Recent Advances in Language Model Fine-tuning
This article provides an overview of recent methods to fine-tune large pre-trained language models.

Fine-tuning a pre-trained language model (LM) has become the de facto standard for doing transfer learning in natural language processing. Over the last three years (Ruder, 2018), fine-tuning (Howard & Ruder, 2018) has superseded the use of feature extraction of pre-trained embeddings (Peters et al., 2018) while pre-trained language models are favoured over models trained on translation (McCann et al., 2018), natural language inference (Conneau et al., 2017), and other tasks due to their increased sample efficiency and performance (Zhang and Bowman, 2018). The empirical success of these methods has led to the development of ever larger models (Devlin et al., 2019; Raffel et al., 2020). Recent models are so large in fact that they can achieve reasonable performance without any parameter updates (Brown et al., 2020). The limitations of this zero-shot setting (see this section), however, make it likely that in order to achieve the best performance or stay reasonably efficient, fine-tuning will continue to be the modus operandi when using large pre-trained LMs in practice.
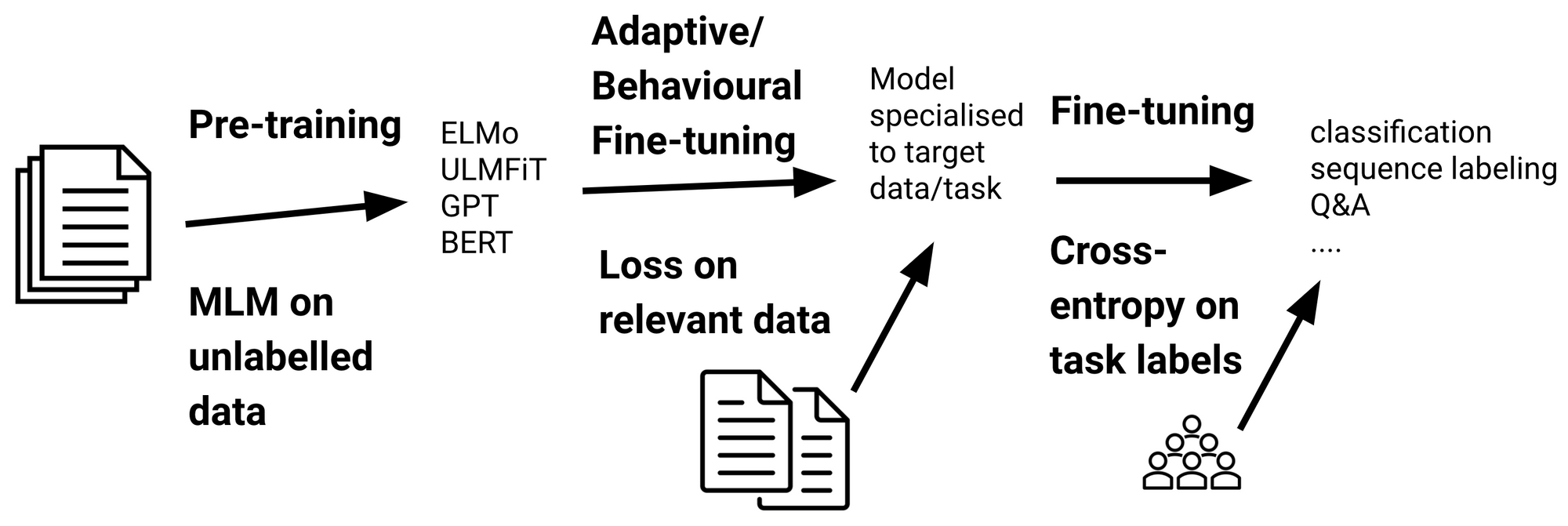
In the standard transfer learning setup (see below; see this post for a general overview), a model is first pre-trained on large amounts of unlabelled data using a language modelling loss such as masked language modelling (MLM; Devlin et al., 2019). The pre-trained model is then fine-tuned on labelled data of a downstream task using a standard cross-entropy loss.
