The State of Multilingual AI
This post takes a closer look at the state of multilingual AI. How multilingual are current models in NLP, computer vision, and speech? What are the main recent contributions in this area? What challenges remain and how we can we address them?

Models that allow interaction via natural language have become ubiquitious. Research models such as BERT and T5 have become much more accessible while the latest generation of language and multi-modal models are demonstrating increasingly powerful capabilities. At the same time, a wave of NLP startups has started to put this technology to practical use.
While such language technology may be hugely impactful, recent models have mostly focused on English and a handful of other languages with large amounts of resources. Developing models that work for more languages is important in order to offset the existing language divide and to ensure that speakers of non-English languages are not left behind, among many other reasons.
This post takes a closer look at how the AI community is faring in this endeavour. I will be focusing on topics related to natural language processing (NLP) and African languages as these are the domains I am most familiar with. I've tried to cover as many contributions as possible but undoubtedly missed relevant work. Feel free to leave a comment or reach out with a pointer to anything I missed.
This post is partially based on a keynote I gave at the Deep Learning Indaba 2022. It covers the following high-level topics:
Status Quo
There are around 7,000 languages spoken around the world. Around 400 languages have more than 1M speakers and around 1,200 languages have more than 100k [1]. Bender [2] highlighted the need for language independence in 2011. Reviewing papers published at ACL 2008, she found that 63% of all papers focused on English. For a recent study [3], we similarly reviewed papers from ACL 2021 and found that almost 70% of papers only evaluate on English. 10 years on, little thus seems to have changed.
Many languages in Africa, Asia, and the Americas that are spoken by tens of millions of people have received little research attention [1:1][4]. Continents such as Africa with around 2,000 languages or individual countries such as Indonesia with around 700 languages are incredibly linguistically diverse and at the same time dramatically underserved by current research and technology.
Beyond individual languages, researchers with affiliations in countries where such languages are spoken are similarly under-represented in both ML and NLP communities. For instance, while we can observe a slight upward trend in the number of authors affiliated with African universities publishing at top machine learning (ML) and NLP venues, this increase pales compared to the thousands of authors from other regions publishing in such venues every year.

Current state-of-the-art models in many ML domains are mainly based on two ingredients: 1) large, scalable architectures (often based on the Transformer [5]) and 2) transfer learning[6]. Given the general nature of these models, they can be applied to various types of data including images [7], video [8], and audio [9]. Some of the most successful models in recent NLP are BERT [10], RoBERTa [11], BART [12], T5 [13], and DeBERTa [14], which have been trained on billions of tokens of online text using variants of masked language modeling in English. In speech, wav2vec 2.0 [15] has been pre-trained on large amounts of unlabeled speech.
Multilingual models These models have multilingual analogues—in NLP, models such as mBERT, RemBERT [16], XLM-RoBERTa [17], mBART [18], mT5 [19], and mDeBERTa [14:1]—that were trained in a similar fashion, predicting randomly masked tokens on data of around 100 languages. Compared to their monolingual counterparts, these multilingual models require a much larger vocabulary to represent tokens in many languages.
A number of factors has been found to be important for learning robust multilingual representations, including shared tokens [20], subword fertility [21], and word embedding alignment [22]. In speech, models such as XSLR [23] and UniSpeech [24] are pre-trained on large amounts of unlabeled data in 53 and 60 languages respectively.
The curse of multilinguality Why do these models only cover up to 100 languages? One reason is the 'curse of multilinguality' [17:1]. Similar to models that are trained on many tasks, the more languages a model is pre-trained on, the less model capacity is available to learn representations for each language. Increasing the size of a model ameliorates this to some extent, enabling the model to dedicate more capacity to each language [25].
Lack of pre-training data Another limiting factor is the availability of text data on the web, which is skewed towards languages spoken in Western countries and with a large online footprint. The languages with the most online resources available for pre-training are typically prioritized, leading to an under-representation of languages with few resources due to this top-heavy selection. This is concerning as prior studies have shown that the amount of pre-training data in a language correlates with downstream performance for some tasks [26][27][28]. In particular, languages and scripts that were never seen during pre-training often lead to poor performance [29][30].

Quality issues in existing multilingual resources Even for languages where data is available, past work has shown that some commonly used multilingual resources have severe quality issues. Entity names in Wikidata are not in the native script for many under-represented languages while entity spans in WikiAnn [31], a weakly supervised multilingual named entity recognition dataset based on Wikipedia, are often erroneous [32].
Similarly, several automatically mined resources and automatically aligned corpora used for machine translation are problematic [33]. For instance, 44/65 audited languages in WikiMatrix [34] and 19/20 audited langages in CCAligned [35] contain less than 50% correct sentences. Overall, however, performance seems to be mostly constrained by the quantity rather than quality of data in under-represented languages [36].
Multilingual evaluation results We can get a better picture of the state of the art by looking at the performance of recent models on a representative multilingual benchmark such as XTREME [26:1]—a multilingual counterpart to GLUE [37] and SuperGLUE [38]—which aggregates performance across 9 tasks and 40 languages. Starting with the first multilingual pre-trained models two and a half years ago, performance has improved steadily and is slowly approaching human-level performance on the benchmark.

However, looking at the average performance on such a benchmark obscures which languages a model was actually evaluated on. Beyond a few datasets with a large language coverage—Universal Dependencies [39], WikiAnn [31:1], and Tatoeba [40]—other tasks only cover few languages, and are again skewed towards languages with more resources. Most current benchmarks thus only provide a distorted view of the overall progress towards multilingual AI for the world's languages.
For a more accurate impression, we can look at the normalized state-of-the-art performance on different language technology tasks averaged across the world's languages either based on their speaker population (demographic utility) or equally (linguistic utility) [41].

Most NLP tasks fare better when we average based on speaker population. Overall, however, we observe very low linguistic utility numbers, showing an unequal performance distribution across the world's languages. This conclusion, however, may be somewhat overly pessimistic as it only considers languages for which evaluation data is currently available. Cross-lingual performance prediction [42] could be used to estimate performance for a broader set of languages.
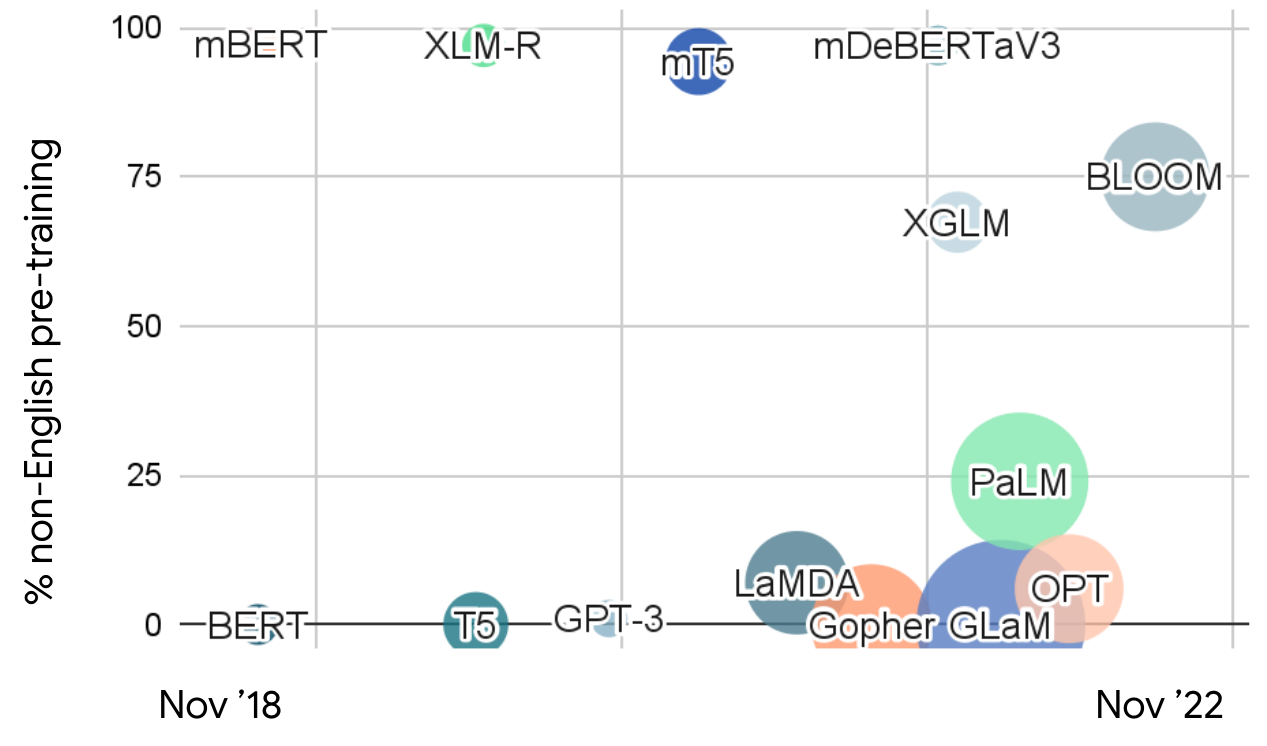
Multilingual vs English-centric models Let us now take a step back and look at recent large language models in NLP in general. We can plot recent models based on the fraction of non-English data they are pre-trained on. Based on this characterization, we can observe two distinct streams of research: 1) Multilingual models that are trained on multingual data in many languages and 2) English-centric models that are trained on mostly English data.

