ACL 2022 Highlights
This post discusses my highlights of ACL 2022, including language diversity and multimodality, prompting, the next big ideas and keynotes, my favorite papers, and the hybrid conference experience.

ACL 2022 took place in Dublin from 22nd–27th May 2022. This was my first in-person conference since ACL 2019. This is also my first conference highlights post since NAACL 2019. With 1032 accepted papers (604 long, 97 short, 331 in Findings), this post can only offer a glimpse of the diverse research presented at the conference—biased towards my research interests.
Here are the themes that were most noticeable for me across the conference program:
- Language Diversity and Multimodality
- Prompting
- Next Big Ideas
- Favorite Papers
- The Dark Matter of Language and Intelligence
- Hybrid Conference Experience
Here are highlights of other conference attendees:
- Multimodality at ACL 2022 by Mubashara Akhtar
- Notes from ACL 2022 by Jindřich Libovický
- My First In-Person NLP Conference by Yong Zheng-Xin
If you attended ACL, I encourage you to reflect on and write up your impressions of the conference (send me a message and I will link them here).
Language diversity and multimodality

ACL 2022 had a theme track on the topic of “Language Diversity: from Low-Resource to Endangered Languages”. Beyond the excellent papers in the track, language diversity also permeated other parts of the conference. Steven Bird hosted a panel on language diversity featuring researchers speaking and studying under-represented languages (slides). The panelists shared their experiences and discussed interlingual power dynamics, among other topics. They also made practical suggestions to encourage more work on such languages: creating data resources; establishing a conference track for work on low-resource and endangered languages; and encouraging researchers to apply their systems to low-resource language data. They also mentioned a positive development, that researchers are becoming more aware of the value of high-quality datasets. Overall, the panelists emphasised that working with such languages requires respect—towards the speakers, the culture, and the languages themselves.
Endangered languages were also the focus of the Compute-EL workshop. In the awards ceremony, the best linguistic insight paper proposed KinyaBERT, a pre-trained model for Kinyarwanda that leverages a morphological analyzer. The best theme paper developed speech synthesis models for three Canadian indigenous languages. The latter is an example of how multimodal approaches can benefit language diversity.
Other multimodal papers leveraged phone representations to improve NER performance in Swahili and Kinyarwanda (Leong & Whitenack). For low-resource text-to-speech, Lux & Vu employ articulatory features such as position (e.g., frontness of the tongue) and category (e.g., voicedness), which generalize better to unseen phonemes. Some work also explored new multimodal applications such as detecting fingerspelling in American sign language (Shi et al.) or translating songs for tonal languages (Guo et al.).
The Multilingual Multimodal workshop hosted a shared task on multilingual visually grounded reasoning on the MaRVL dataset. Seeing the emergence of such multilingual multimodal approaches is particularly encouraging as it is an improvement over the previous year’s ACL where multimodal approaches mainly dealt with English (based on an analysis of “multi-dimensional” NLP research we did for an ACL 2022 Findings paper).

In an invited talk (slides), I emphasized multimodality in addition to three other challenges towards scaling NLP systems to the next 1,000 languages: computational efficiency, real-world evaluation, and language varieties. Multimodality is also at the heart of the ACL 2022 D&I Special Initiative “60-60 Globalization via localisation” announced by Mona Diab. The initiative focuses on making Computational Linguistics (CL) research accessible in 60 languages and across all modalities, including text/speech/sign language translation, closed captioning, and dubbing. Another useful aspect of the initiative is the curation of the most common CL terms and their translation into 60 languages. The unavailability of accurate scientific expressions poses a barrier to entry in many languages (see this related Masakhane project to decolonise science). The CL community is well positioned to advance the accessibility of scientific content and I am excited to see the progress of this grassroots initiative.
Under-represented languages typically have little text data available. Two tutorials focused on applying models to such low-resource settings. The tutorial on learning with limited text data discussed data augmentation, semi-supervised learning, and applications to multilinguality while the tutorial on zero-shot and few-shot NLP with pre-trained language models covered prompting, in-context learning, gradient-based LM task adaptation, among others.
