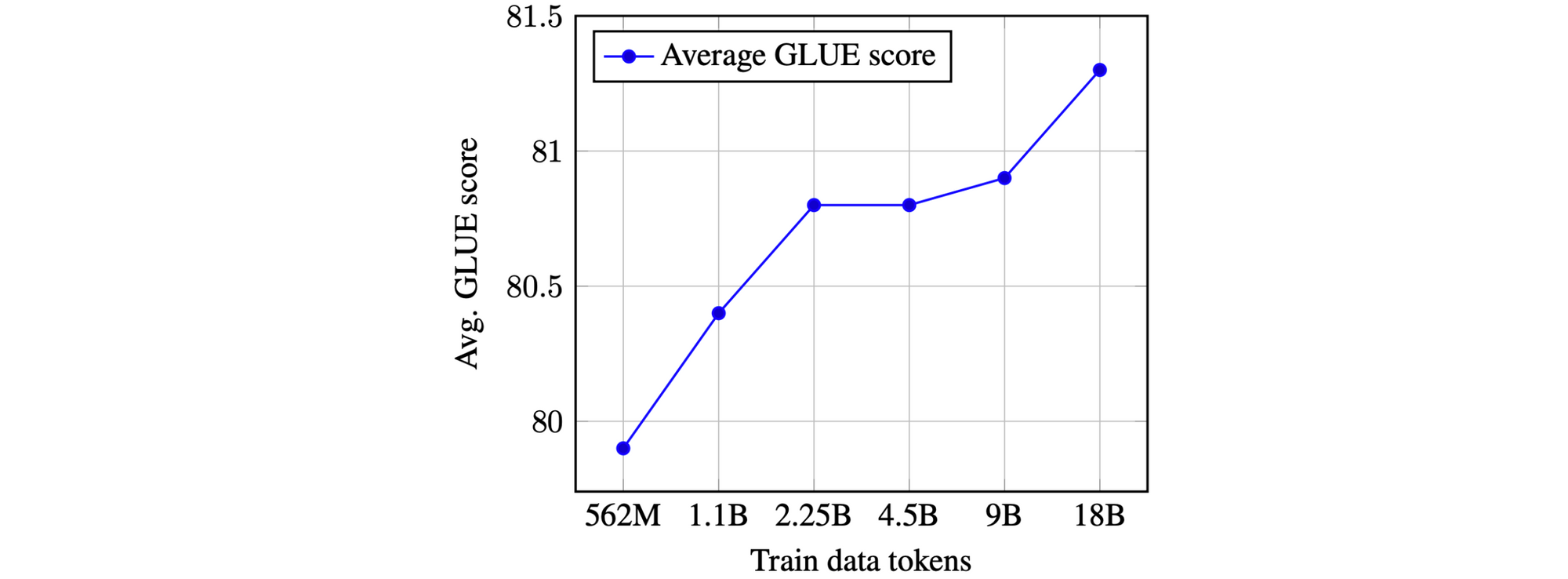
Recent examples of this trend are ERNIE 2.0, XLNet, GPT-2 8B, and RoBERTa. The latter in particular finds that simply training BERT for longer and on more data improves results, while GPT-2 8B reduces perplexity on a language modelling dataset (though only by a comparatively small factor).
Cross-lingual pretraining
A major promise of pretraining is that it can help us bridge the digital language divide and can enable us learn NLP models for more of the world's 6,000 languages. Much work on cross-lingual learning has focused on training separate word embeddings in different languages and learning to align them (Ruder et al., 2019). In the same vein, we can learn to align contextual representations (Schuster et al., 2019). Another common method is to share a subword vocabulary and train one model on many languages (Devlin et al., 2019; Artetxe and Schwenk, 2019; Mulcaire et al., 2019; Lample and Conneau, 2019). While this is easy to implement and is a strong cross-lingual baseline, it leads to under-representation of low-resource languages (Heinzerling and Strube, 2019). Multilingual BERT in particular has been the subject of much recent attention (Pires et al., 2019; Wu and Dredze, 2019). Despite its strong zero-shot performance, dedicated monolingual language models often are competitive, while being more efficient (Eisenschlos et al., 2019).