The latter form the foundation for the mainstream of NLP research and while these models have been getting larger, they have not been getting much more multilingual. An exception is BLOOM [43], the largest multilingual open-source model to date. Some of these large models have demonstrated surprising multilingual capabilities. For instance, GPT-3 [44] and PaLM [45] can translate text between languages with large amounts of data. While they have been shown to be able to perform multilingual few-shot learning [46][47][48], models perform best when prompts or input data are translated to English. They also perform poorly when translating between non-English language pairs or into languages with limited data. While PaLM is able to summarize non-English text into English, it struggles when generating text in other languages.
Similarly, recent speech models such as HuBERT [49] and WavLM [50] and recent large vision models that generate text based on an image such as Flamingo [51] or an image based on text such as DALL-E 2 [52], Imagen [53], and Parti [54] are English-centric. Exceptions are Whisper [55] and PaLI [56], which are pre-trained on large amounts of weakly supervised data from the web for ASR and image captioning in 96 and 109 languages respectively. However, overall, for the latest generation of large models, multilinguality remains a side-effect rather than a key design criterion.
User-facing technologies With regard to user-facing technologies, keyboards and spell checkers such as Gboard support more than 900+ languages but many languages still lack support or speakers may be unaware that a keyboard for their language is available [57]. Other user-facing technologies with broad language coverage are machine translation and automatic speech recognition (ASR). Google Translate and speech-to-text, for instance, support 133 and more than 125 languages respectively as of the publishing of this post.
Recent Progress
Recent progress in this area can be categorized into two categories: 1) new groups, communities, support structures, and initiatives that have enabled broader work; and 2) high-level research contributions such as new datasets and models that allow others to build on them.
Research communities There are many languages with active existing research communities dedicated to them. These include languages with large speaker populations such as Japanese, Mandarin, Turkish, and Hindi as well as languages with fewer speakers such as Gaelic or Basque [1:2]. There have also been concerted efforts in the past to collect data for specific under-represented languages such as Inuktitut [58][59].
In the last few years, various new communities have emerged specializing in under-represented languages or language families. These include groups focusing on linguistic regions such as Masakhane for African languages, AmericasNLP for native American languages, IndoNLP for Indonesian languages, GhanaNLP and HausaNLP, among others. Events such as the Deep Learning Indaba, IndabaX, Khipu, EEML, SEAMLS, and ALPS, among many others and workshops such as AfricaNLP have enabled these communities to come together and complement longer-running events such as the Arabic NLP, ComputEL, and SIGTYP workshops.

At the same time, there are communities with broader focus areas such as ML Collective that have contributed to this space. One of the largest community-driven efforts in multilingual AI is BigScience, which has released BLOOM [43:1]. In many cases, projects in these communities have been participatory and highly collaborative [60][61], lowering the barrier to doing research and involving members of the community at every stage of the process.
Other communities such as Zindi or Data Science Nigeria have focused on hosting competitions and providing training courses while new programs such as the African Master's in Machine Intelligence seek to educate the next generation of AI researchers.
Initiatives The Association for Computational Linguistics (ACL) has emphasized the importance of language diversity, with a special theme track at the main ACL 2022 conference on this topic. The ACL has also launched the 60-60 initiative, which aims to make scientific content more accessible by creating a) translations of the entire ACL anthology into 60 languages; b) cross-lingual subtitling and dubbing for all plenary talks in 10 languages; and c) a comprehensive standardized scientific and NLP terminology list in 60 languages. The latter resource and glossaries for African languages could help to facilitate the discussion of language technology in local languages.
Datasets On the research side, there has been a flurry of new datasets covering a host of applications, from unlabeled speech and text corpora [62], to language identification [63], text classification [64], sentiment analysis [65], ASR, named entity recognition [61:1], question answering [66], and summarization [67] in a range of under-represented languages. New benchmarks seek to assess models on a broad set of tasks in Romanian [68], Korean [69], and Turkish [70], in geographically related languages such as Indonesian [71][72][73] or Indian languages [74], and in different modalities such as speech [75], image-grounded text [76], and text generation [77]. The development of these datasets has been enabled by new funding structures and initiatives such as the Lacuna Fund and FAIR Forward that have incentivized work in this area.

Other existing corpora have grown in their language coverage with community involvement: The Common Voice speech corpus [78] now covers 100 languages while the latest release of Universal Dependencies [39:1] includes 130 languages. Given the number of new datasets, there have been efforts to catalogue available datasets in African and Indonesian languages, Arabic, and a diverse set of languages [79].
Models New models developed in this area focus specifically on under-represented languages. There are text-based language models that focus on African languages such as AfriBERTa [80], AfroXLM-R [81], and KinyaBERT [82] and models for Indonesian languages such as IndoBERT [71:1][72:1] and IndoGPT [73:1]. For Indian languages, there are text-based models such as IndicBERT [74:1] and MuRIL [83] and speech models such as CLSRIL [84] and IndicWav2Vec [85]. Many of these approaches train a model on several related languages and are thus able to leverage positive transfer and to be much more efficient than larger multilingual models. See [86] and [87] for recent surveys of recent multilingual models in NLP and speech.
Industry In industry, startups have been developing new technology to serve local languages such as InstaDeep developing a model for Tunisian Arabic [88], Nokwary enabling financial inclusion in Ghanaian languages, BarefootLaw employing NLP technology to provide legal help in Uganda, and NeuralSpace building speech and text APIs for a geographically diverse set of languages, among many others.
Similarly, large tech companies have expanded their ASR and machine translation offerings. Both Google [89] and Meta [90] have described efforts on how to scale machine translation technology to the next thousand languages. At the heart of these efforts are a) mining high-quality monolingual data from the web based on improved language identification and filtering; b) training massively multilingual models on monolingual and parallel data; and c) extensive evaluation on newly collected datasets. These components are similarly important for building better ASR systems for under-represented languages [91].
Challenges and Opportunities
Given this recent progress, what are the remaining challenges and opportunities in this area?
Challenge #1: Limited Data
Arguably the biggest challenge in multilingual research is the limited amount of data available for most of the world's languages. Joshi et al. [92] categorized the languages of the world into six different categories based on the amount of labeled and unlabeled data available in them.