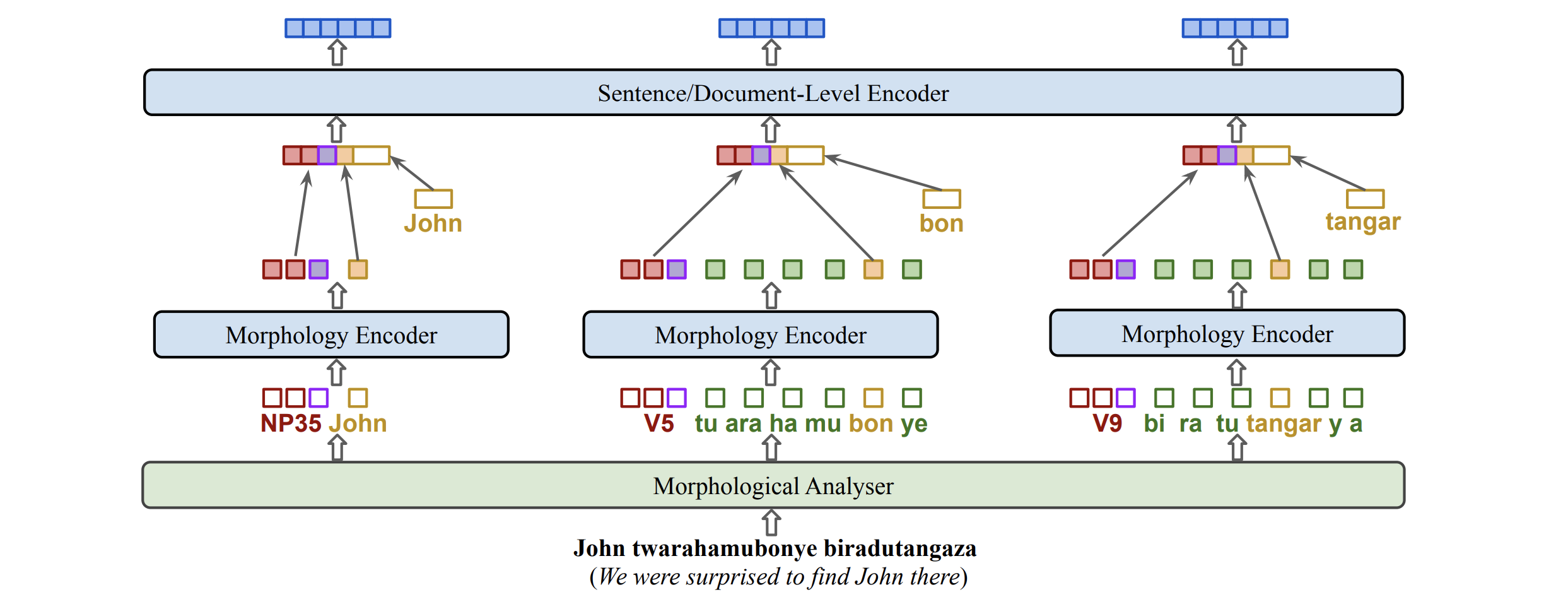
How to optimally represent tokens across different languages is an open problem. The conference program featured several new approaches to overcome this challenge. KinyaBERT (Nzeyimana & Rubungo) leveraged a morphological word segmentation approach. Similarly, Hofmann et al. propose a method that aims to preserve the morphological structure of words during tokenization. The algorithm tokenizes a word by determining its longest substring in the vocabulary and then recursing on the remaining string until a certain number of recursive calls.
Rather than choosing subwords that occur frequently in the multilingual pre-training data (which biases the model towards high-resource languages), Patil et al. propose a method that prefers subwords that are shared across multiple languages. Both CANINE (Clark et al.) and ByT5 (Xue et al.) do away with tokenization completely and operate directly on bytes.
Languages naturally do not only differ in their linguistic form but also in their culture, which includes the shared knowledge, values, and goals of speakers, among other things. Hershcovich et al. provide a great overview of what is important for cross-cultural NLP. A particular form of cultural-specific knowledge relates to time and temporal expressions such as morning, which may refer to different hours in different languages (Schwartz).
