ACL 2021 Highlights
This post discusses my highlights of ACL 2021, including challenges in benchmarking, machine translation, model understanding, and multilingual NLP.

ACL 2021 took place virtually from 1–6 August 2021. Here are my highlights from the conference:
- NLP benchmarking is broken
- NLP is all about pre-trained Transformers
- Machine translation
- Understanding models
- Cross-lingual transfer and multilingual NLP
- Challenges in natural language generation
- Virtual conference notes
NLP benchmarking is broken
Many talks and papers made reference to the current state of NLP benchmarking, which has seen existing benchmarks largely outpaced by rapidly improving pre-trained models.
My favourite resources on this topic from the conference are:
- Chris Pott's keynote on Reliable characterizations of NLP systems as a social responsibility.
- Rada Mihalcea's presidential address where she emphasises evaluation beyond accuracy.
- Samuel Bowman's and George Dahl's position paper asking "What Will it Take to Fix Benchmarking in Natural Language Understanding?".
I've also written a longer blog post that provides a broader overview of different perspectives, challenges, and potential solutions to improve benchmarking in NLP.
NLP is all about pre-trained Transformers
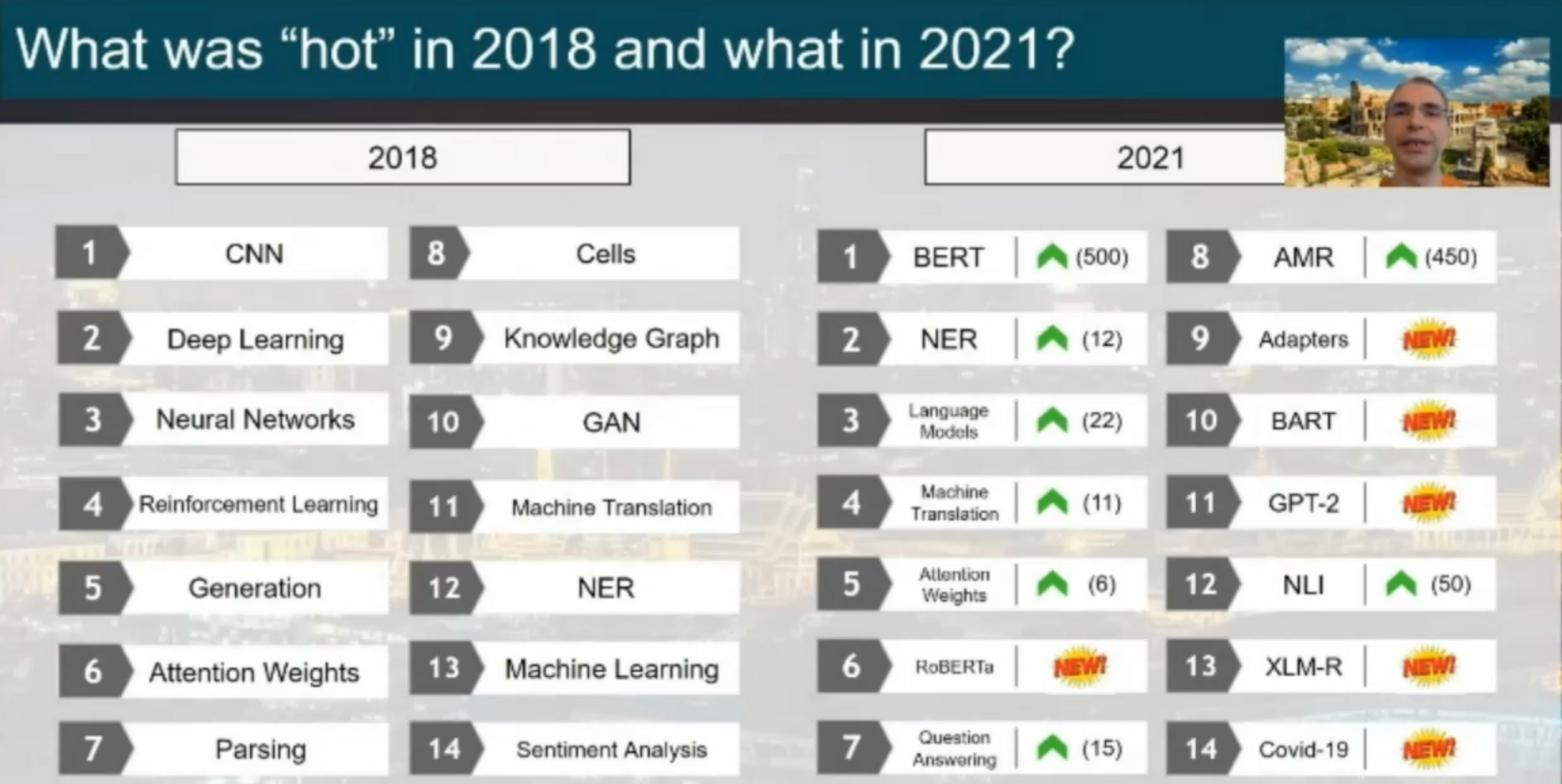
This should come as no surprise but it's still interesting to see that among the 14 "hot" topics of 2021 (see below) were five pre-trained models (BERT, RoBERTa, BART, GPT-2, XLM-R) and one general "Language models" topic. These models are essentially all variants of the same Transformer architecture.