88% of the world's languages are in resource group 0 with virtually no text data available to them while 5% of languages are in resource group 1 where there is very limited text data available.
Opportunity #1: Real-world Data
How can we overcome this enormous discrepancy in the resource distribution across the world's languages? The creation of new data, particularly in languages with few annotators, is expensive. For this reason, many existing multilingual datasets such as XNLI [93], XQuAD [94], and XCOPA [95] are based on translations of established English datasets.
Such translation-based data, however, are problematic. Translated text in a language can be considered a dialect of that language, known as 'translationese', which differs from natural language [96]. Translation-based test sets may thus over-estimate the performance of models trained on similar data, which have learned to exploit translation artifacts [97].
Over-representation of Western concepts Beyond these issues, translating an existing dataset inherits the biases of the original data. In particular, translated data differs from data that is naturally created by speakers of different languages. As existing datasets were mostly created by crowdworkers or researchers based in Western countries, they mostly reflect Western-centric concepts. For example, ImageNet [98], one of the most influential datasets in ML, is based on English WordNet. As a result, it captures concepts that are overly English-specific and unknown in other cultures [99]. Similarly, Flickr30k [100] contains depictions of concepts that are mainly familiar to people from certain Western regions such as tailgating in the US [101].

The commonsense reasoning dataset COPA [102] contains many referents that have no language-specific terms in some languages, e.g., bowling ball, hamburger, and lottery [95:1]. Most questions in current QA datasets ask about US or UK nationals [103] while many other datasets, particularly those based on Wikipedia, contain mainly entities from Europe, the US, and the Middle East [104].
Practical data For new datasets, it is thus ever more important to create data that is informed by real-world usage. On the one hand, data should reflect the background of the speakers speaking the language. For example, MaRVL [105] is a multi-modal reasoning dataset that covers concepts representative of different cultures and languages.

Given the increasing maturity of language technology, it is important to collect data that is relevant for real-world applications and that may have a positive impact on speakers of under-represented languages. Such applications include the development of assistive language technology for humanitarian crises, health, education, legal, and finance. Languages that may benefit from such technology are standardised languages and contact languages, including creoles and regional language varieties [106].
Creating real-world datasets has the potential to ground research and enables it to have a larger impact. It also reduces the distribution shift between research and practical scenarios and makes it more likely that models developed on academic datasets will be useful in production.
Beyond the creation of the training or evaluation data, the development of a language model requires the involvement of a large number of stakeholders, many of whom are often not explicitly acknowledged. Many of the components in this process are under-performing and often not available in many languages.

This starts at the beginning of data creation where online platforms and keyboards may not support certain languages [57:1], dictionaries do not cover certain languages and language ID does not perform well in those languages [107]. In many languages, the connections between different stakeholders are also missing and it is difficult to find original content or to identify qualified annotators. The fact that text on the web is difficult to find for some languages does not mean, however, that these languages are resource-poor or that data for these languages does not exist.
Multi-modal data Many languages around the world are more commonly spoken than written. We can overcome the reliance (and lack of) text data by focusing on information from multi-modal data sources such as radio broadcasts and online videos as well as combining information from multiple modalities. Recent speech-and-text models [108][109] achieve strong improvements on speech tasks such as ASR, speech translation, and text-to-speech. They still perform more poorly, however, on text-only tasks due to a lack of capacity [110]. There is a lot of potential to leverage multi-modal data as well as to investigate the linguistic characteristics of different languages and their interplay in text and speech [111].

Beyond multi-modal information, data may also be available in formats that are locked to current models such as in handwritten documents and non-digitized books, among others. Technologies such as optical character recognition (OCR) [112] and new datasets such as the Bloom Library [113] will help us make such untapped data sources more accessible. There are also resources that have so far been used relatively little despite their large language coverage such as the Bible, which covers around 1,600 languages [114] and lexicons, which cover around 5,700 languages [115]. Other data sources may be readily available but have so far gone unused or unnoticed. Recent examples of such 'fortuitous data' [116] include HTML and web page structure [117][118], among others.
Given the generalization ability of pre-trained language models, benchmarks have been increasingly moving towards evaluation in low-resource settings. When creating new datasets, large test sets with sufficient statistical power [119] should thus be prioritized. In addition, languages for annotation can be prioritized based on the expected gain in utility [41:1] and reduction in inequality [120].
Finally, there are challenges for responsible AI when collecting data and developing technology for under-represented languages, including data governance, safety, privacy, and participation. Addressing these challenges requires answering questions such as: How are appropriate usage and ownership of the data and technology guaranteed [121]? Are there methods in place to detect and filter sensitive and biased data and detect bias in models? How is privacy preserved during data collection and usage? How can the data and technology development be made participatory [122]?
Challenge #2: Limited Compute
Under-represented language applications face constraints that go beyond the lack of data. Mobile data, compute, and other computational resources may often be expensive or unavailable. GPU servers, for instance, are scarce even in top universities in many countries [4:1] while the cost of mobile data is higher in countries where under-represented languages are spoken [123].

Opportunity #2: Efficiency
In order to make better use of limited compute, we must develop methods that are more efficient. For an overview of efficient Transformer architectures and efficient NLP methods in general refer to [124] and [125]. As pre-trained models are widely available, a promising direction is the adaptation of such models via parameter-efficient methods, which have been shown to be more effective than in-context learning [126].
A common method are adapters [127][128], small bottleneck layers that are inserted between a pre-trained model's weights. These parameter-efficient methods can be used to overcome the curse of multilinguality by enabling the allocation of additional language-specific capacity. They also enable the adaptation of a pre-trained multilingual model to languages that it has not been exposed to during pre-training [129][130]. As such adapter layers are separate from the remaining parameters of the model, they allow learning modular interactions between tasks and languages [131].

Adapters have been shown to improve robustness [132][133], lead to increased sample efficiency compared to fine-tuning [134], and outperform alternative parameter-efficient methods [135][136]. They allow for extensions such as incorporating hierarchical structure [137] or conditioning via hyper-networks [138][139].
Cross-lingual parameter-efficient transfer learning is not restricted to adapters but can take other forms [140] such as sparse sub-networks [141]. Such methods have been applied to a diverse set of applications and domains, from machine translation [142][143] to ASR [144] and speech translation [145].
Challenge #3: Language Typology
If we plot the typological features of the world's languages based on the World Atlas of Language Structures (WALS) and project them into two dimensions using PCA, we get a density plot such as the one below. Marking the languages that are present in Universal Dependencies [39:2], one of the most multilingual resources with red stars, we can observe that the languages for which data is available lie mostly in low-density regions of this plot. The distribution of languages in existing datasets is thus heavily skewed compared to the real-world distribution of languages and languages with available data are unrepresentative of most of the world's languages.

Under-represented languages have many linguistic features that are not present in Western languages. A common linguistic feature is tone, which is present in around 80% of African languages [111:1] and can be lexical or gramatical. In Yorùbá, lexical tone distinguishes meaning, for instance, in the following words: igbá ("calabash", "basket"), igba ("200"), ìgbà ("time"), ìgbá ("garden egg"), and igbà ("rope"). In Akan, grammatical tone distinguishes habitual and stative verbs such as for Ama dá ha ("Ama sleeps here") and Ama dà ha ("Ama is sleeping here"). Tone is relatively unexplored in speech and NLP applications.
While the typological features of languages around the world are diverse, languages within a region often share linguistic features. For instance, African languages mainly belong to a few major language families.