Practical considerations
Pretraining is cost-intensive. Pretraining the Transformer-XL style model we used in the tutorial takes 5h–20h on 8 V100 GPUs (a few days with 1 V100) to reach a good perplexity. Sharing pretrained models is thus very important. Pretraining is relatively robust to the choice of hyper-parameters—apart from needing a learning rate warm-up for transformers. As a general rule, your model should not have enough capacity to overfit if your dataset is large enough. Masked language modeling (as in BERT) is typically 2-4 times slower to train than standard LM as masking only a fraction of words yields a smaller signal.
What is in a representation?
Representations have been shown to be predictive of certain linguistic phenomena such as alignments in translation or syntactic hierarchies. Better performance has been achieved when pretraining with syntax; even when syntax is not explicitly encoded, representations still learn some notion of syntax (Williams et al. 2018). Recent work has furthermore shown that knowledge of syntax can be distilled efficiently into state-of-the-art models (Kuncoro et al., 2019). Network architectures generally determine what is in a representation. For instance, BERT has been observed to capture syntax (Tenney et al., 2019; Goldberg, 2019). Different architectures show different layer-wise trends in terms of what information they capture (Liu et al., 2019).
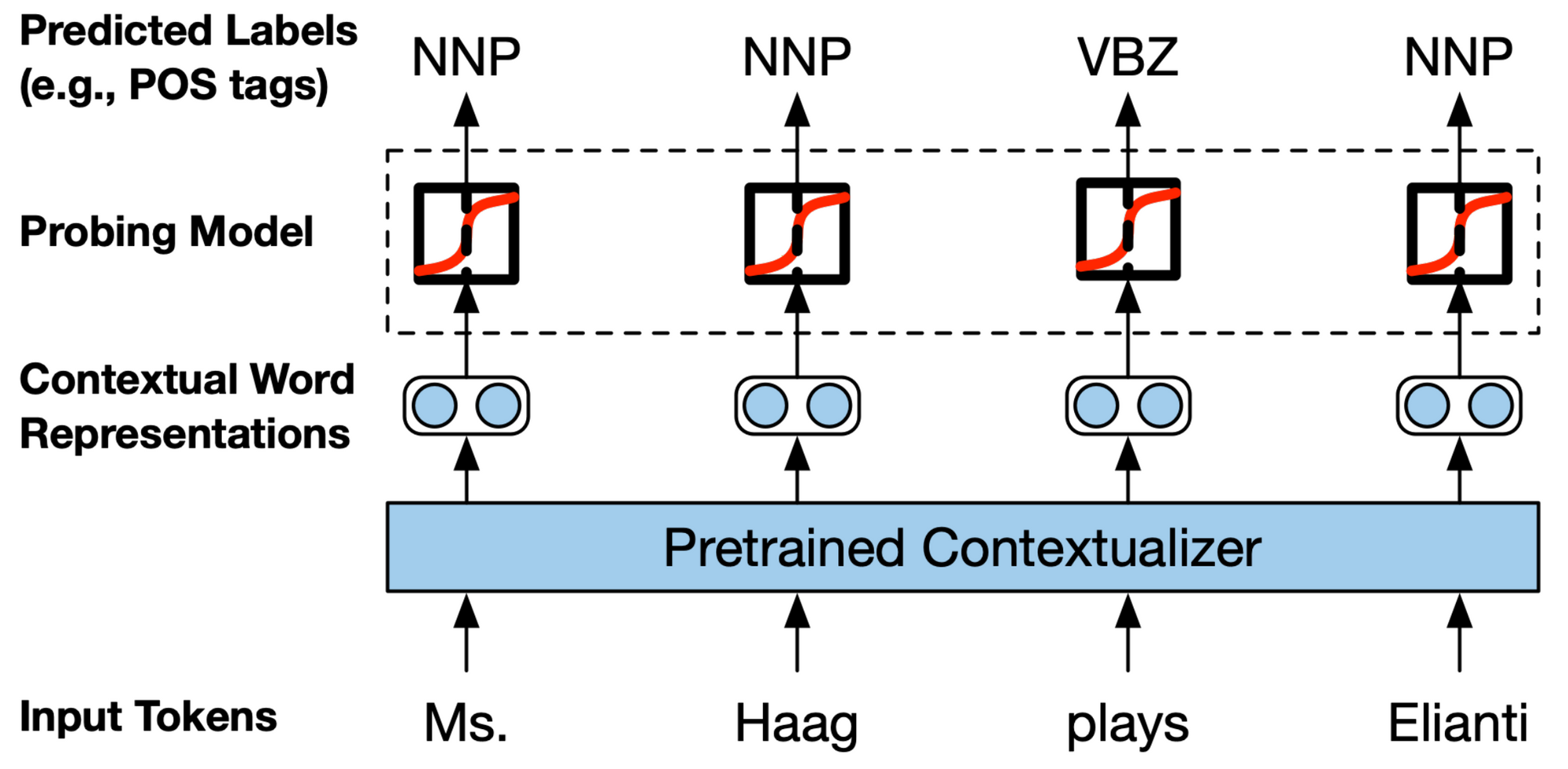