While pre-training is compute-intensive, fine-tuning can be done comparatively inexpensively. Fine-tuning is more important for the practical usage of such models as individual pre-trained models are downloaded—and fine-tuned—millions of times (see the Hugging Face models repository). Consequently, fine-tuning is the main focus of this post. In particular, I will highlight the most recent advances that have shaped or are likely to change the way we fine-tune language models, which can be seen below.
Adaptive fine-tuning
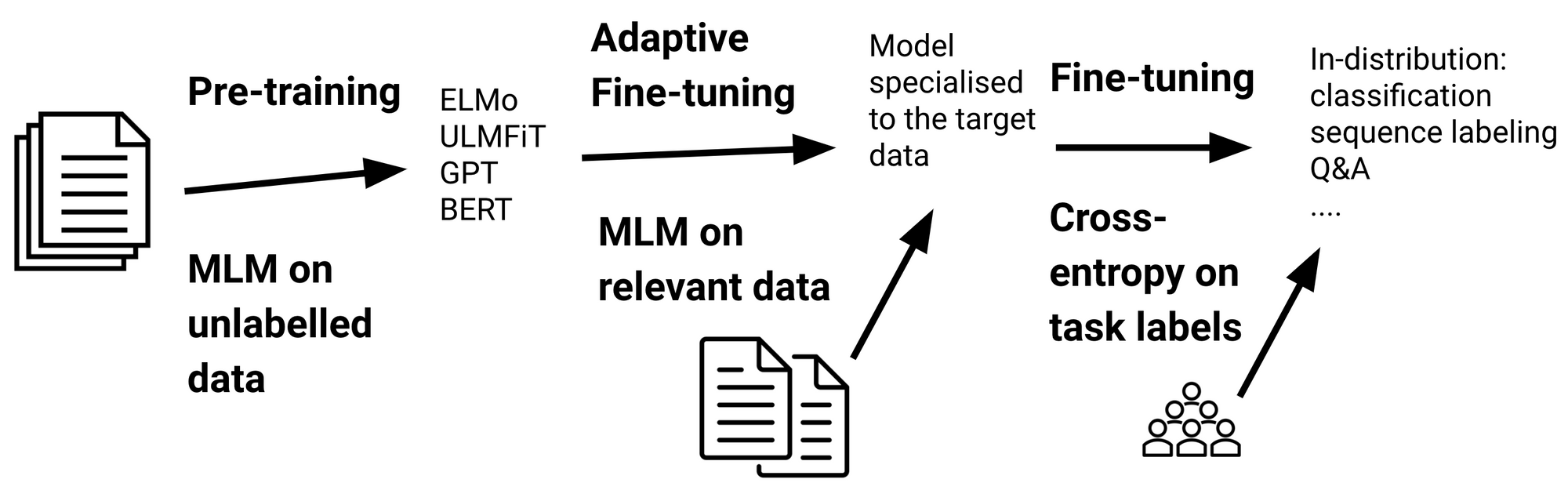
Even though pre-trained language models are more robust in terms of out-of-distribution generalisation than previous models (Hendrycks et al., 2020), they are still poorly equipped to deal with data that is substantially different from the one they have been pre-trained on. Adaptive fine-tuning is a way to bridge such a shift in distribution by fine-tuning the model on data that is closer to the distribution of the target data. Specifically, adaptive fine-tuning involves fine-tuning the model on additional data prior to task-specific fine-tuning, which can be seen below. Importantly, the model is fine-tuned with the pre-training objective, so adaptive fine-tuning only requires unlabelled data.
Formally, given a target domain $\mathcal{D}_T$ consisting of a feature space $\mathcal{X}$ and a marginal probability distribution over the feature space $P(X)$ where $X = \{x_1, \ldots, x_n \} \in \mathcal{X}$ (Pan and Yang, 2009; Ruder, 2019), adaptive fine-tuning allows us to learn about both the feature space $\mathcal{X}$ and the distribution of the target data $P(X)$.