{kind=link}
Opportunity #3: Specialization
Rich Sutton highlights a bitter lesson for the field of AI research:
"The great power of general purpose methods [...] that continue to scale with increased computation [...]. The two methods that seem to scale arbitrarily: search and learning."
For most under-represented languages, computation and data, however, are limited. It is thus reasonable to incorporate (some amount of) knowledge into our language models to make them more useful for such languages.
This can take the form of biasing the tokenization process, which often produces poor segmentations for languages with a rich morphology or limited data. We can modify the algorithm to prefer tokens that are shared across many languages [146], preserve tokens’ morphological structure [147], or make the tokenization algorithm more robust to deal with erroneous segmentations [148].
We can also exploit the fact that many under-represented languages belong to groups of similar languages. Models focusing on such groups can thus more easily share information across languages. While recent models focus mainly on related languages [74:2][83:1][84:1], future models may also include language variants and dialects, which can benefit from positive transfer from related languages.
While principled variants of masking such as whole word masking [149] and PMI-masking [150] have been found useful in the past, new pre-training objectives that take linguistic characteristics such as rich morphology or tone into account may lead to more sample-efficient learning. Finally, the architeture of models can be adapted to incorporate information about morphology such as in the KinyaBERT model for Kinyarwanda [82:1].

Conclusion
While there has been a tremendous amount of progress in recent multilingual AI, there is still a lot more to do. Most importantly, we should focus on creating data that reflects the real-world circumstances of language speakers and to develop language technology that serves the needs of speakers around the world. While there is momentum and increasing awareness that such work is important, it takes a village to develop equitable language technology for the world's languages. Masakhane ("let us build together" in isiZulu)!
Citation
For attribution in academic contexts or books, please cite this work as:
Sebastian Ruder, "The State of Multilingual AI". http://ruder.io/state-of-multilingual-ai/, 2022.
BibTeX citation:
@misc{ruder2022statemultilingualai,
author = {Ruder, Sebastian},
title = {{The State of Multilingual AI}},
year = {2022},
howpublished = {\url{http://ruder.io/state-of-multilingual-ai/}},
}
van Esch, D., Lucassen, T., Ruder, S., Caswell, I., & Rivera, C. (2022). Writing System and Speaker Metadata for 2,800+ Language Varieties. Proceedings of LREC 2022, (June), 5035–5046. ↩︎ ↩︎ ↩︎
Bender, E. M. (2011). On Achieving and Evaluating Language-Independence in NLP. Linguistic Issues in Language Technology, 6(3), 1–26. ↩︎
Ruder, S., Vulić, I., & Søgaard, A. (2022). Square One Bias in NLP: Towards a Multi-Dimensional Exploration of the Research Manifold. In Findings of the Association for Computational Linguistics: ACL 2022 (pp. 2340–2354). ↩︎
Aji, A. F., Winata, G. I., Koto, F., Cahyawijaya, S., Romadhony, A., Mahendra, R., … Ruder, S. (2022). One Country, 700+ Languages: NLP Challenges for Underrepresented Languages and Dialects in Indonesia. In Proceedings of ACL 2022 (pp. 7226–7249). ↩︎ ↩︎
Vaswani, A., Shazeer, N., Parmar, N., Uszkoreit, J., Jones, L., Gomez, A. N., … Polosukhin, I. (2017). Attention Is All You Need. In Proceedings of NIPS 2017. ↩︎
Ruder, S., Peters, M., Swayamdipta, S., & Wolf, T. (2019). Transfer learning in natural language processing. Proceedings of NAACL 2019, Tutorial Abstracts. ↩︎
Dosovitskiy, A., Beyer, L., Kolesnikov, A., Weissenborn, D., Zhai, X., Unterthiner, T., … Houlsby, N. (2021). An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale. In Proceedings of ICLR 2021. ↩︎
Neimark, D., Bar, O., Zohar, M., & Asselmann, D. (2021). Video Transformer Network. In Proceedings of the IEEE International Conference on Computer Vision (Vol. 2021-Octob, pp. 3156–3165). https://doi.org/10.1109/ICCVW54120.2021.00355 ↩︎
Baevski, A., Zhou, H., Mohamed, A., & Auli, M. (2020). wav2vec 2.0: A framework for self-supervised learning of speech representations. In Advances in Neural Information Processing Systems. ↩︎
Devlin, J., Chang, M.-W., Lee, K., & Toutanova, K. (2019). BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. In Proceedings of NAACL 2019. http://arxiv.org/abs/1810.04805 ↩︎
Liu, Y., Ott, M., Goyal, N., Du, J., Joshi, M., Chen, D., … Stoyanov, V. (2019). RoBERTa: A Robustly Optimized BERT Pretraining Approach. ArXiv Preprint ArXiv:1907.11692. http://arxiv.org/abs/1907.11692 ↩︎
Lewis, M., Liu, Y., Goyal, N., Ghazvininejad, M., Mohamed, A., Levy, O., … Zettlemoyer, L. (2019). BART: Denoising Sequence-to-Sequence Pre-training for Natural Language Generation, Translation, and Comprehension. In Proceedings of ACL 2019. ↩︎
Raffel, C., Shazeer, N., Roberts, A., Lee, K., Narang, S., Matena, M., … Liu, P. J. (2020). Exploring the Limits of Transfer Learning with a Unified Text-to-Text Transformer. Journal of Machine Learning Research, 21. http://arxiv.org/abs/1910.10683 ↩︎
He, P., Gao, J., & Chen, W. (2021). DeBERTaV3: Improving DeBERTa using electra-style pre-training with gradient-disentangled embedding sharing. arXiv preprint arXiv:2111.09543. ↩︎ ↩︎
Baevski, A., Zhou, Y., Mohamed, A., & Auli, M. (2020). wav2vec 2.0: A framework for self-supervised learning of speech representations. Advances in Neural Information Processing Systems, 33, 12449-12460. ↩︎
Chung, H. W., Févry, T., Tsai, H., Johnson, M., & Ruder, S. (2021). Rethinking Embedding Coupling in Pre-trained Language Models. In Proceedings of ICLR 2021. ↩︎
Conneau, A., Khandelwal, K., Goyal, N., Chaudhary, V., Wenzek, G., Guzmán, F., … Stoyanov, V. (2020). Unsupervised Cross-lingual Representation Learning at Scale. In Proceedings of ACL 2020. http://arxiv.org/abs/1911.02116 ↩︎ ↩︎
Liu, Y., Gu, J., Goyal, N., Li, X., Edunov, S., Ghazvininejad, M., ... & Zettlemoyer, L. (2020). Multilingual denoising pre-training for neural machine translation. Transactions of the Association for Computational Linguistics, 8, 726-742. ↩︎