Here are some of my favorite papers, beyond the ones already mentioned above:
- Towards Afrocentric NLP for African Languages: Where We Are and Where We Can Go (Adebara & Abdul-Mageed). This paper discusses challenges of NLP for African languages and makes practical recommendations on how to address each. It highlights both linguistic phenomena (handling tone, vowel harmony, and serial verb constructions) and other challenges on the continent (low literacy, non-standardized orthographies, lack of language use in official contexts).
- Quality at a Glance: An Audit of Web-Crawled Multilingual Datasets (Kreutzer et al.). I wrote about this paper when it first came out. It conducts a careful audit of large-scale multilingual datasets covering 70 languages and identifies many data quality issues that have previously gone unnoticed. It highlights that many low-resource language datasets have low quality and that some datasets are even completely mislabeled.
- Multi Task Learning For Zero Shot Performance Prediction of Multilingual Models (Ahuja et al.). We would like to know how well a model does if we apply it to data in a new language, which can inform how many examples we need to annotate. This paper makes performance prediction more robust by jointly learning to predict performance across multiple tasks. This also enables an analysis of features that affect zero-shot transfer across all tasks.
I had the chance to collaborate on a couple of papers in this space:
- One Country, 700+ Languages: NLP Challenges for Underrepresented Languages and Dialects in Indonesia (Aji et al.). We provide an overview of NLP challenges for Indonesia’s 700+ languages (Indonesia is the world’s second most linguistically diverse country). Among these are dialectal and style differences, code-mixing, and orthographic variation. We make practical recommendations such as documenting dialect, style, and register information in datasets.
- Expanding Pretrained Models to Thousands More Languages via Lexicon-based Adaptation (Wang et al.). We analyze different strategies using bilingual lexicons (which are available in around 5000 languages) to synthesize data for training models for extremely low-resource languages and how such data can be combined with existing data, if available. In particular, we find that this works much better than translation (as the performance of an NMT model for such languages is often poor).
- Square One Bias in NLP: Towards a Multi-Dimensional Exploration of the Research Manifold (Ruder et al.). We identify the current prototypical NLP experiment (the “square one”) and assess the dimensions along which NLP papers make contributions that go beyond this prototype by annotating the 461 ACL 2021 oral papers. We find that almost 70% of papers evaluate only in English and almost 40% of papers only evaluate performance. Only 6.3% of papers evaluate the bias or fairness of a method and only 6.1% of papers are “multi-dimensional”, i.e., they make a contribution along two or more of our investigated dimensions.
Prompting