This serves as a useful reminder that the community is overfitting to a particular setting and that it may be worthwhile to look beyond the standard Transformer model (see my recent newsletter for some inspiration).
There were a few papers that sought to improve the general Transformer architecture for processing long and short documents respectively:
- ERNIE-Doc: A Retrospective Long-Document Modeling Transformer. This architecture is based on a Transformer-XL type model that was "skims" the document, caches the contextual information, and then reuses the cached contextual information during additional processing.
- Shortformer: Better Language Modeling using Shorter Inputs. This paper proposes to perform curriculum learning on short inputs and to add absolute position embeddings to queries and keys rather than word embeddings in order to improve language modeling performance on standard benchmarks such as WikiText-103.
Machine translation
Machine translation, similar to past years, was one of the most popular tracks of the conference, just behind the general ML track in terms of the number of submissions as can be seen below.
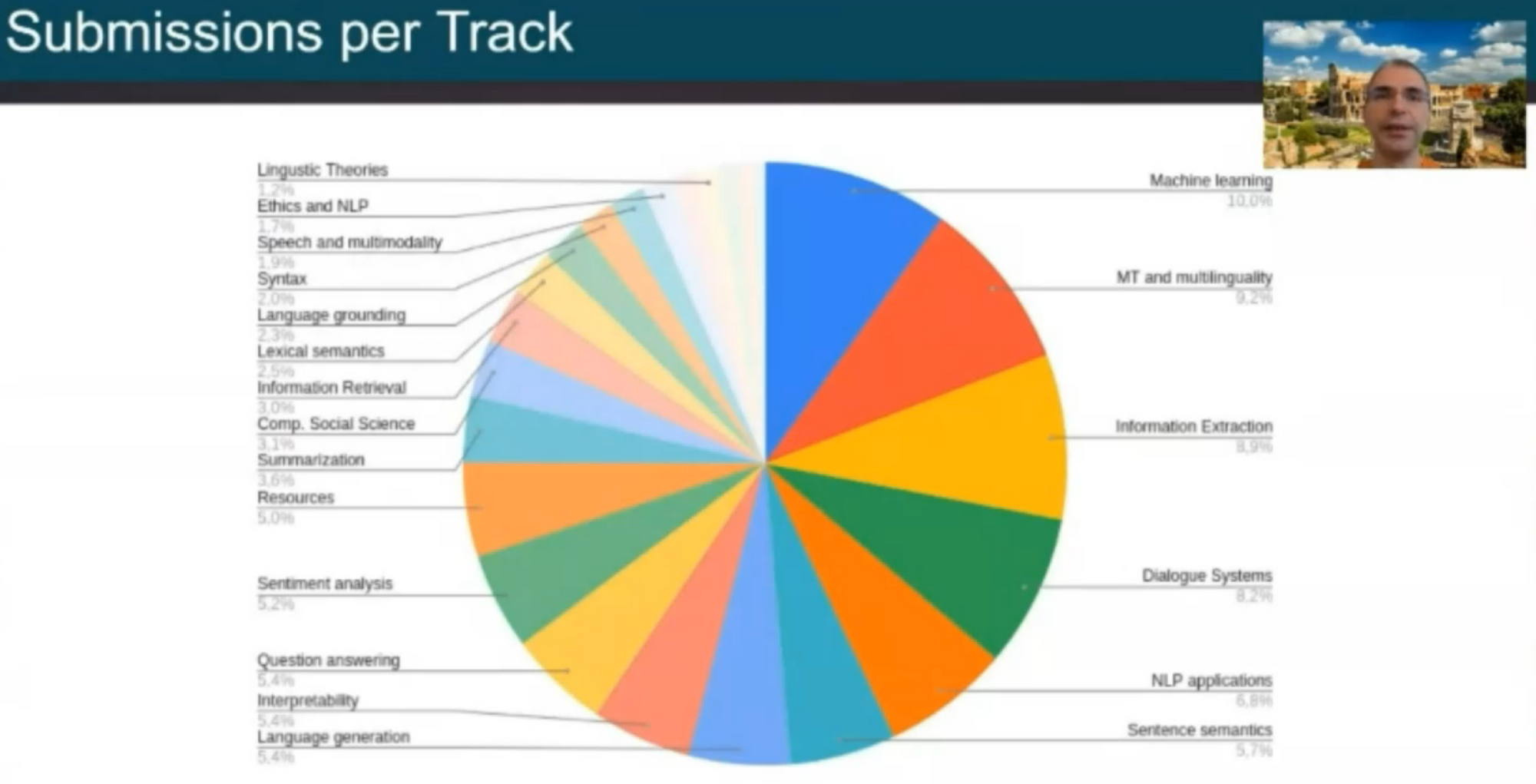
3 of the top 6 papers are on MT:
- Scientific Credibility of Machine Translation Research: A Meta-Evaluation of 769 Papers. Marie et al. investigate how credible the evaluation in a large number of papers actually is. They find that almost all papers used BLEU; 74.3% exclusively used BLEU. 108 new MT metrics have been proposed in the last decade but none are used consistently. Unsurprisingly, most papers do not perform statistical significance testing. An increasing number of papers copy scores from previous work. Sometimes scores are reported using different variants of BLEU script and are therefore not comparable. They provide the following guidelines for MT evaluation: Don’t use BLEU exclusively, do statistical significance testing, do not copy numbers from prior work, compare systems using the same pre-processed data. More recently, in 2022, Benjamin Marie has written additional posts where he analysed shortcomings in the MT evaluation of prominent papers.
- Neural Machine Translation with Monolingual Translation Memory. Cai et al. combine neural networks with a non-parametric memory.
- Vocabulary Learning via Optimal Transport for Neural Machine Translation. Xu et al. frame vocabulary learning as optimal transport. They propose to use marginal utility as a measure for a good vocabulary.
Within machine translation, there were a couple of papers that I particularly enjoyed:
- Understanding the Properties of Minimum Bayes Risk Decoding in Neural Machine Translation. This paper questions the status quo of using beam search. Müller & Sennrich find that while an alternative, Minimum Bayes Risk (MBR) decoding, is still biased towards length and token frequency, it also increases robustness against noise and domain shift.
- Learning Language Specific Sub-network for Multilingual Machine Translation. Li et al. learn language-specific subnetworks, which is a promising approach to prevent parameter interference in multilingual models. This work led to other related work that we covered in an EMNLP 2022 tutorial.
- Gender bias amplification during Speed-Quality optimization in Neural Machine Translation. This paper stood out to me because it does not just study bias or efficiency in isolation but their interaction. In an ACL Findings 2022 study, it was the only ACL 2022 paper that we found to have such a multi-dimensional research scope.
There were also some papers that focused on machine translation for low-resource language varieties without using parallel data for those languages:
- Adapting High-resource NMT Models to Translate Low-resource Related Languages without Parallel Data. Ko et al. propose a combination of different methods to leverage available monolingual data for adapting to low-resource languages.
- Machine Translation into Low-resource Language Varieties. Kumar et al. propose an approach for adaptation to low-resource varietities of standard languages. They fine-tune models on synthesized (pseudo-parallel) source-target texts and replace the decoder input and output with pretrained word vectors, which makes adaptation easier.
Understanding models
Gaining a better understanding of the behaviour of current models was another theme of the conference, with three out of the six outstanding papers falling in this area:
- Intrinsic Dimensionality Explains the Effectiveness of Language Model Fine-Tuning. This paper analyses fine-tuning through the lens of intrinsic dimension and shows that common pre-trained models have a very low intrinsic dimension. They also show that pre-training implicitly minimises the intrinsic dimension and that larger models tend to have lower intrinsic dimension. Intrinsic dimension is a very relevant concept for the evaluation and design of efficient pre-trained models, which we covered in an EMNP 2022 tutorial.
- Mind Your Outliers! Investigating the Negative Impact of Outliers on Active Learning for Visual Question Answering. This paper investigates the failure of active learning on VQA. The authors observe that the acquired examples are collective outliers, i.e., groups of examples that are hard or impossible for current models. Removing such hard outliers makes things easier for active learning.