Xue, L., Constant, N., Roberts, A., Kale, M., Al-Rfou, R., Siddhant, A., … Raffel, C. (2021). mT5: A massively multilingual pre-trained text-to-text transformer. In Proceedings of NAACL 2021. http://arxiv.org/abs/2010.11934 ↩︎
Dufter, P., & Schütze, H. (2020). Identifying Elements Essential for BERT’s Multilinguality. In Proceedings of EMNLP 2020. ↩︎
Deshpande, A., Talukdar, P., & Narasimhan, K. (2022). When is BERT Multilingual? Isolating Crucial Ingredients for Cross-lingual Transfer. In Proceedings of NAACL 2022. ↩︎
Rust, P., Pfeiffer, J., Vulić, I., Ruder, S., & Gurevych, I. (2021). How Good is Your Tokenizer? On the Monolingual Performance of Multilingual Language Models. In Proceedings of ACL 2021. ↩︎
Conneau, A., Baevski, A., Collobert, R., Mohamed, A., & Auli, M. (2021). Unsupervised Cross-lingual Representation Learning for Speech Recognition. In Proceedings of Interspeech 2021. ↩︎
Wang, C., Wu, Y., Qian, Y., Kumatani, K., Liu, S., Wei, F., ... & Huang, X. (2021, July). Unispeech: Unified speech representation learning with labeled and unlabeled data. In International Conference on Machine Learning (pp. 10937-10947). PMLR. ↩︎
Goyal, N., Du, J., Ott, M., Anantharaman, G., & Conneau, A. (2021). Larger-Scale Transformers for Multilingual Masked Language Modeling. In Proceedings of the 6th Workshop on Representation Learning for NLP (RepL4NLP-2021). ↩︎
Hu, J., Ruder, S., Siddhant, A., Neubig, G., Firat, O., & Johnson, M. (2020). XTREME: A Massively Multilingual Multi-task Benchmark for Evaluating Cross-lingual Generalization. In Proceedings of ICML 2020. ↩︎ ↩︎
Lauscher, A., Ravishankar, V., Vulić, I., & Glavaš, G. (2020). From Zero to Hero: On the Limitations of Zero-Shot Cross-Lingual Transfer with Multilingual Transformers. In Proceedings of EMNLP 2020. ↩︎
Ahuja, K., Kumar, S., Dandapat, S., & Choudhury, M. (2022). Multi Task Learning For Zero Shot Performance Prediction of Multilingual Models. In Proceedings of ACL 2022 (pp. 5454–5467). ↩︎
Muller, B., Anastasopoulos, A., Sagot, B., & Seddah, D. (2021). When Being Unseen from mBERT is just the Beginning: Handling New Languages With Multilingual Language Models. In Proceedings of NAACL 2021. ↩︎
Pfeiffer, J., Vulić, I., Gurevych, I., & Ruder, S. (2021). UNKs Everywhere: Adapting Multilingual Language Models to New Scripts. In Proceedings of EMNLP 2021. ↩︎
Pan, X., Zhang, B., May, J., Nothman, J., Knight, K., & Ji, H. (2017). Cross-lingual name tagging and linking for 282 languages. In Proceedings of ACL 2017 (pp. 1946–1958). https://doi.org/10.18653/v1/P17-1178 ↩︎ ↩︎
Lignos, C., Holley, N., Palen-Michel, C., & Sälevä, J. (2022). Toward More Meaningful Resources for Lower-resourced Languages. In Findings of ACL 2022 (pp. 523–532). ↩︎
Kreutzer, J., Caswell, I., Wang, L., Wahab, A., Van Esch, D., Ulzii-Orshikh, N., … Adeyemi, M. (2022). Quality at a Glance: An Audit of Web-Crawled Multilingual Datasets. In Proceedings of ACL 2022 (Vol. 10, pp. 50–72). ↩︎
Schwenk, H., Chaudhary, V., Sun, S., Gong, H., & Guzmán, F. (2019). WikiMatrix: Mining 135M Parallel Sentences. arXiv preprint arXiv:1907.05791. ↩︎
El-Kishky, A., Chaudhary, V., Guzmán, F., & Koehn, P. (2020). CCAligned: A massive collection of cross-lingual web-document Pairs. In Proceedings of EMNLP 2020, 5960–5969. ↩︎
Artetxe, M., Aldabe, I., Agerri, R., Perez-de-Viñaspre, O., & Soroa, A. (2022). Does Corpus Quality Really Matter for Low-Resource Languages? arXiv preprint arXiv:2203.08111. ↩︎
Wang, A., Singh, A., Michael, J., Hill, F., Levy, O., & Bowman, S. R. (2019). GLUE: A Multi-Task Benchmark and Analysis Platform for Natural Language Understanding. In Proceedings of ICLR 2019. ↩︎
Wang, A., Michael, J., Hill, F., Levy, O., & Bowman, S. R. (2019). SuperGLUE: A Stickier Benchmark for General-Purpose Language Understanding Systems. In Proceedings of NeurIPS 2019. ↩︎
De Marneffe, M. C., Manning, C. D., Nivre, J., & Zeman, D. (2021). Universal dependencies. Computational linguistics, 47(2), 255-308. ↩︎ ↩︎ ↩︎
Artetxe, M., & Schwenk, H. (2019). Massively Multilingual Sentence Embeddings for Zero-Shot Cross-Lingual Transfer and Beyond. Transactions of the ACL 2019. http://arxiv.org/abs/1812.10464 ↩︎
Blasi, D., Anastasopoulos, A., & Neubig, G. (2022). Systematic Inequalities in Language Technology Performance across the World’s Languages. In Proceedings of ACL 2022. ↩︎ ↩︎
Ahuja, K., Kumar, S., Dandapat, S., & Choudhury, M. (2022). Multi Task Learning For Zero Shot Performance Prediction of Multilingual Models. In Proceedings of ACL 2022. ↩︎
Scao, T. L., Fan, A., Akiki, C., Pavlick, E., Ilić, S., Hesslow, D., ... & Manica, M. (2022). BLOOM: A 176B-Parameter Open-Access Multilingual Language Model. arXiv preprint arXiv:2211.05100. ↩︎ ↩︎
Brown, T. B., Mann, B., Ryder, N., Subbiah, M., Kaplan, J., Dhariwal, P., … Amodei, D. (2020). Language models are few-shot learners. In Proceedings of NeurIPS 2020. ↩︎
Chowdhery, A., Narang, S., Devlin, J., Bosma, M., Mishra, G., Roberts, A., … Fiedel, N. (2022). PaLM: Scaling Language Modeling with Pathways. ↩︎
Winata, G. I., Madotto, A., Lin, Z., Liu, R., Yosinski, J., & Fung, P. (2021). Language Models are Few-shot Multilingual Learners. In Proceedings ofthe 1st Workshop on Multilingual Representation Learning. ↩︎
Lin, X. V., Mihaylov, T., Artetxe, M., Wang, T., Chen, S., Simig, D., … Li, X. (2022). Few-shot Learning with Multilingual Language Models. In Proceedings of EMNLP 2022. ↩︎
Shi, F., Suzgun, M., Freitag, M., Wang, X., Srivats, S., Vosoughi, S., ... & Wei, J. (2022). Language models are multilingual chain-of-thought reasoners. arXiv preprint arXiv:2210.03057. ↩︎
Hsu, W. N., Bolte, B., Tsai, Y. H. H., Lakhotia, K., Salakhutdinov, R., & Mohamed, A. (2021). HuBERT: Self-supervised speech representation learning by masked prediction of hidden units. IEEE/ACM Transactions on Audio, Speech, and Language Processing, 29, 3451-3460. ↩︎
Chen, S., Wang, C., Chen, Z., Wu, Y., Liu, S., Chen, Z., ... & Wei, F. (2022). WavLM: Large-scale self-supervised pre-training for full stack speech processing. IEEE Journal of Selected Topics in Signal Processing, 16(6), 1505-1518. ↩︎
Alayrac, J. B., Donahue, J., Luc, P., Miech, A., Barr, I., Hasson, Y., ... & Simonyan, K. (2022). Flamingo: a visual language model for few-shot learning. In Proceedings of NeurIPS 2022. ↩︎