The information that a model captures also depends how you look at it: Visualizing activations or attention weights provides a bird's eye view of the model's knowledge, but focuses on a few samples; probes that train a classifier on top of learned representations in order to predict certain properties (as can be seen above) discover corpus-wide specific characteristics, but may introduce their own biases; finally, network ablations are great for improving the model, but may be task-specific.
Adaptation
For adapting a pretrained model to a target task, there are several orthogonal directions we can make decisions on: architectural modifications, optimization schemes, and whether to obtain more signal.
Architectural modifications
For architectural modifications, the two general options we have are:
a) Keep the pretrained model internals unchanged This can be as simple as adding one or more linear layers on top of a pretrained model, which is commonly done with BERT. Instead, we can also use the model output as input to a separate model, which is often beneficial when a target task requires interactions that are not available in the pretrained embedding, such as span representations or modelling cross-sentence relations.
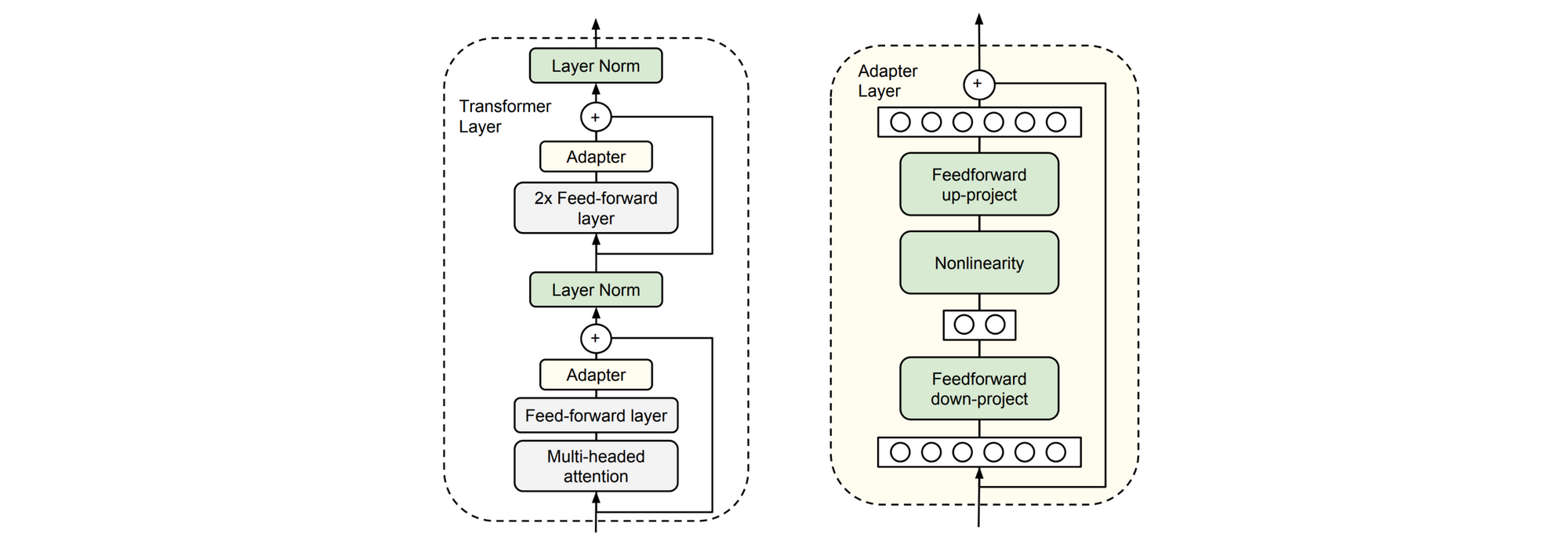
b) Modify the pretrained model internal architecture One reason why we might want to do this is in order to adapt to a structurally different target task such as one with several input sequences. In this case, we can use the pretrained model to initialize as much as possible of a structurally different target task model. We might also want to apply task-specific modifications such as adding skip or residual connections or attention. Finally, modifying the target task parameters may reduce the number of parameters that need to be fine-tuned by adding bottleneck modules (“adapters”) between the layers of the pretrained model (Houlsby et al., 2019; Stickland and Murray, 2019).