- UnNatural Language Inference. This paper changes the word order of NLI sentences to investigate if models "know syntax". They find that state-of-the-art NLI models are largely invariant to word order changes. They observe that some distributional information (POS neighbourhood) may be useful for performing well in the permuted setup. Unsurprisingly, human annotators struggle on the permuted sentences.
I also enjoyed the following two papers that developed new methods and frameworks for understanding model behaviour:
- Amnesic Probing: Behavioral Explanation with Amnesic Counterfactuals. This paper proposes amnesic probing, which uses iterative nullspace projection to remove a property from a pre-trained representation, in order to assess how important that property is for a downstream task.
- ExplainaBoard: An Explainable Leaderboard for NLP. The best demo paper introduces ExplainaBoard, a leaderboard framework with additional capabilities for model analysis. The authors provide ExplainaBoard leaderboards for various tasks and datasets.
Cross-lingual transfer and multilingual NLP
Beyond machine translation, I enjoyed the following papers on cross-lingual transfer and multilingual NLP:
- COSY: COunterfactual SYntax for Cross-Lingual Understanding. This paper is a nice example of incorporating linguistic information in the form of dependency relations and part-of-speech tags into language models. They create counterfactual syntax, i.e., randomized dependency graphs to encourage the model to focus on modeling the dependency relations based on the assumption that the features between counterfactual and actual dependency graphs should be different. They find that incorporating dependencies is more effective than using POS tags.
- Common Sense Beyond English: Evaluating and Improving Multilingual Language Models for Commonsense Reasoning. A new multilingual commonsense reasoning dataset covering 16 languages.
- Exploiting Language Relatedness for Low Web-Resource Language Model Adaptation: An Indic Languages Study. The authors propose to use transliteration to convert the unseen script of a low-resource language (LRL) to the script of a related high-resource language (HRL), i.e., Hindi. They also use bilingual lexicons to pseudo-translate text in a HRL to a LRL.
- Evaluating morphological typology in zero-shot cross-lingual transfer. This paper studies the effect of morphology on cross-lingual transfer. They study different transfer combinations for POS tagging and sentiment analysis. They find that a transfer to a language with a different morphology generally implies a higher loss. Furthermore, POS tagging is more sensitive to morphology than sentiment analysis.
- Consistency Regularization for Cross-Lingual Fine-Tuning. This paper introduces two consistency regularization methods using data augmentation for cross-lingual transfer.
- Exposing the limits of zero-shot cross-lingual hate speech detection. This paper finds that models misinterpret non-hateful language-specific taboo interjections as hate speech in zero-shot cross-lingual transfer. For instance, in Italian, porca puttana (literally pig + slut) is a generic taboo interjection without a misogynistic connotation.
- Including Signed Languages in Natural Language Processing. This best theme paper argues for why signed languages should be a stronger focus in NLP research. It encourages incorporating linguistic insight into sign language processing and core NLP tools to include signed languages.
Challenges in natural language generation
Natural language generation (NLG) is one of the most challenging settings for NLP. Some papers I enjoyed focused on some of the challenges of different NLG applications:
- Explainable Prediction of Text Complexity: The Missing Preliminaries for Text Simplification. This paper argues that text simplification should improve fairness and transparency of text information systems and that text simplification should be decomposed into a transparent set of tasks. They argue that current approaches neglect the first two parts of this pipeline: predicting whether a text should be simplified in the first place and identifying complex parts of the text. As a result, current models oversimplify already simple sentences.
- All That's 'Human' Is Not Gold: Evaluating Human Evaluation of Generated Text. This paper investigates how well evaluators distinguish between human and machine-generated text. They find that annotators were unable to distinguish GPT-3 generated and human-written text in stories, news, and recipes.
Virtual conference notes
Lastly, I want to share some brief notes to add to the ongoing conversation around a format for virtual conferences. I was mainly looking forward to attending the poster sessions, as these are usually my highlight of conferences (in addition to the social interactions). There were two in my timezone. Each poster session consisted of a large number of tracks being presented at the same time, which left considerably less time to explore and talk to poster presenters of other areas.
Specific posters were hard to find as virtual poster spaces did not show the name nor authors of a poster. In addition, space between posters was small so that audio between posters with large crowds would get mixed.
In the future, I would really like to see poster sessions that are:
- larger in number and covering only a few tracks each;
- spread out throughout the day and timezones;
- easy to navigate and with enough space between posters.
Two other things that would have improved my virtual conference experience were a) a chat system that is more seamlessly integrated into the conference platform and b) a tighter integration between the conference platform and the ACL anthology (linking to the papers in the anthology would be nice).
Attending the Zoom sessions for paper presentations went well and I enjoyed watching the recordings of other talks and keynotes.