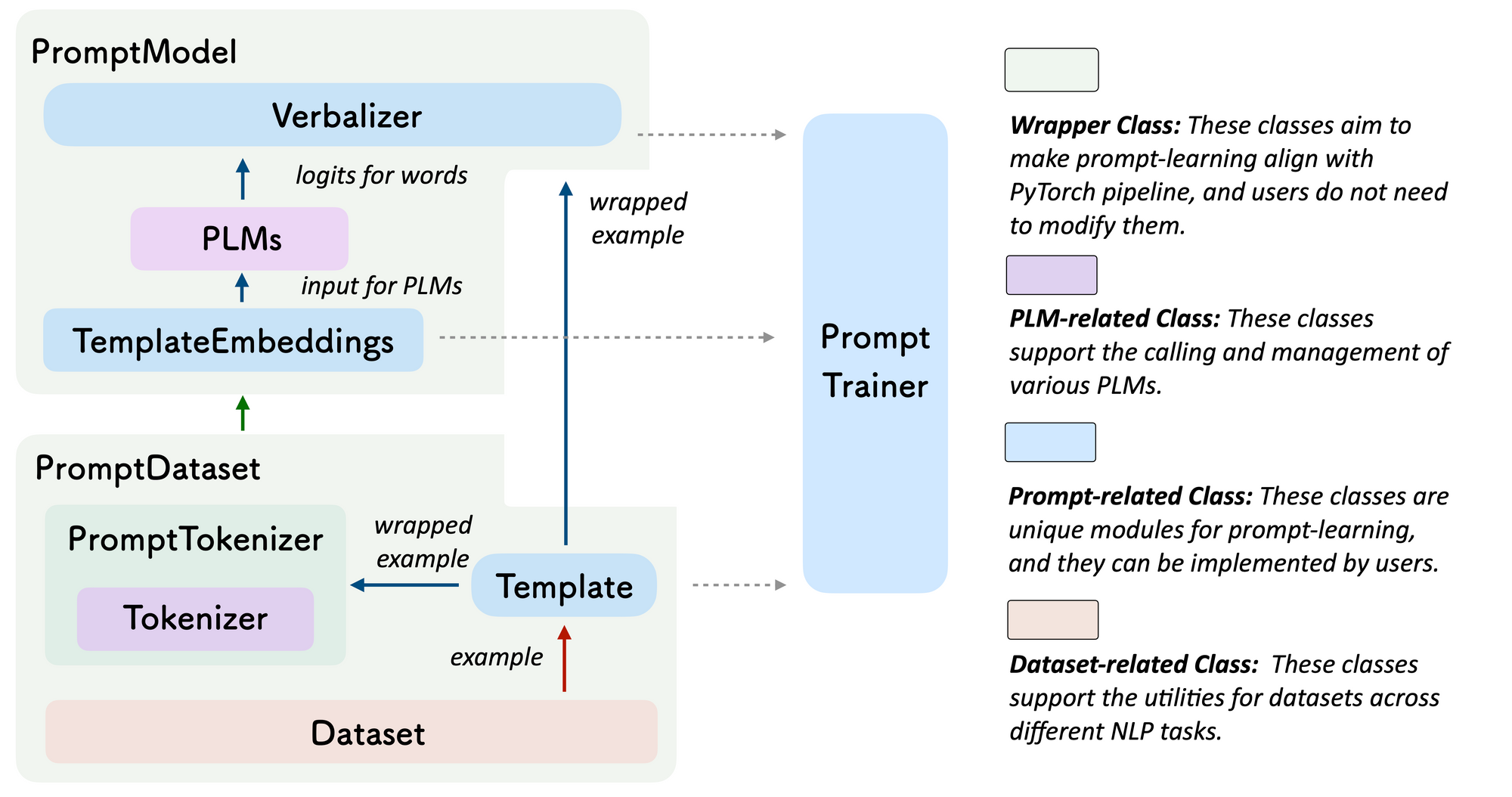
Prompting was another area that received a lot of attention. The best demo paper was OpenPrompt, an open-source framework for learning with prompts that allows to easily define templates and verbalizers and to combine them with pre-trained models.
A common thread of research was to incorporate external knowledge into learning. Hu et al. propose to expand the verbalizer with words from a knowledge base. Liu et al. use an LM to generate relevant knowledge statements in a few-shot setting. A second LM then uses these to answer commonsense questions. We can also incorporate additional knowledge by modifying the training data, e.g., by inserting metadata strings (e.g., entity types and descriptions) after entities (Arora et al.).
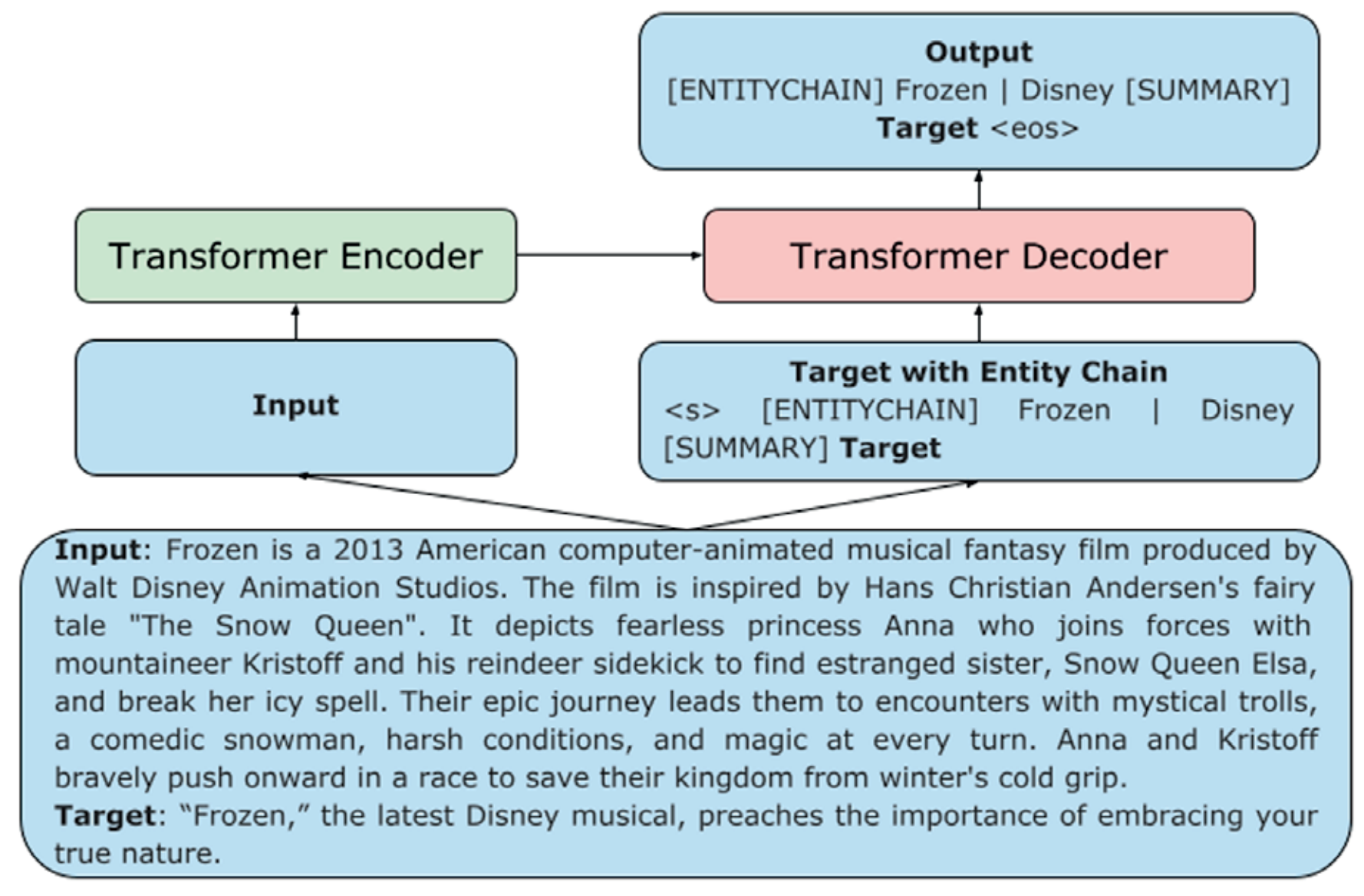
Other papers proposed prompts particularly suited for specific applications. Reif et al. propose to provide a model with examples of multiple styles for style transfer while Tabasi et al. compare independently obtained embeddings of [MASK] tokens using a similarity function for semantic similarity tasks. Narayan et al. steer a summarization model by training it to predict a chain of entities before the target summary (e.g., “[ENTITYCHAIN] Frozen | Disney“). Schick et al. prompt a model with questions containing an attribute (e.g., “Does the above text contain a threat?”) to diagnose if a model’s generated text is offensive. Ben-David et al. generate the domain name and domain-related features as a prompt for domain adaptation.