Variants of adaptive fine-tuning—domain, task, and language-adaptive fine-tuning—have been used to adapt a model to data of the target domain, target task, and target language respectively. Dai and Le (2015) first showed the benefits of domain-adaptive fine-tuning. Howard and Ruder (2018) later demonstrated improved sample efficiency by fine-tuning on in-domain data as part of ULMFiT. They also proposed task-adaptive fine-tuning, which fine-tunes the model with the pre-training objective on the task training data. As the pre-training loss provides richer information for modelling the target data compared to the cross-entropy over one-hot task labels, task-adaptive fine-tuning is useful beyond regular fine-tuning. Alternatively, adaptive and regular fine-tuning can be done jointly via multi-task learning (Chronopoulou et al., 2019).
Domain and task-adaptive fine-tuning have recently been applied to the latest generation of pre-trained models (Logeswaran et al., 2019; Han and Eisenstein, 2019; Mehri et al., 2019). Gururangan et al. (2020) show that adapting to data of the target domain and target task are complementary. Recently, Pfeiffer et al. (2020) proposed language-adaptive fine-tuning to adapt a model to new languages.
An adaptively fine-tuned model is specialised to a particular data distribution, which it will be able to model well. However, this comes at the expense of its ability to be a general model of language. Adaptive fine-tuning is thus most useful when high performance on (potentially multiple) tasks of a single domain is important and can be computationally inefficient if a pre-trained model should be adapted to a large number of domains.
Behavioural fine-tuning
While adaptive fine-tuning enables us to specialise our model to $\mathcal{D}_T$, it does not teach us anything directly about the target task. Formally, a target task $\mathcal{T}_T$ consists of a label space $\mathcal{Y}$, a prior distribution $P(Y)$ where $Y = \{y_1, \ldots, y_n \} \in \mathcal{Y}$, and a conditional probability distribution $P(Y | X)$. Alternatively, we can teach a model capabilities useful for doing well on the target task by fine-tuning it on relevant tasks, as can be seen below. We will refer to this setting as behavioural fine-tuning as it focuses on learning useful behaviours and to distinguish it from adaptive fine-tuning.
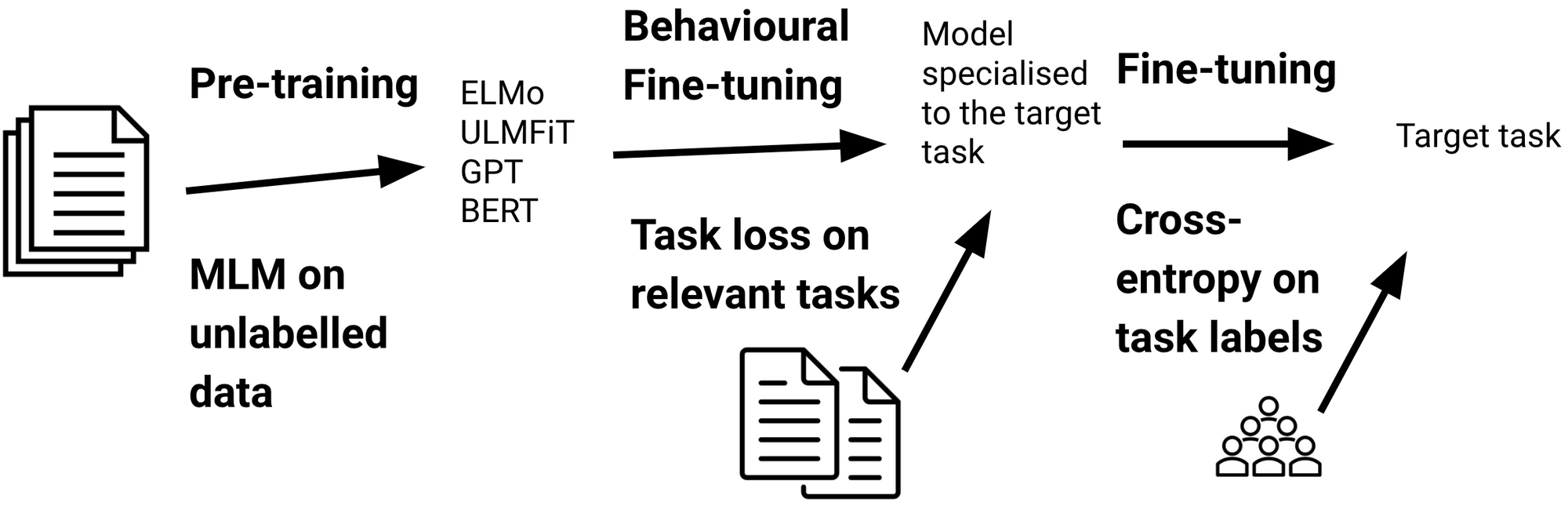
One way to teach a model relevant capabilities is to fine-tune it on relevant labelled data of a related task prior to task-specific fine-tuning (Phang et al., 2018). This so-called intermediate-task training works best with tasks that require high-level inference and reasoning capabilities (Pruksachatkun et al., 2020; Phang et al., 2020). Behavioural fine-tuning with labelled data has been used to teach a model information about named entities (Broscheit, 2019), paraphrasing (Arase and Tsujii, 2019), syntax (Glavaš and Vulić, 2020), answer sentence selection (Garg et al., 2020), and question answering (Khashabi et al., 2020). Aghajanyan et al. (2021) fine-tune on around 50 labelled datasets in a massively multi-task setting and observe that a large, diverse collection of tasks is important for good transfer performance.