Ramesh, A., Dhariwal, P., Nichol, A., Chu, C., & Chen, M. (2022). Hierarchical text-conditional image generation with CLIP latents. arXiv preprint arXiv:2204.06125. ↩︎
Saharia, C., Chan, W., Saxena, S., Li, L., Whang, J., Denton, E., ... & Norouzi, M. (2022). Photorealistic Text-to-Image Diffusion Models with Deep Language Understanding. arXiv preprint arXiv:2205.11487. ↩︎
Yu, J., Xu, Y., Koh, J. Y., Luong, T., Baid, G., Wang, Z., ... & Wu, Y. (2022). Scaling autoregressive models for content-rich text-to-image generation. arXiv preprint arXiv:2206.10789. ↩︎
Radford, A., Kim, J. W., Xu, T., Brockman, G., McLeavey, C., & Sutskever, I. (2022). Robust speech recognition via large-scale weak supervision. Tech. Rep., Technical report, OpenAI. ↩︎
Chen, X., Wang, X., Changpinyo, S., Piergiovanni, A. J., Padlewski, P., Salz, D., ... & Soricut, R. (2022). PaLI: A jointly-scaled multilingual language-image model. arXiv preprint arXiv:2209.06794. ↩︎
van Esch, D., Sarbar, E., Lucassen, T., Brien, J. O., Breiner, T., Prasad, M., … Beaufays, F. (2019). Writing Across the World’s Languages: Deep Internationalization for Gboard, the Google Keyboard. ↩︎ ↩︎
Joanis, E., Knowles, R., Kuhn, R., Larkin, S., Littell, P., Lo, C. K., … Micher, J. (2020). The Nunavut Hansard Inuktitut-English Parallel Corpus 3.0 with Preliminary Machine Translation Results. In LREC 2020 - 12th International Conference on Language Resources and Evaluation, Conference Proceedings (pp. 2562–2572). ↩︎
Barrault, L., Biesialska, M., Costa-jussà, M. R., Federmann, C., Huck, M., Joanis, E., … Post, M. (2020). Findings of the 2020 Conference on Machine Translation (WMT20). In Proceedings ofthe 5th Conference on Machine Translation (WMT). ↩︎
Nekoto, W., Marivate, V., Matsila, T., Fasubaa, T., Kolawole, T., Fagbohungbe, T., … Bashir, A. (2020). Participatory Research for Low-resourced Machine Translation: A Case Study in African Languages. In Findings of EMNLP 2020. ↩︎
Adelani, D. I., Abbott, J., Neubig, G., Daniel, D., Kreutzer, J., Lignos, C., … Ogueji, K. (2021). MasakhaNER: Named Entity Recognition for African Languages. Transactions of the ACL 2021. ↩︎ ↩︎
Wanjawa, B., Wanzare, L., Indede, F., McOnyango, O., Ombui, E., & Muchemi, L. (2022). Kencorpus: A Kenyan Language Corpus of Swahili, Dholuo and Luhya for Natural Language Processing Tasks. arXiv preprint arXiv:2208.12081. ↩︎
Adebara, I., Elmadany, A., Abdul-Mageed, M., & Inciarte, A. A. (2022). AfroLID: A Neural Language Identification Tool for African Languages. In Proceedings of EMNLP 2022. ↩︎
Niyongabo, R. A., Qu, H., Kreutzer, J., & Huang, L. (2020). KinNews and KirNews: Benchmarking Cross-Lingual Text Classification for Kinyarwanda and Kirundi. In Proceedings of COLING 2020 (pp. 5507–5521). ↩︎
Muhammad, S. H., Adelani, D. I., Ruder, S., Ahmad, I. S., Abdulmumin, I., Bello, B. S., … Brazdil, P. (2022). NaijaSenti: A Nigerian Twitter Sentiment Corpus for Multilingual Sentiment Analysis. In Proceedings of LREC 2022 (pp. 590–602). ↩︎
Wanjawa, B., Wanzare, L., Indede, F., McOnyango, O., Muchemi, L., & Ombui, E. (2022). KenSwQuAD--A Question Answering Dataset for Swahili Low Resource Language. arXiv preprint arXiv:2205.02364. ↩︎
MBONU, C. E., Chukwuneke, C. I., Paul, R. U., Ezeani, I., & Onyenwe, I. (2022, March). IgboSum1500-Introducing the Igbo Text Summarization Dataset. In 3rd Workshop on African Natural Language Processing. ↩︎
Dumitrescu, S. D., Rebeja, P., Lorincz, B., Gaman, M., Avram, A., Ilie, M., ... & Patraucean, V. (2021, June). Liro: Benchmark and leaderboard for Romanian language tasks. In Thirty-fifth Conference on Neural Information Processing Systems Datasets and Benchmarks Track (Round 1). ↩︎
Park, S., Moon, J., Kim, S., Cho, W. I., Han, J., Park, J., ... & Cho, K. (2021). KLUE: Korean language understanding evaluation. arXiv preprint arXiv:2105.09680. ↩︎
Safaya, A., Kurtuluş, E., Goktogan, A., & Yuret, D. (2022). Mukayese: Turkish NLP Strikes Back. In Findings of ACL 2022 (pp. 846–863). ↩︎
Wilie, B., Vincentio, K., Winata, G. I., Cahyawijaya, S., Li, X., Lim, Z. Y., … Purwarianti, A. (2020). IndoNLU: Benchmark and Resources for Evaluating Indonesian Natural Language Understanding. In Proceedings of AACL-IJCNLP 2020. ↩︎ ↩︎
Koto, F., Rahimi, A., Lau, J. H., & Baldwin, T. (2020). IndoLEM and IndoBERT: A Benchmark Dataset and Pre-trained Language Model for Indonesian NLP. In Proceedings of COLING 2020 (pp. 757–770). ↩︎ ↩︎
Cahyawijaya, S., Winata, G. I., Wilie, B., Vincentio, K., Li, X., Kuncoro, A., … Fung, P. (2021). IndoNLG: Benchmark and Resources for Evaluating Indonesian Natural Language Generation. In Proceedings of EMNLP 2021 (pp. 8875–8898). ↩︎ ↩︎
Kakwani, D., Kunchukuttan, A., Golla, S., Gokul, N. C., Bhattacharyya, A., Khapra, M. M., & Kumar, P. (2020). IndicNLPSuite: Monolingual corpora, evaluation benchmarks and pre-trained multilingual language models for Indian languages. In Findings of the Association for Computational Linguistics: EMNLP 2020 (pp. 4948-4961). ↩︎ ↩︎ ↩︎
Conneau, A., Bapna, A., Zhang, Y., Ma, M., von Platen, P., Lozhkov, A., … Johnson, M. (2022). XTREME-S: Evaluating Cross-lingual Speech Representations. In Proceedings of Interspeech 2022. ↩︎
Bugliarello, E., Liu, F., Pfeiffer, J., Reddy, S., Elliott, D., Ponti, E. M., & Vulić, I. (2022). IGLUE: A Benchmark for Transfer Learning across Modalities, Tasks, and Languages. In Proceedings of ICML 2022. ↩︎
Gehrmann, S., Bhattacharjee, A., Mahendiran, A., Wang, A., Papangelis, A., Madaan, A., ... & Hou, Y. (2022). GEMv2: Multilingual NLG benchmarking in a single line of code. arXiv preprint arXiv:2206.11249. ↩︎
Ardila, R., Branson, M., Davis, K., Henretty, M., Kohler, M., Meyer, J., … Weber, G. (2020). Common Voice: A massively-multilingual speech corpus. In LREC 2020 - 12th International Conference on Language Resources and Evaluation, Conference Proceedings (pp. 4218–4222). ↩︎
McMillan-Major, A., Alyafeai, Z., Biderman, S., Chen, K., De Toni, F., Dupont, G., ... & Jernite, Y. (2022). Documenting geographically and contextually diverse data sources: The BigScience catalogue of language data and resources. arXiv preprint arXiv:2201.10066. ↩︎
Ogueji, K., Zhu, Y., & Lin, J. (2021). Small Data? No Problem! Exploring the Viability of Pretrained Multilingual Language Models for Low-Resource Languages. In Proceedings of Multilingual Representation Learning Workshop 2021. ↩︎