Optimization schemes
In terms of optimizing the model, we can choose which weights we should update and how and when to update those weights.
Which weights to update
For updating the weights, we can either tune or not tune (the pretrained weights):
a) Do not change the pretrained weights (feature extraction) In practice, a linear classifier is trained on top of the pretrained representations. The best performance is typically achieved by using the representation not just of the top layer, but learning a linear combination of layer representations (Peters et al., 2018, Ruder et al., 2019). Alternatively, pretrained representations can be used as features in a downstream model. When adding adapters, only the adapter layers are trained.
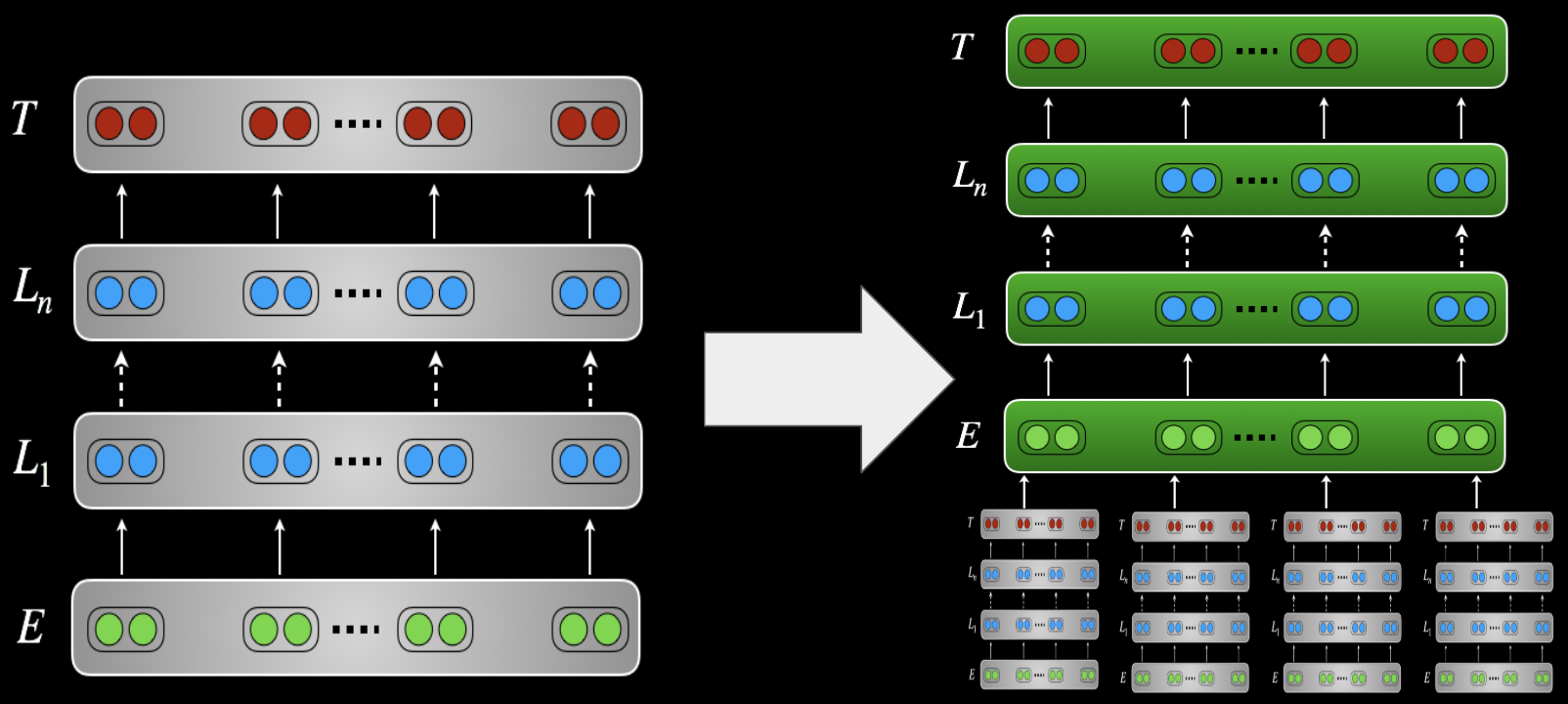
b) Change the pretrained weights (fine-tuning) The pretrained weights are used as initialization for parameters of the downstream model. The whole pretrained architecture is then trained during the adaptation phase.
How and when to update the weights
The main motivation for choosing the order and how to update the weights is that we want to avoid overwriting useful pretrained information and maximize positive transfer. Related to this is the concept of catastrophic forgetting (McCloskey & Cohen, 1989; French, 1999), which occurs if a model forgets the task it was originally trained on. In most settings, we only care about the performance on the target task, but this may differ depending on the application.
A guiding principle for updating the parameters of our model is to update them progressively from top-to-bottom in time, in intensity, or compared to a pretrained model:
a) Progressively in time (freezing) The main intuition is that training all layers at the same time on data of a different distribution and task may lead to instability and poor solutions. Instead, we train layers individually to give them time to adapt to the new task and data. This goes back to layer-wise training of early deep neural networks (Hinton et al., 2006; Bengio et al., 2007). Recent approaches (Felbo et al., 2017; Howard and Ruder, 2018; Chronopoulou et al., 2019) mostly vary in the combinations of layers that are trained together; all train all parameters jointly in the end. Unfreezing has not been investigated in detail for Transformer models.
b) Progressively in intensity (lower learning rates) We want to use lower learning rates to avoid overwriting useful information. Lower learning rates are particularly important in lower layers (as they capture more general information), early in training (as the model still needs to adapt to the target distribution), and late in training (when the model is close to convergence). To this end, we can use discriminative fine-tuning (Howard and Ruder, 2018), which decays the learning rate for each layer as can be seen below. In order to maintain lower learning rates early in training, a triangular learning rate schedule can be used, which is also known as learning rate warm-up in Transformers. Liu et al. (2019) recently suggest that warm-up reduces variance in the early stage of training.