As supervised data of such high-level reasoning tasks is generally hard to obtain, we can instead train on objectives that teach the model capabilities that are relevant for the downstream task but which can still be learned in a self-supervised manner. For instance, Dou and Neubig (2021) fine-tune a model for word alignment with an objective that teaches it to identify parallel sentences, among others. Sellam et al. (2020) fine-tune BERT for quality evaluation with a range of sentence similarity signals. In both cases, a diversity of learning signals is important.
Another effective way is to frame the target task as a form of masked language modelling. To this end, Ben-David et al. (2020) fine-tune a model for sentiment domain adaptation with a pivot-based objective. Others propose pre-training objectives, which can be used similarly during fine-tuning: Ram et al. (2021) pre-train a model for QA with a span selection task while Bansal et al. (2020) pre-train a model for few-shot learning by automatically generating cloze-style multi-class classification tasks.
Distinguishing between adaptive and behavioural fine-tuning encourages us to consider the inductive biases we aim to instill in our model and whether they relate to properties of the domain $\mathcal{D}$ or the task $\mathcal{T}$. Disentangling the role of domain and task is important as information about a domain can often be learned using limited unlabelled data (Ramponi and Plank, 2020) while the acquisition of high-level natural language understanding skills with current methods generally requires billions of pre-training data samples (Zhang et al., 2020).
The distinction between task and domain becomes fuzzier, however, when we frame tasks in terms of the pre-training objective. A sufficiently general pre-training task such as MLM may provide useful information for learning $P(Y | X)$ but likely does not contain every signal important for the task. For instance, models pre-trained with MLM struggle with modelling negations, numbers, or named entities (Rogers et al., 2020).
Similarly, the use of data augmentation entangles the roles of $\mathcal{D}$ and $\mathcal{T}$ as it allows us to encode the desired capabilities directly in the data. For instance, by fine-tuning a model on text where gendered words are replaced with those of the opposite gender, a model can be made more robust to gender bias (Zhao et al., 2018; Zhao et al., 2019; Manela et al., 2021).