Alabi, J. O., Adelani, D. I., Mosbach, M., & Klakow, D. (2022). Multilingual Language Model Adaptive Fine-Tuning: A Study on African Languages. In Proceedings of COLING 2022. http://arxiv.org/abs/2204.06487 ↩︎
Nzeyimana, A., & Rubungo, A. N. (2022). KinyaBERT: a Morphology-aware Kinyarwanda Language Model. In Proceedings of ACL 2022. ↩︎ ↩︎
Khanuja, S., Bansal, D., Mehtani, S., Khosla, S., Dey, A., Gopalan, B., ... & Talukdar, P. (2021). MuRIL: Multilingual representations for indian languages. arXiv preprint arXiv:2103.10730. ↩︎ ↩︎
Gupta, A., Chadha, H. S., Shah, P., Chhimwal, N., Dhuriya, A., Gaur, R., & Raghavan, V. (2021). CLSRIL-23: Cross lingual speech representations for indic languages. arXiv preprint arXiv:2107.07402. ↩︎ ↩︎
Javed, T., Doddapaneni, S., Raman, A., Bhogale, K. S., Ramesh, G., Kunchukuttan, A., ... & Khapra, M. M. (2022, June). Towards building ASR systems for the next billion users. In Proceedings of the AAAI Conference on Artificial Intelligence (Vol. 36, No. 10, pp. 10813-10821). ↩︎
Doddapaneni, S., Ramesh, G., Kunchukuttan, A., Kumar, P., & Khapra, M. M. (2021). A primer on pretrained multilingual language models. arXiv preprint arXiv:2107.00676. ↩︎
Yadav, H., & Sitaram, S. (2022). A Survey of Multilingual Models for Automatic Speech Recognition. In Proceedings of LREC 2022. ↩︎
Messaoudi, A., Cheikhrouhou, A., Haddad, H., Ferchichi, N., BenHajhmida, M., Korched, A., ... & Kerkeni, A. (2022). Tunbert: Pretrained contextualized text representation for tunisian dialect. In International Conference on Intelligent Systems and Pattern Recognition (pp. 278-290). ↩︎
Bapna, A., Caswell, I., Kreutzer, J., Firat, O., van Esch, D., Siddhant, A., … Hughes, M. (2022). Building Machine Translation Systems for the Next Thousand Languages. ↩︎
Team, N., Costa-jussà, M. R., Cross, J., Çelebi, O., Elbayad, M., Heafield, K., … Wang, J. (2022). No Language Left Behind: Scaling Human-Centered Machine Translation. https://github.com/facebookresearch/fairseq/tree/nllb ↩︎
Ritchie, S., Cheng, Y. C., Chen, M., Mathews, R., van Esch, D., Li, B., & Sim, K. C. (2022). Large vocabulary speech recognition for languages of Africa: multilingual modeling and self-supervised learning. arXiv preprint arXiv:2208.03067. ↩︎
Joshi, P., Santy, S., Budhiraja, A., Bali, K., & Choudhury, M. (2020). The State and Fate of Linguistic Diversity and Inclusion in the NLP World. In Proceedings of ACL 2020. ↩︎
Conneau, A., Lample, G., Rinott, R., Williams, A., Bowman, S. R., Schwenk, H., & Stoyanov, V. (2018). XNLI: Evaluating Cross-lingual Sentence Representations. In Proceedings of EMNLP 2018. ↩︎
Artetxe, M., Ruder, S., & Yogatama, D. (2020). On the Cross-lingual Transferability of Monolingual Representations. In Proceedings of ACL 2020. ↩︎
Ponti, E. M., Glavaš, G., Majewska, O., Liu, Q., Vulić, I., & Korhonen, A. (2020). XCOPA: A Multilingual Dataset for Causal Commonsense Reasoning. In Proceedings of EMNLP 2020. ↩︎ ↩︎
Volansky, V., Ordan, N., & Wintner, S. (2015). On the features of translationese. Digital Scholarship in the Humanities, 30(1), 98-118. ↩︎
Artetxe, M., Labaka, G., & Agirre, E. (2020). Translation Artifacts in Cross-lingual Transfer Learning. In Proceedings of EMNLP 2020. ↩︎
Russakovsky, O., Deng, J., Su, H., Krause, J., Satheesh, S., Ma, S., … & Fei-Fei, L. (2015). Imagenet large scale visual recognition challenge. International journal of computer vision, 115(3), 211-252. ↩︎
Liu, F., Bugliarello, E., Ponti, E. M., Reddy, S., Collier, N., & Elliott, D. (2021). Visually Grounded Reasoning across Languages and Cultures. In Proceedings of EMNLP 2021. ↩︎
Young, P., Lai, A., Hodosh, M., & Hockenmaier, J. (2014). From image descriptions to visual denotations: New similarity metrics for semantic inference over event descriptions. Transactions of the Association for Computational Linguistics, 2, 67-78. ↩︎
Van Miltenburg, E., Elliott, D., & Vossen, P. (2017). Cross-linguistic differences and similarities in image descriptions. In INLG 2017 - 10th International Natural Language Generation Conference, Proceedings of the Conference (pp. 21–30). ↩︎
Roemmele, M., Bejan, C. A., & Gordon, A. S. (2011). Choice of Plausible Alternatives: An Evaluation of Commonsense Causal Reasoning. In AAAI spring symposium: logical formalizations of commonsense reasoning. ↩︎
Gor, M., & Webster, K. (2021). Toward Deconfounding the Influence of Entity Demographics for Question Answering Accuracy. In Proceedings of EMNLP 2021. ↩︎
Faisal, F., Wang, Y., & Anastasopoulos, A. (2022). Dataset Geography: Mapping Language Data to Language Users. In Proceedings of ACL 2022. ↩︎
Liu, F., Bugliarello, E., Ponti, E. M., Reddy, S., Collier, N., & Elliott, D. (2021). Visually Grounded Reasoning across Languages and Cultures. In Proceedings of EMNLP 2021. ↩︎
Bird, S. (2022). Local Languages, Third Spaces, and other High-Resource Scenarios. In Proceedings of ACL 2022. ↩︎
Caswell, I., Breiner, T., van Esch, D., & Bapna, A. (2020). Language ID in the Wild: Unexpected Challenges on the Path to a Thousand-Language Web Text Corpus. In Proceedings of COLING 2020 (pp. 6588–6608). ↩︎
Chen, Z., Zhang, Y., Rosenberg, A., Ramabhadran, B., Moreno, P. J., Bapna, A., & Zen, H. (2022). MAESTRO: Matched Speech Text Representations through Modality Matching. In Proceedings of Interspeech 2022. ↩︎
Saeki, T., Zen, H., Chen, Z., Morioka, N., Wang, G., Zhang, Y., … Ramabhadran, B. (2022). Virtuoso: Massive Multilingual Speech-Text Joint Semi-Supervised Learning for Text-To-Speech. arXiv preprint arXiv:2210.15447. ↩︎
Bapna, A., Cherry, C., Zhang, Y., Jia, Y., Johnson, M., Cheng, Y., ... & Conneau, A. (2022). mSLAM: Massively multilingual joint pre-training for speech and text. arXiv preprint arXiv:2202.01374. ↩︎
Adebara, I., & Abdul-Mageed, M. (2022). Towards Afrocentric NLP for African Languages: Where We Are and Where We Can Go. In Proceedings of ACL 2022. ↩︎ ↩︎
Rijhwani, S., Anastasopoulos, A., & Neubig, G. (2020). OCR Post Correction for Endangered Language Texts. In Proceedings of EMNLP 2020. ↩︎
Leong, C., Nemecek, J., Mansdorfer, J., Filighera, A., Owodunni, A., & Whitenack, D. (2022). Bloom Library: Multimodal Datasets in 300+ Languages for a Variety of Downstream Tasks. In Proceedings of EMNLP 2022. ↩︎
Ebrahimi, A., & Kann, K. (2021). How to Adapt Your Pretrained Multilingual Model to 1600 Languages. In Proceedings of ACL 2021. ↩︎
Wang, X., Ruder, S., & Neubig, G. (2022). Expanding Pretrained Models to Thousands More Languages via Lexicon-based Adaptation. In Proceedings of ACL 2022. ↩︎
Plank, B. Processing non-canonical or noisy text: fortuitous data to the rescue. In Proceedings of the 2nd Workshop on Noisy User-generated Text (WNUT). ↩︎
Aghajanyan, A., Okhonko, D., Lewis, M., Joshi, M., Xu, H., Ghosh, G., & Zettlemoyer, L. (2021). HTLM: Hyper-text pre-training and prompting of language models. arXiv preprint arXiv:2107.06955. ↩︎
Varab, D., & Schluter, N.. MassiveSumm: a very large-scale, very multilingual, news summarisation dataset. In Proceedings of EMNLP 2021. ↩︎
Card, D., Henderson, P., Khandelwal, U., Jia, R., Mahowald, K., & Jurafsky, D. (2020). With Little Power Comes Great Responsibility. In Proceedings of EMNLP 2020. ↩︎
Khanuja, S., Ruder, S., & Talukdar, P. (2022). Evaluating Inclusivity, Equity, and Accessibility of NLP Technology: A Case Study for Indian Languages. arXiv preprint arXiv:2205.12676. ↩︎
Abebe, R., Aruleba, K., Birhane, A., Kingsley, S., Obaido, G., Remy, S. L., & Sadagopan, S. (2021). Narratives and Counternarratives on Data Sharing in Africa. In Conference on Fairness, Accountability, and Transparency (FAccT ’21). Association for Computing Machinery. ↩︎
Birhane, A., Isaac, W., Prabhakaran, V., Díaz, M., Elish, M. C., Gabriel, I., & Mohamed, S. (2022). Power to the People? Opportunities and Challenges for Participatory AI. Equity and Access in Algorithms, Mechanisms, and Optimization. ↩︎
Ahia, O., Kreutzer, J., & Hooker, S. (2021). The Low-Resource Double Bind: An Empirical Study of Pruning for Low-Resource Machine Translation. In Findings of EMNLP 2021. ↩︎
Tay, Y., Dehghani, M., Bahri, D., & Metzler, D. (2020). Efficient transformers: A survey. ACM Computing Surveys (CSUR). ↩︎
Treviso, M., Ji, T., Lee, J. U., van Aken, B., Cao, Q., Ciosici, M. R., ... & Schwartz, R. (2022). Efficient Methods for Natural Language Processing: A Survey. arXiv preprint arXiv:2209.00099. ↩︎
Liu, H., Tam, D., Muqeeth, M., Mohta, J., Huang, T., Bansal, M., & Raffel, C. (2022). Few-shot parameter-efficient fine-tuning is better and cheaper than in-context learning. arXiv preprint arXiv:2205.05638. ↩︎
Rebuffi, S. A., Bilen, H., & Vedaldi, A. (2017). Learning multiple visual domains with residual adapters. Advances in Neural Information Processing Systems, 30. ↩︎
Houlsby, N., Giurgiu, A., Jastrzebski, S., Morrone, B., De Laroussilhe, Q., Gesmundo, A., ... & Gelly, S. (2019, May). Parameter-efficient transfer learning for NLP. In International Conference on Machine Learning (pp. 2790-2799). PMLR. ↩︎
Pfeiffer, J., Vulić, I., Gurevych, I., & Ruder, S. (2021). UNKs Everywhere: Adapting Multilingual Language Models to New Scripts. In Proceedings of EMNLP 2021. ↩︎
Pfeiffer, J., Goyal, N., Lin, X. V., Li, X., Cross, J., Riedel, S., & Artetxe, M. (2022). Lifting the Curse of Multilinguality with Modular Transformers. In Proceedings of NAACL 2022. ↩︎
Pfeiffer, J., Vulić, I., Gurevych, I., & Ruder, S. (2020). MAD-X: An Adapter-based Framework for Multi-task Cross-lingual Transfer. In Proceedings of EMNLP 2020. ↩︎
He, R., Liu, L., Ye, H., Tan, Q., Ding, B., Cheng, L., … Si, L. (2021). On the Effectiveness of Adapter-based Tuning for Pretrained Language Model Adaptation. In Proceedings of ACL 2021. ↩︎
Han, W., Pang, B., & Wu, Y. (2021). Robust Transfer Learning with Pretrained Language Models through Adapters. In Proceedings of ACL 2021. ↩︎
Mahabadi, R. K., Ruder, S., Dehghani, M., & Henderson, J. (2021). Parameter-efficient Multi-task Fine-tuning for Transformers via Shared Hypernetworks. In Proceedings of ACL 2021. ↩︎
Mahabadi, R. K., Henderson, J., & Ruder, S. (2021). Compacter: Efficient Low-Rank Hypercomplex Adapter Layers. In Proceedings of NeurIPS 2021. ↩︎
Mahabadi, R. K., Zettlemoyer, L., Henderson, J., Saeidi, M., Mathias, L., Stoyanov, V., & Yazdani, M. (2022). PERFECT: Prompt-free and Efficient Few-shot Learning with Language Models. In Proceedings of ACL 2022. ↩︎
Chronopoulou, A., Peters, M. E., & Dodge, J. (2022). Efficient Hierarchical Domain Adaptation for Pretrained Language Models. In Proceedings of NAACL 2022. ↩︎
Ansell, A., Ponti, E. M., Pfeiffer, J., Ruder, S., Glavaš, G., Vulić, I., & Korhonen, A. (2021). MAD-G: Multilingual Adapter Generation for Efficient Cross-Lingual Transfer. In Findings of EMNLP 2021. ↩︎
Üstün, A., Bisazza, A., Bouma, G., van Noord, G., & Ruder, S. (2022). Hyper-X: A Unified Hypernetwork for Multi-Task Multilingual Transfer. In Proceedings of EMNLP 2022. ↩︎
He, J., Zhou, C., Ma, X., Berg-Kirkpatrick, T., & Neubig, G. (2022). Towards a Unified View of Parameter-Efficient Transfer Learning. Proceedings of ICLR 2022. ↩︎
Ansell, A., Ponti, E. M., Korhonen, A., & Vulić, I. (2022). Composable Sparse Fine-Tuning for Cross-Lingual Transfer. In Proceedings of ACL 2022. ↩︎
Bapna, A., & Firat, O. (2019). Simple, Scalable Adaptation for Neural Machine Translation. In Proceedings of EMNLP 2019. ↩︎
Üstün, A., Bérard, A., Besacier, L., & Gallé, M. (2021). Multilingual Unsupervised Neural Machine Translation with Denoising Adapters. In Proceedings of EMNLP 2021. ↩︎
Lu, Y., Huang, M., Qu, X., Wei, P., & Ma, Z. (2022, May). Language adaptive cross-lingual speech representation learning with sparse sharing sub-networks. In ICASSP 2022-2022 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). ↩︎
Le, H., Pino, J., Wang, C., Gu, J., Schwab, D., & Besacier, L. (2021). Lightweight Adapter Tuning for Multilingual Speech Translation. In Proceedings of ACL 2021. ↩︎
Patil, V., Talukdar, P., & Sarawagi, S. (2022). Overlap-based Vocabulary Generation Improves Cross-lingual Transfer Among Related Languages. In Proceedings of ACL 2022. ↩︎
Hofmann, V., Schütze, H., & Pierrehumbert, J. B. (2022). An Embarrassingly Simple Method to Mitigate Undesirable Properties of Pretrained Language Model Tokenizers. In Proceedings of ACL 2022. ↩︎
Wang, X., Ruder, S., & Neubig, G. (2021). Multi-view Subword Regularization. In Proceedings of NAACL 2021. ↩︎
Cui, Y., Che, W., Liu, T., Qin, B., & Yang, Z. (2021). Pre-training with whole word masking for chinese bert. IEEE/ACM Transactions on Audio, Speech, and Language Processing, 29, 3504-3514. ↩︎
Levine, Y., Leyton-brown, K., Labs, A. I., & Aviv, T. (2021). PMI-Masking: Principled Masking of Correlated Spans. In Proceedings of ICLR 2021. ↩︎