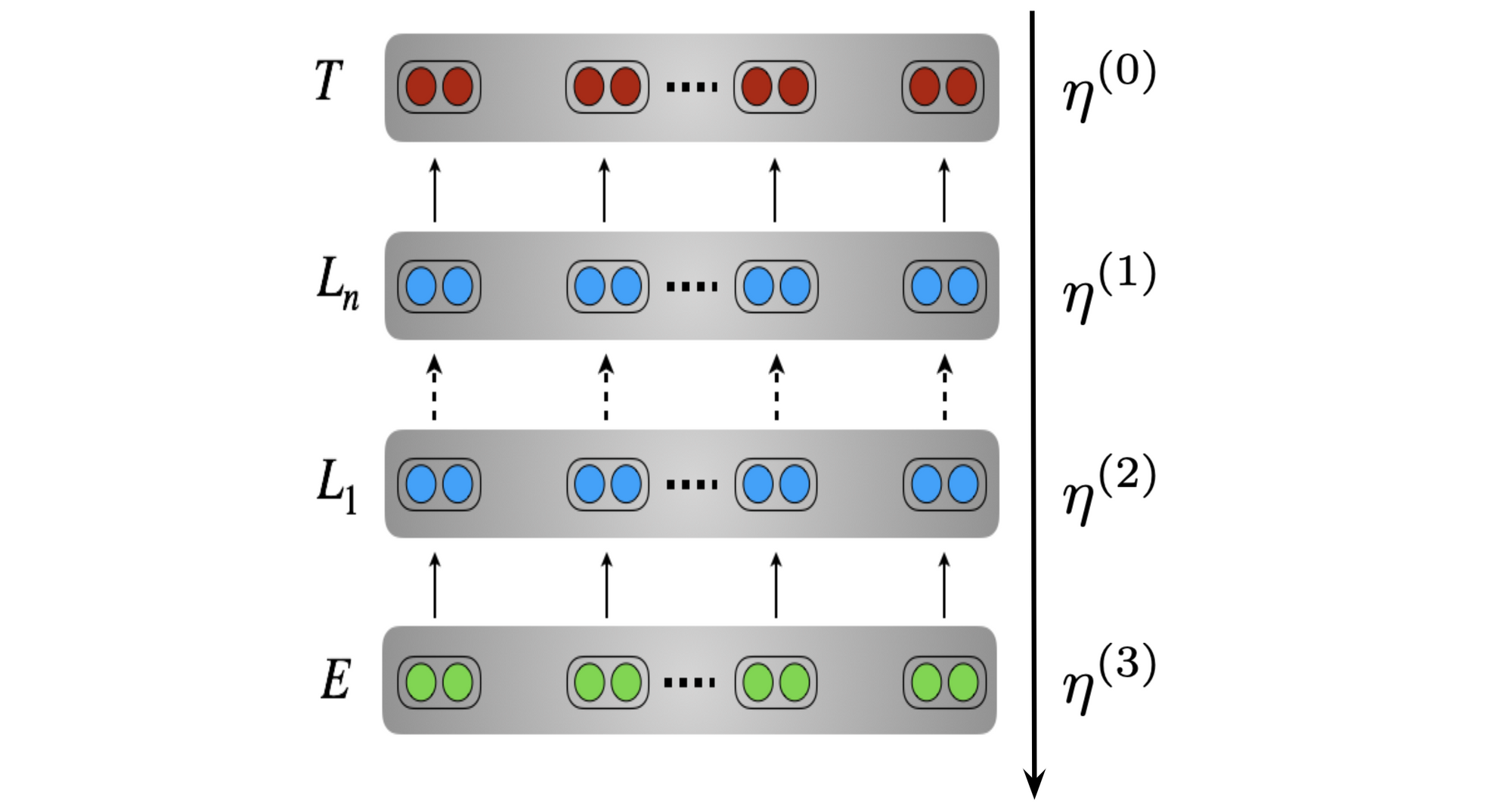
c) Progressively vs. a pretrained model (regularization) One way to minimize catastrophic forgetting is to encourage target model parameters to stay close to the parameters of the pretrained model using a regularization term (Wiese et al., CoNLL 2017, Kirkpatrick et al., PNAS 2017).
Trade-offs and practical considerations
In general, the more parameters you need to train from scratch the slower your training will be. Feature extraction requires adding more parameters than fine-tuning (Peters et al., 2019), so is typically slower to train. Feature extraction, however, is more space-efficient when a model needs to be adapted to many tasks as it only requires storing one copy of the pretrained model in memory. Adapters strike a balance by adding a small number of additional parameters per task.
In terms of performance, no adaptation method is clearly superior in every setting. If source and target tasks are dissimilar, feature extraction seems to be preferable (Peters et al., 2019). Otherwise, feature extraction and fine-tuning often perform similar, though this depends on the budget available for hyper-parameter tuning (fine-tuning may often require a more extensive hyper-parameter search). Anecdotally, Transformers are easier to fine-tune (less sensitive to hyper-parameters) than LSTMs and may achieve better performance with fine-tuning.