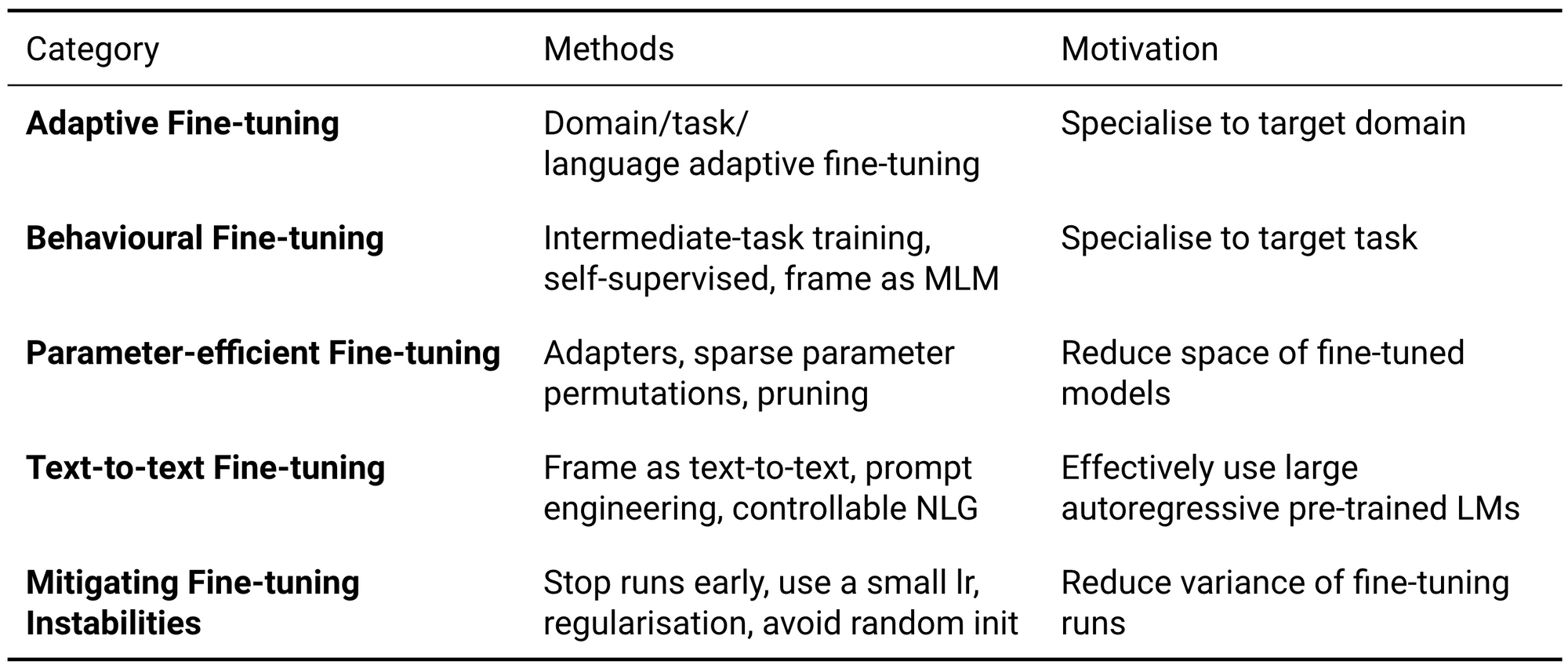
Parameter-efficient fine-tuning
When a model needs to be fine-tuned in many settings such as for a large number of users, it is computationally expensive to store a copy of a fine-tuned model for every scenario. Consequently, recent work has focused on keeping most of the model parameters fixed and fine-tuning a small number of parameters per task. In practice, this enables storing a single copy of a large model and many much smaller files with task-specific modifications.
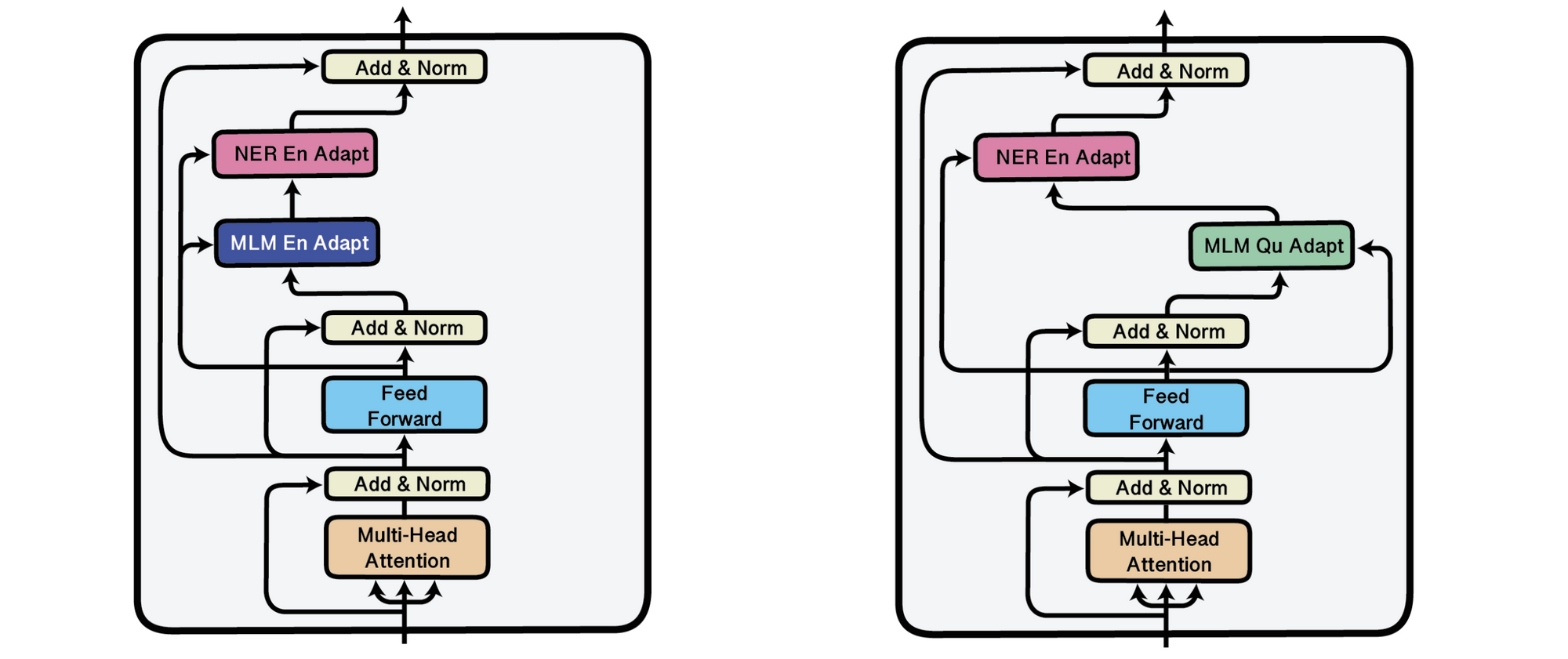
The first approaches in this line of work are based on adapters (Rebuffi et al., 2017), small bottleneck layers that are inserted between the layers of a pre-trained model (Houlsby et al., 2019; Stickland and Murray, 2019) whose parameters are fixed. Adapters render common settings such as storing multiple checkpoints during training as well as more advanced techniques such as checkpoint averaging (Izmailov et al., 2018), snapshot ensembling (Huang et al., 2017) and temporal ensembling (Laine and Aila, 2017) much more space-efficient. Using adapters, a general-purpose model can be efficiently adapted to many settings such as different languages (Bapna and Firat, 2019). Pfeiffer et al. (2020) recently demonstrated that adapters are modular and can be combined via stacking, which enables learning specialised representations in isolation. This is particularly useful when working with the previously discussed methods: an adaptively or behaviourally fine-tuned adapter can be evaluated without any task-specific fine-tuning by stacking a trained task adapter on top of it. This setting can be seen below where a task adapter trained on named entity recognition (NER) is stacked on either an English (left) or Quechua language adapter (right).
While adapters modify the model's activations without changing the underlying parameters, another line of work modifies the pre-trained parameters directly. To illustrate this set of methods, we can view fine-tuning as learning how to perturb the parameters of a pre-trained model. Formally, in order to obtain the parameters of a fine-tuned model $\theta_{\text{fine-tuned}} \in \mathbb{R}^D$ where $D$ is the dimensionality of the model, we learn a task-specific parameter vector $\theta_{\text{task}} \in \mathbb{R}^D$ that captures how to change the pre-trained model parameters $\theta_{\text{pre-trained}} \in \mathbb{R}^D$. The fine-tuned parameters are the result of applying the task-specific permutations to the pre-trained parameters:
\begin{equation}
\theta_{\text{fine-tuned}} = \theta_{\text{pre-trained}} + \theta_{\text{task}}
\end{equation}
Instead of storing a copy of $\theta_{\text{fine-tuned}}$ for every task, we can store a single copy of $\theta_{\text{pre-trained}}$ and a copy of $\theta_{\text{task}}$ for every task. This setting is cheaper if we can parameterise $\theta_{\text{task}}$ more efficiently. To this end, Guo et al. (2020) learn $\theta_{\text{task}}$ as a sparse vector. Aghajanyan et al. (2020) set $\theta_{\text{task}} = \theta_\text{low} \textbf{M}$ where $\theta_\text{low}$ is a low-dimensional vector and $\textbf{M}$ is a random linear projection (in their case, the FastFood transform (Li et al., 2018)).
Alternatively, we can apply modifications only to a subset of the pre-trained parameters. A classic method in computer vision (Donahue et al., 2014) fine-tunes only the last layer of the model. Let $\theta_{\text{pre-trained}}$ be the collection of pre-trained parameters across all $L$ layers of the model, i.e. $\theta_{\text{pre-trained}} = \bigcup\limits_{l=1}^{L} \theta_{\text{pre-trained}}^l$ where $\theta_{\text{pre-trained}}^l$ is the parameter vector associated with the $l$-th layer, with analogous notation for $\theta_{\text{fine-tuned}}$ and $\theta_{\text{task}}$. Fine-tuning only the last layer is then equivalent to:
\begin{equation}
\begin{split}
\theta_{\text{fine-tuned}} = & (\bigcup\limits_{l=1}^{L-1} \theta_{\text{pre-trained}}^l) \\
& \cup (\theta_{\text{pre-trained}}^L + \theta_{\text{task}}^L)
\end{split}
\end{equation}
While this works less well in NLP (Howard & Ruder, 2018), there are other subsets of parameters that are more effective to fine-tune. For instance, Ben-Zaken et al. (2020) achieve competitive performance by only fine-tuning a model's bias parameters.
Another line of work prunes parameters of the pre-trained model during fine-tuning. Such methods use different criteria for pruning weights such as based on zero-th or first-order information about a weight's importance (Sanh et al., 2020). As there is limited support of sparse architectures with current hardware, approaches that are structurally sparse, i.e. where updates are concentrated in a limited set of layers, matrices, or vectors are currently preferable. For instance, the last few layers of pre-trained models have been shown to be of limited use during fine-tuning and can be randomly reinitialised (Tamkin et al., 2020; Zhang et al., 2021) or even completely removed (Chung et al., 2021).
While pruning methods focus on reducing the total number of parameters of task-specific models, most of the other methods focus on reducing the number of trainable parameters—while maintaining a copy of $\theta_{\text{pre-trained}}$. The most recent of the latter approaches generally match the performance of full fine-tuning while training around 0.5% of the model's parameters per task (Pfeiffer et al., 2020; Guo et al., 2020; Ben-Zaken et al., 2020).
There is increasing evidence that large pre-trained language models learn representations that compress NLP tasks well (Li et al., 2018; Gordon et al., 2020; Aghajanyan et al., 2020). This practical evidence coupled with their convenience, availability (Pfeiffer et al., 2020) as well as recent empirical successes make these methods promising both for conducting experiments as well as in practical settings.