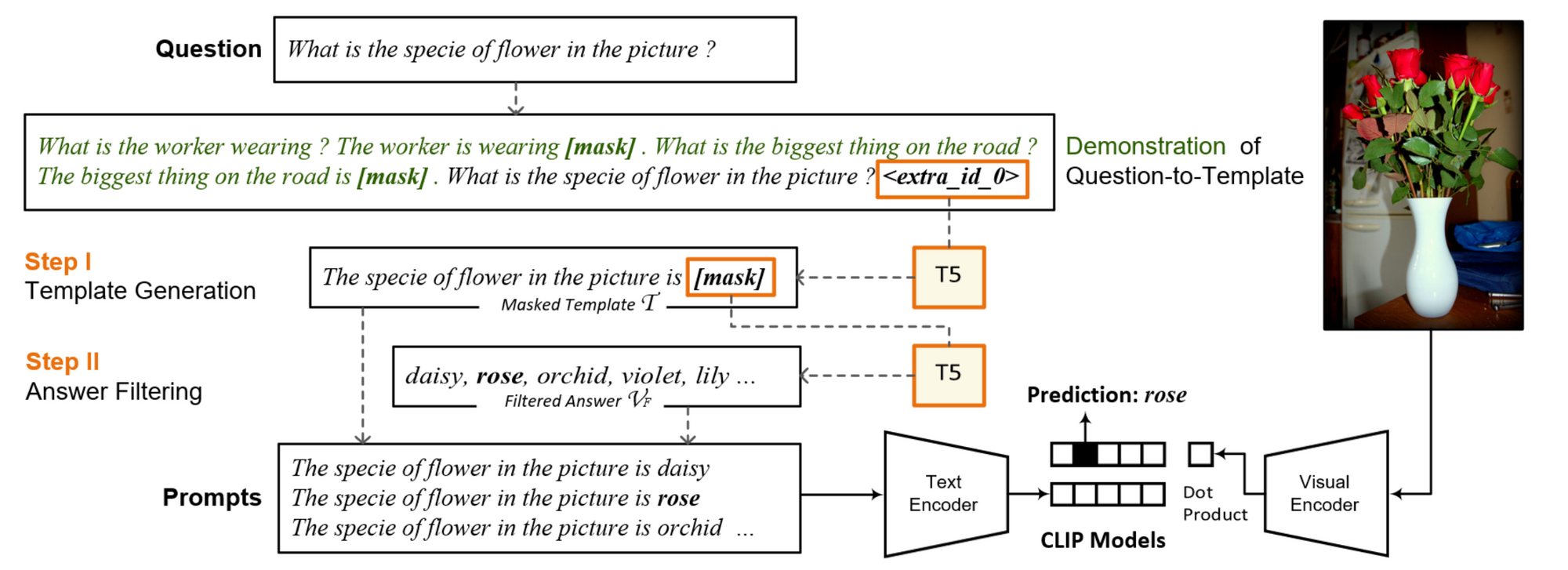
Prompting in a multimodal setting also received some attention. Jin et al. analyze the effect of diverse prompts in a few-shot setting. Song et al. investigate prompting for vision-and-language few-shot learning with CLIP. They generate prompts based on VQA questions using T5 and filter out impossible answers with the LM. Prompts are then paired with the target image and used to calculate image-text alignment scores with CLIP.
Finally, there were a few papers seeking to obtain a better understanding of prompting. Mishra et al. explore different ways of reformulating instructions such as decomposing a complex task into several simpler tasks or itemizing instructions. Lu et al. analyze the sensitivity of models to the order of few-shot examples. As the best permutation cannot be identified without additional development data, they generate a synthetic dev set using the LM itself and determine the best example order via entropy.
The following papers on which I collaborated relate to few-shot learning:
- FewNLU: Benchmarking State-of-the-Art Methods for Few-Shot Natural Language Understanding (Zheng et al.). We introduce an evaluation framework to make few-shot evaluation more reliable, including a new data split strategy. We re-evaluate state-of-the-art few-shot learning methods under this framework. We observe that the absolute and relative performance of some methods was overestimated and that improvements of some methods decrease with a larger pre-trained model, among other things.
- Memorisation versus Generalisation in Pre-trained Language Models (Tänzer et al.). We study the memorisation and generalisation behaviour of state-of-the-art pre-trained models. We observe that current models are resistant even to high degrees of label noise and that training can be separated into three distinct phases. We also observe that pre-trained models forget drastically less than non-pre-trained models. Finally, we propose an extension to make models more resilient to low-frequency patterns.
Next Big Ideas

One of my favorite sessions of the conference was the Next Big Ideas session, a new format pioneered by the conference organizers. The session featured senior researchers providing opinionated takes on important research directions.
Two themes stuck out for me during this session: structure and modularity. Researchers stressed the need for extracting and representing structured information such as relations, events, and narratives. They also emphasised the importance of putting thought into how these are represented—through human definitions and the design of appropriate schemas. Many topics required dealing with multiple interdependent tasks, whether for story understanding, reasoning, or schema learning. This will require multiple models or components interfacing with each other. If you want to learn more about modular approaches, we will be teaching a tutorial on modular and parameter-efficient fine-tuning for NLP models at EMNLP 2022. As a whole, these research proposals sketched a compelling vision of NLP models extracting, representing, and reasoning with complex knowledge in a structured, multi-agent manner.
Heng Ji started off the session with a passionate plea for more structure in NLP models. She emphasized moving towards corpus-level IE (from current sentence-level and document-level IE) and noted the extraction of relations and structures from other types of text such as scientific articles and relation and event extraction for low-resource languages. In the multimodal setting, images and videos can be converted into visual tokens, organized into structures, and described with structured templates. Extracted structures can be further generalized into patterns and event schemas. We can represent structure by embedding it in pre-trained models, encoding it via a graph neural network or via global constraints.
Mirella Lapata discussed stories and why we should pay attention to them. Stories have shape, structure, and recurrent themes and are at the heart of NLU. They are also relevant for many practical applications such as question answering and summarization. To process stories, we need to do semi-supervised learning and train models that can process very long inputs and deal with multiple, interdependent tasks (such as modeling characters, events, temporality, etc). This requires modular models as well as including humans in the loop.
Dan Roth stressed the importance of reasoning for making decisions based on NLU. In light of the diverse set of reasoning processes, this requires multiple interdependent models and a planning process that determines what modules are relevant. We also need to be able to reason about time and other quantities. To this end, we need to be able to extract, contextualize, and scope relevant information and provide explanations for the reasoning process. To supervise models, we can use incidental supervision such as comparable texts (Roth, 2017).
Thamar Solorio discussed how to serve the half of the world’s population that is multilingual and frequently employs code-switching. In contrast, current language technology mainly caters to monolingual speakers. Informal settings where code-switching is commonly used are becoming increasingly relevant such as in the context of chatbots, voice assistants, and social media. She noted challenges such as limited resources, “noise” in conversational data, and issues with transliterated data. We also need to identify relevant uses as code-switching is not relevant in all NLP scenarios. Ultimately, “we need language models that are representative of the actual ways in which people use language” (Dingemanse & Liesenfeld). For more on code-switching, check out this excellent ACL 2021 survey.
Marco Baroni focused on modularity. He laid out a research vision where frozen pre-trained networks autonomously interact by interfacing with each other to solve new tasks together. He suggested that models should communicate through a learned interface protocol that is easily generalizable.
Eduard Hovy urged us to rediscover the need for representation and knowledge. When knowledge is rare or never appears in the training data such as implicit knowledge, it is not learned by our models. To fill these gaps, we need to define the set of human goals that we care about and schemas that capture what was not said or what is going to be said. This requires evolving schema learning to a set of inter-related schemas such as schemas of patient, epidemiologist, and pathogen in the context of a pandemic. Similarly, to capture roles of people in groups, we need human definitions and guidance. Overall, he encouraged the community to put thought into building topologies that can be learned by models.
Finally, Hang Li emphasized the need for symbolic reasoning. He suggested a neuro-symbolic architecture for NLU that combines analogical reasoning via a pre-trained model and logical reasoning via symbolic components.
In addition to the Next Big Ideas session, the conference also featured spotlight talks by early-career researchers. I had the honor to speak next to amazing young researchers such as Eunsol Choi, Diyi Yang, Ryan Cotterell, and Swabha Swayamdipta. I hope that future conferences will continue with these formats and experiment with others as they bring a fresh perspective and enable a broader view of research.
Favorite Papers

Finally, here are some of my favorite papers on less mainstream topics. Quite a few of these are in TACL, highlighting the usefulness of TACL as a venue for publishing nuanced research. Many of these also emphasize the human side of NLP:
- It’s not Rocket Science: Interpreting Figurative Language in Narratives (Chakrabarty et al.). This paper focuses on understanding figurative language (idioms and similes). They evaluate whether models can interpret such figurative expressions by framing the task in an LM setting: they generate plausible and implausible continuations using crowd workers, which rely on the correct interpretation of the expression. They find that state-of-the-art models perform poorly on this task but performance can be improved by providing additional context or knowledge-based inferences (e.g., “The narrator sweats from nerves”, “Run is used for exercise”) as input.
- Word Acquisition in Neural Language Models (Chang & Bergen). This paper investigates when individual words are acquired during training in neural models, compared to word acquisition in humans. They find that LMs rely far more on word frequency than children (who rely more on interaction and sensorimotor experience). Like children, LMs also exhibit slower learning of words in longer utterances. Early in training, models predict based on unigram token frequencies, later on bigram probabilities, and eventually converge to more nuanced predictions.
- The Moral Debater: A Study on the Computational Generation of Morally Framed Arguments (Alshomary et al.). This paper studies the automatic generation of morally framed arguments. The system takes a controversial topic (e.g., globalization), a stance (e.g., pro), and a set of morals (e.g., loyalty, authority, and purity) as input, retrieves and filters relevant texts based on the morals, and phrases an argument. They employ a Reddit dataset annotated with aspects (e.g., respect, obedience), which they map to morals. They evaluate the effectiveness of morally framed arguments in a user study with liberals and conservatives.
- Human Language Modeling (Soni et al.). This paper extends the language modeling task with a dependence on a human state in which the text was generated. To this end, they process all utterances of a user sequentially and condition a Transformer’s self-attention on a recurrently computed user state. The model is pre-trained on Facebook posts and tweets with user information where it achieves a dramatic reduction in perplexity and improvements on downstream stance and sentiment tasks.
- Inducing Positive Perspectives with Text Reframing (Ziems et al.). This paper introduces the task of positive reframing, which neutralizes a negative point of view and generates a more positive perspective without contradicting the meaning (e.g., “I absolutely hate making decisions” → “It’ll become easier once I start to get used to it”). They create a new dataset for this task, annotated with different reframing strategies. Overall, the task is an interesting and challenging application of style transfer—and who is not in need of positive reframing sometimes?
The Dark Matter of Language and Intelligence
Yejin Choi gave an inspiring keynote. Among other things, it is the first talk I have seen that uses DALL-E 2 for illustrating slides. She highlighted three important research areas in NLP by drawing analogies to physics: ambiguity, reasoning, and implicit information.
In modern physics, a greater understanding often leads to increased ambiguity (see, for instance, Schrödinger’s cat or the wave–particle duality). Yejin similarly encouraged the ACL community to embrace ambiguity. In the past, there was pressure not to work on tasks that did not achieve high inter-annotator agreement; similarly, in traditional sentiment analysis, the neutral class is often discarded. Understanding cannot just be crammed into simple categories. Annotator opinions bias language models (Sap et al., 2021) and ambiguous examples improve generalization (Swayamdipta et al., 2020).
Similar in spirit to the notion of spacetime, Yejin argued that language, knowledge, and reasoning are also not separate areas but exist on a continuum. Reasoning methods such as maieutic prompting (Jung et al., 2022) allow us to investigate the continuum of a model’s knowledge by recursively generating explanations.
Finally, analogous to the central role of dark matter in modern physics, future research in NLP should focus on the “dark matter” of language, the unspoken rules of how the world works, which influence the way people use language. We should aspire to try to teach our models such as tacit rules, values, and objectives (Jiang et al., 2021).
Yejin concluded her talk with a candid take of factors that led to her success: being humble, learning from others, taking risks; but also being lucky and working in an inclusive environment.
Hybrid conference experience


I personally really enjoyed the in-person conference experience. There was a strict mask wearing requirement, which everyone adhered to and which did not otherwise impede the flow of the conference. The only issues were some technical problems that occurred during plenary and keynote talks.
On the other hand, I found it difficult to reconcile the in-person with the virtual conference experience. Virtual poster sessions overlapped with breakfast or dinner, which made attending them difficult. From what I have heard, many virtual poster sessions were almost empty. It seems we need to rethink how to conduct virtual poster sessions in a hybrid setting. As an alternative, it may be more effective to create asynchronous per-poster chat rooms in rocket.chat or a similar platform, with the ability to set up impromptu video calls for deeper conversations.
The experience was better for oral presentations and workshops, which had a reasonable number of virtual participants. I particularly appreciate being able to rewatch the recordings of keynotes and other invited talks.
Overall, we still have some way to go to create a great experience for virtual participants. However, it was a blast being able to interact with people in-person again. Thanks to all the organizers, volunteers, and to the community for putting together a great conference!