However, large pretrained models (e.g. BERT-Large) are prone to degenerate performance when fine-tuned on tasks with small training sets. In practice, the observed behavior is often “on-off”: the model either works very well or does not work at all as can be seen in the figure below. Understanding the conditions and causes of this behavior is an open research question.
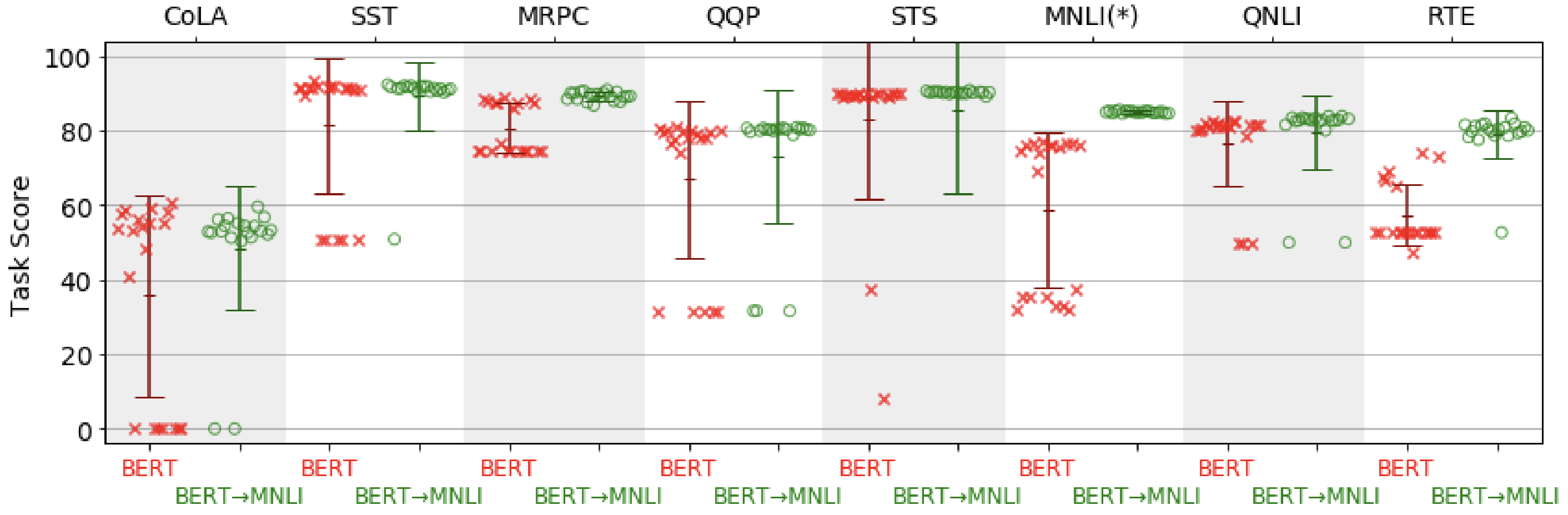
Getting more signal
The target task is often a low-resource task. We can often improve the performance of transfer learning by combining a diverse set of signals:
Sequential adaptation If related tasks are available, we can fine-tune our model first on a related task with more data before fine-tuning it on the target task. This
helps particularly for tasks with limited data and similar tasks (Phang et al., 2018) and improves sample efficiency on the target task (Yogatama et al., 2019).
Multi-task fine-tuning Alternatively, we can also fine-tune the model jointly on related tasks together with the target task. The related task can also be an unsupervised auxiliary task. Language modelling is a good choice for this and has been shown to help even without pretraining (Rei et al., 2017). The task ratio can optionally be annealed to de-emphasize the auxiliary task towards the end of training (Chronopoulou et al., NAACL 2019). Language model fine-tuning is used as a separate step in ULMFiT (Howard and Ruder, 2018). Recently, multi-task fine-tuning has led to improvements even with many target tasks (Liu et al., 2019, Wang et al., 2019).