Text-to-text fine-tuning
Another development in transfer learning is a move from masked language models such as BERT (Devlin et al., 2019) and RoBERTa (Liu et al., 2019) to autoregressive models of language such as T5 (Raffel et al., 2019) and GPT-3 (Brown et al., 2020). While both sets of methods can be used to assign likelihood scores to text (Salazar et al., 2020), autoregressive LMs are easier to sample from. In contrast, masked LMs are generally restricted to fill-in-the-blank settings, e.g. (Petroni et al., 2019).
The standard way to use masked LMs for fine-tuning is to replace the output layer used for MLM with a randomly initialised task-specific head that is learned on the target task (Devlin et al., 2019). Alternatively, the pre-trained model's output layer can be reused by recasting a task as MLM in a cloze-style format (Talmor et al., 2020; Schick and Schütze, 2021). Analogously, autoregressive LMs generally cast the target task in a text-to-text format (McCann et al., 2018; Raffel et al., 2020; Paolini et al., 2021). In both settings, the models are able to benefit from all their pre-trained knowledge and do not need to learn any new parameters from scratch, which improves their sample efficiency.
In the extreme when no parameters are fine-tuned, framing a target task in terms of the pre-training objective enables zero-shot or few-shot learning using a task-specific prompt and a small number of examples of a task (Brown et al., 2020). However, while such few-shot learning is possible, it is not the most effective way to use such models (Schick and Schütze, 2020; see this post for a brief overview). Learning without updates requires a huge model as the model needs to rely entirely on its existing knowledge. The amount of information available to the model is also restricted by its context window and the prompts shown to the model need to be carefully engineered.
Retrieval augmentation (see this post for an overview) can be used to off-load the storage of external knowledge and symbolic approaches could be used to teach a model task-specific rules akin to (Awasthi et al., 2020). Pre-trained models will also become larger and more powerful and may be behaviourally fine-tuned to be good at the zero-shot setting. However, without fine-tuning a model is ultimately limited in its ability to adapt to a new task.
Consequently, for most practical settings the best path forward arguably is to fine-tune all or a subset of the model's parameters using the methods described in the previous sections. In addition, we will increasingly see an emphasis of pre-trained models' generative capabilities. While current methods generally focus on modifying a model's natural language input such as via automatic prompt design (Schick and Schütze, 2020; Gao et al., 2020; Shin et al., 2020), the most effective way to modulate the output of such models will likely act directly on their hidden representations (Dathathri et al., 2020; see Lillian Weng's post for an overview of methods for controllable generation).
Mitigating fine-tuning instabilities
A practical problem with fine-tuning pre-trained models is that performance can vary drastically between different runs, particularly on small datasets (Phang et al., 2018). Dodge et al., 2020 find that both the weight initialisation of the output layer and the order of the training data contribute to variation in performance. As instabilities are generally apparent early in training, they recommend stopping the least promising runs early after 20-30% of training. Mosbach et al. (2021) additionally recommend using small learning rates and to increase the number of epochs when fine-tuning BERT.
A number of recent methods seek to mitigate instabilities during fine-tuning by relying on adversarial or trust region-based approaches (Zhu et al., 2019; Jiang et al., 2020; Aghajanyan et al., 2021). Such methods generally augment the fine-tuning loss with a regularisation term that bounds the divergence between update steps.
In light of the previous section, we can make another recommendation for minimising instabilities during fine-tuning: Avoid using a randomly initialised output layer on the target task for small datasets by framing the target task as a form of LM or use behavioural fine-tuning to fine-tune the output layer prior to task-specific fine-tuning. While text-to-text models are thus more robust to fine-tuning on small datasets, they suffer from instabilities in the few-shot setting and are sensitive to the prompt and few-shot examples (Zhao et al., 2021).
Overall, as models are increasingly applied to challenging tasks with fewer training examples, it is crucial to develop methods that are robust to possible variations and that can be reliably fine-tuned.
Citation
For attribution in academic contexts, please cite this work as:
@misc{ruder2021lmfine-tuning,
author = {Ruder, Sebastian},
title = {{Recent Advances in Language Model Fine-tuning}},
year = {2021},
howpublished = {\url{http://ruder.io/recent-advances-lm-fine-tuning}},
}