Dataset slicing Rather than fine-tuning with auxiliary tasks, we can use auxiliary heads that are trained only on particular subsets of the data. To this end, we would first analyze the errors of the model, use heuristics to automatically identify challenging subsets of the training data, and then train auxiliary heads jointly with main head.
Semi-supervised learning We can also use semi-supervised learning methods to make our model's predictions more consistent by perturbing unlabelled examples. The perturbation can be noise, masking (Clark et al., 2018), or data augmentation, e.g. back-translation (Xie et al., 2019).
Ensembling To improve performance the predictions of models fine-tuned with different hyper-parameters, fine-tuned with different pretrained models, or trained on different target tasks or dataset splits may be combined.
Distilling Finally, large models or ensembles of models may be distilled into a single, smaller model. The model can also be a lot simpler (Tang et al., 2019) or have a different inductive bias (Kuncoro et al., 2019). Multi-task fine-tuning can also be combined with distillation (Clark et al., 2019).
Down-stream applications
Pretraining large-scale models is costly, not only in terms of computation but also in terms of the environmental impact (Strubell et al., 2019). Whenever possible, it's best to use open-source models. If you need to train your own models, please share your pretrained models with the community.
Frameworks and libraries
For sharing and accessing pretrained models, different options are available:
Hubs Hubs are central repositories that provide a common API for accessing pretrained models. The two most common hubs are TensorFlow Hub and PyTorch Hub. Hubs are generally simple to use; however, they act more like a black-box as the source code of the model cannot be easily accessed. In addition, modifying the internals of a pretrained model architecture can be difficult.
Author released checkpoints Checkpoint files generally contain all the weights of a pretrained model. In contrast to hub modules, the model graph still needs to be created and model weights need to be loaded separately. As such, checkpoint files are more difficult to use than hub modules, but provide you with full control over the model internals.
Third-party libraries Some third-party libraries like AllenNLP, fast.ai, and pytorch-transformers provide easy access to pretrained models. Such libraries typically enable fast experimentation and cover many standard use cases for transfer learning.
For examples of how such models and libraries can be used for downstream tasks, have a look at the code snippets in the slides, the Colaboratory notebook, and the code.
Open problems and future directions
There are many open problems and interesting future research directions. Below is just an updated selection. For more pointers, have a look at the slides.
Shortcomings of pretrained language models
Pretrained language models are still bad at fine-grained linguistic tasks (Liu et al., 2019), hierarchical syntactic reasoning (Kuncoro et al., 2019), and common sense (when you actually make it difficult; Zellers et al., 2019). They still fail at natural language generation, in particular maintaining long-term dependencies, relations, and coherence. They also tend to overfit to surface form information when fine-tuned and can still mostly be seen as ‘rapid surface learners’.
As we have noted above, particularly large models that are fine-tuned on small amounts of data are difficult to optimize and suffer from high variance. Current pretrained language models are also very large. Distillation and pruning are two ways to deal with this.
Pretraining tasks
While the language modelling objective has shown to be effective empirically, it has its weaknesses. Lately, we have seen that bidirectional context and modelling contiguous word sequences is particularly important. Maybe most importantly, language modelling encourages a focus on syntax and word co-occurrences and only provides a weak signal for capturing semantics and long-term context. We can take inspiration from other forms of self-supervision. In addition, we can design specialized pretraining tasks that explicitly learn certain relationships (Joshi et al., 2019, Sun et al., 2019).
On the whole, it is difficult to learn certain types of information from raw text. Recent approaches incorporate structured knowledge (Zhang et al., 2019; Logan IV et al., 2019) or leverage multiple modalities (Sun et al., 2019; Lu et al., 2019) as two potential ways to mitigate this problem.
Citation
If you found this post helpful, consider citing the tutorial as:
@inproceedings{ruder2019transfer,
title={Transfer Learning in Natural Language Processing},
author={Ruder, Sebastian and Peters, Matthew E and Swayamdipta, Swabha and Wolf, Thomas},
booktitle={Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Tutorials},
pages={15--18},
year={2019}
}Translations
This article has been translated into the following languages: