AAAI 2019 Highlights: Dialogue, reproducibility, and more
This post discusses highlights of AAAI 2019. It covers dialogue, reproducibility, question answering, the Oxford style debate, invited talks, and a diverse set of research papers.


This post discusses highlights of the Thirty-Third AAAI Conference on Artificial Intelligence (AAAI-19).
I attended AAAI 2019 in Honolulu, Hawaii last week. Overall, I was particularly surprised by the interest in natural language processing at the conference. There were 15 sessions on NLP (most standing-room only) with ≈10 papers each (oral and spotlight presentations), so around 150 NLP papers (out of 1,150 accepted papers overall). I also really enjoyed the diversity of invited speakers who discussed topics from AI for social good, to adversarial learning and imperfect-information games (videos of all invited talks are available here). Another cool thing was the Oxford style debate, which required debaters to take controversial positions. This was a nice change of pace from panel discussions, which tend to converge to a uniform opinion.
Table of contents:
- Dialogue
- Reproducibility
- Question answering
- AI for social good
- Debate
- Adversarial learning
- Imperfect-information games
- Inductive biases
- Transfer learning
- Word embeddings
- Miscellaneous
Dialogue
In his talk at the Reasoning and Learning for Human-Machine Dialogues workshop, Phil Cohen argued that chatbots are an attempt to avoid solving the hard problems of dialogue. They provide the illusion of having a dialogue but in fact do not have a clue what we are saying or meaning. What we should rather do is recognize intents via semantic parsing. We should then reason about the speech acts, infer a user's plan, and help them to succeed. You can find more information about his views in this position paper.
During the panel discussion, Imed Zitouni highlighted that the limitations of current dialogue models affect user behaviour. 75-80% of the time users only employ 4 skills: "play music", "set a timer", "set a reminder", and "what is the weather". Phil argued that we should not have to learn how to talk, how to make an offer, etc. all over again for each domain. We can often build simple dialogue agents for new domains "overnight".
Reproducibility
At the Workshop on Reproducible AI, Joel Grus argued that Jupyter notebooks are bad for reproducibility. As an alternative, he recommended to adopt higher-level abstractions and declarative configurations. Another good resource for reproducibility is the ML reproducibility checklist by Joelle Pineau, which provides a list of items for algorithms, theory, and empirical results to enforce reproducibility.
A team from Facebook reported on their experiments reproducing AlphaZero in their ELF framework, training a model using 2,000 GPUs in 2 weeks. Reproducing an on-policy, distributed RL system such as AlphaZero is particularly challenging as it does not have a fixed dataset and optimization is dependent on the distributed environment. Training smaller versions and scaling up is key. For reproducibility, the random seed, the git commit number, and the logs should be stored.
During the panel discussion, Odd Eric Gunderson argued that reproducibility should be defined as the ability of an independent research team to produce the same results using the same AI method based on the documentation by the original authors. Degrees of reproducibility can be measured based on the availability of different types of documentation, such as the method description, data, and code.
Pascal van Hentenryck argued that reproducibility could be made part of the peer review process, such as in the Mathematical Programming Computation journal where each submission requires an executable file (which does not need to be public). He also pointed out that—empirically—papers with supplementary materials are more likely to be accepted.
Question answering
At the Reasoning and Complex QA Workshop, Ken Forbus discussed an analogical training method for QA that adapts a general-purpose semantic parser to a new domain with few examples. At the end of his talk, Ken argued that the train/test method in ML is holding us back. Our learning systems should use rich relational representations, gather their own data, and evaluate progress.
Ashish Sabharwal discussed the OpenBookQA dataset presented at EMNLP 2018 during his talk. The open book setting is situated between reading comprehension and open-ended QA on the textual QA spectrum (see below).
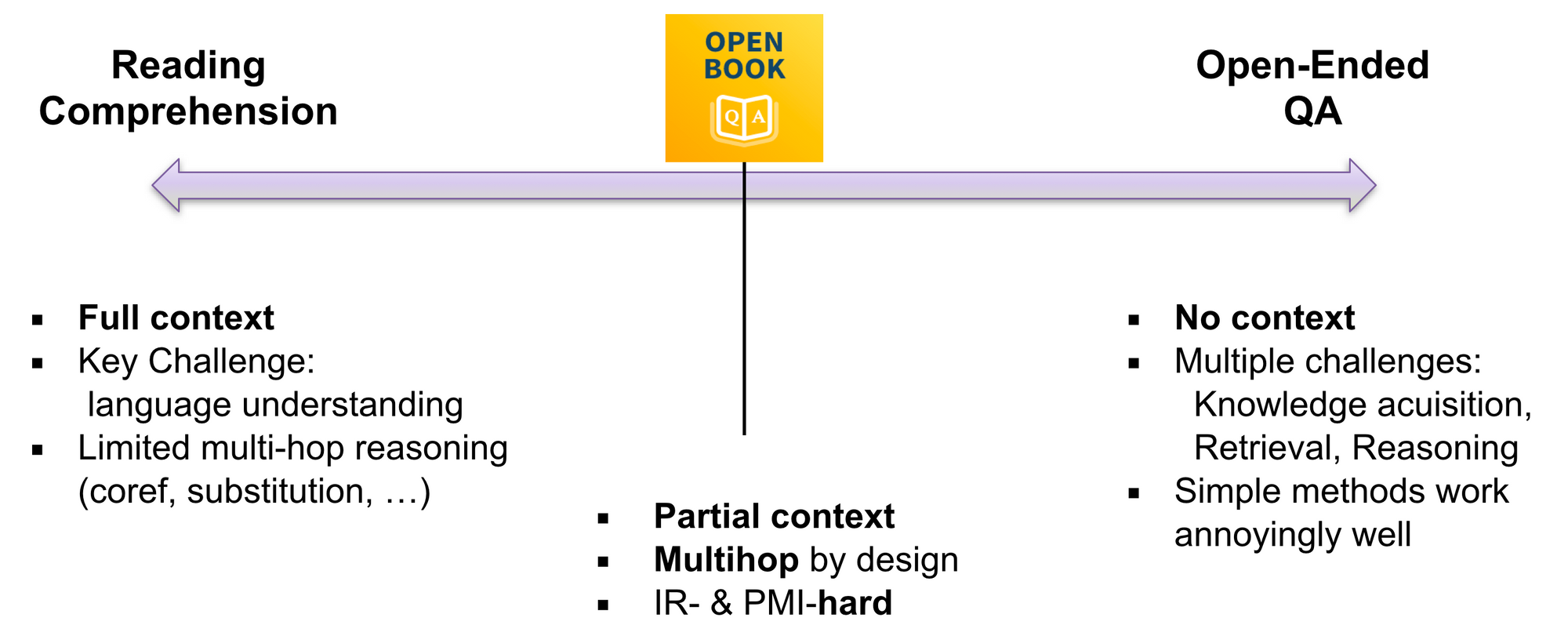
It is designed to probe a deeper understanding rather than memorization skills and requires applying core principles to new situations. He also argued that while entailment is recognized as a core NLP task with many applications, it is still lacking a convincing application to an end-task. This is mainly due to multi-sentence entailment being a lot harder, as irrelevant sentences often have significant textual overlap.
Furthermore, he discussed the design of leaderboards, which have to make tradeoffs along multiple competing axes with respect to the host, the submitters, and the community. A particular deficit of current leaderboards is that they make it difficult to share and build upon successful techniques. For an extensive discussion of the pros and cons of leaderboards, check out this recent NLP Highlights podcast.
The first part of the final panel discussion focused on important outstanding technical challenges for question answering. Michael Witbrock emphasized techniques to create datasets that cannot easily be exploited by neural networks, such as the adversarial filtering in SWAG. Ken argued that models should come up with answers and explanations rather than performing multiple choice question answering, while Ashish noted that such explanations need to be automatically validated.
Eduard Hovy suggested that one way towards a system that can perform more complex QA could consist of the following steps:
- Build a symbolic numerical reasoner that leverages relations from an existing KB, such as Geobase, which contains geography facts.
- Look at the subset of questions in existing natural language datasets, which require reasoning that is possible with the reasoner.
- Annotate these questions with semantic parses and train a semantic parsing model to convert the questions to logical forms. These can then be provided to the reasoner to produce an answer.
- Augment the reasoner with another reasoning component and repeat steps 2-3.
The panel members noted that such reasoners exist, but lack a common API.
Finally, here are a few papers on question answering that I enjoyed:
- COALA: A Neural Coverage-Based Approach for Long Answer Selection with Small Data: An approach that ranks answers based on how many of the question aspects they cover. They incorporate syntactic information via dependency parses and find that this improves performance.
- Multi-Task Learning with Multi-View Attention for Answer Selection and Knowledge Base Question Answering: Answer selection and knowledge base QA are learned jointly via multi-task learning. Attention is performed on different views of the data.
- QUAREL: A Dataset and Models for Answering Questions about Qualitative Relationships: A challenging new QA dataset of 2,771 story questions that require knowledge about qualitative relationships pertaining to 19 quantities such as smoothness, friction, speed, heat, and distance.
AI for social good
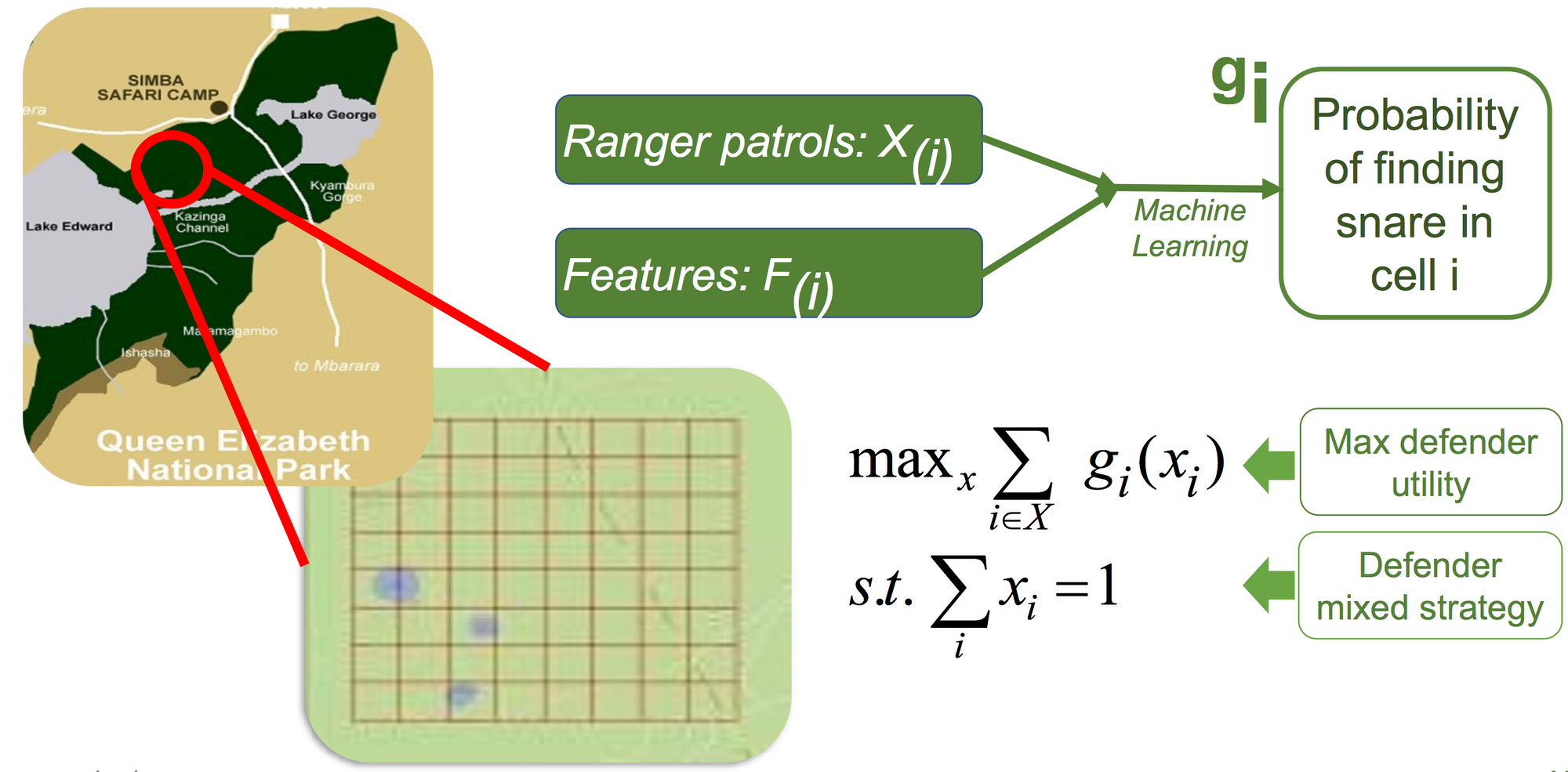
During his invited talk, Milind Tambe looked back on 10 years of research in AI and multiagent systems for social good (video available here; slides available here). Milind discussed his research on using game theory to optimize security resources such as patrols at airports, air marshal assignments on flights, coast guard patrols, and ranger patrols in African national parks to protect against poachers. Overall, his talk was a striking reminder of the positive effects AI can have if it is employed for social good.
Debate
The Oxford style debate focused on the proposition “The AI community today should continue to focus mostly on ML methods” (video available here). It pitted Jennifer Neville and Peter Stone on the 'pro' side against Michael Littman and Oren Etzioni on the 'against' side, with Kevin Leyton-Brown as moderator. Overall, the debate was entertaining and engaging to watch.

Here are some representative remarks from each of the debaters that stuck with me:
"The unique strength of the AI community is that we focus on the problems that need to be solved." – Jennifer Neville
"We are in the middle of one of the most amazing paradigm shifts in all of science, certainly computer science." – Oren Etzioni
"If you want to have an impact, don’t follow the bandwagon. Keep alive other areas." – Peter Stone
"Scientists in the natural sciences are actually very excited about ML as much of their research relies on expensive computations, which can be approximated with neural networks." – Michael Littman
There were some important observations and ultimately a general consensus that ML alone is not enough and we need to integrate other methods with ML. Yonatan Belinkov also live tweeted, while I tweeted some remarks that elicited laughs.
Adversarial learning
During his invited talk (video available here), Ian Goodfellow discussed a multiplicity of areas to which adversarial learning has been applied. Among many advances, Ian mentioned that he was impressed by the performance and flexibility of attention masks for GANs, particularly that they are not restricted to circular masks.
He discussed adversarial examples, which are a consequence of moving away from i.i.d. data: attackers are able to confuse the model by showing unusual data from a different distribution such as graffiti on stop signs. He also argued—contrary to the prevalent opinion—that deep models that are more robust are more interpretable than linear models. The main reason is that the latent space of a linear model is totally unintuitive, while a more robust model is more inspectable (as can be seen below).

Semi-supervised learning with GANs can allow models to be more sample-efficient. What is interesting about such applications is that they focus on the discriminator (which is normally discarded) rather than the generator where the discriminator is extended to classify n+1 classes. Regarding leveraging GANs for NLP, Ian conceded that we currently have not found a good way to deal with the large action space required to generate sentences with RL.
Imperfect-information games
In his invited talk (video available here), Tuomas Sandholm—whose AI Libratus was the first AI to beat top Heads-Up No-Limit Texas Hold'em professionals in January 2017—discussed new results for solving imperfect-information games. He stressed that only game-theoretically sound techniques yield strategies that are robust against all opponents in imperfect-information games. Other advantages of a game-theoretic approach are a) that even if humans have access to the entire history of plays of the AI, they still can't find holes in its strategy; and b) it requires no data, just the rules of the game.
For solving such games, the quality of the solution depends on the quality of the abstraction. Developing better abstractions is thus important, which also applies to modelling such games. In imperfect-information games, planning is important. In real-time planning, we must consider how the opponent can adapt to changes in the policy. In contrast to perfect-information games, states do not have well-defined values.
Inductive biases
There were several papers that incorporated different inductive biases into existing models:
- Document Informed Neural Autoregressive Topic Models with Distributional Prior: An extension of the DocNADE topic model using word embedding vectors as prior. The model is evaluated on 15 datasets.
- Syntax-aware Neural Semantic Role Labeling: The authors incorporate various syntax features into a semantic role labelling model. In contrast to common practice, which often tries to incorporate syntax via a TreeLSTM, they find that shortest dependency path and tree position features perform best.
- Relation Structure-Aware Heterogeneous Information Network Embedding: A network embedding model that treats different relations differently: For affiliation relations ("papers are published in conferences") Euclidean distance is used, while for interaction relations ("authors write papers") a translation-based distance is used.
- Gaussian Transformer: a Lightweight Approach for Natural Language Inference: A Transformer with a Gaussian prior for the self-attention that encourages focusing on neighbouring tokens.
- Gradient-based Inference for Networks with Output Constraints: A method to incorporate output constraints, e.g. matching number of brackets for syntactic parsing, agreement with parse spans for SRL, etc. into the model via gradient-based inference at test-time. The method is extensively evaluated and also performs well on out-of-domain data.
- ATOMIC: An Atlas of Machine Commonsense for If-Then Reasoning: A collection of 300k textual descriptions focusing on if-then relations with variables. Multi-task models that exploit the hierarchical structure of the data perform better.
Transfer learning
Papers on transfer learning ranged from multi-task learning and semi-supervised learning to sequential and zero-shot transfer:
- Transfer Learning for Sequence Labeling using Source Model and Target Data: Extension of fine-tuning techniques for NER for the case where the target task includes labels from the source domain (as well as new labels). 1) Output layer is extended with embeddings for new labels. 2) A BiLSTM takes the features of the source model as input and feeds its output to the target model.
- A Hierarchical Multi-task Approach for Learning Embeddings from Semantic Tasks: A hierarchical model that jointly learns coreference resolution, relation extraction, entity mention detection, and NER. It achieves state of the art on 3/4 tasks. (Disclaimer: I'm a co-author of this paper.)
- Revisiting LSTM Networks for Semi-Supervised Text Classification via Mixed Objective Function: A combination of entropy minimization, adversarial and virtual adversarial training with a simple 1-layer BiLSTM achieves state-of-the-art results on multiple text classification datasets.
- Zero-shot Neural Transfer for Cross-lingual Entity Linking: A cross-lingual entity linking model that trains a character-based entity similarity encoder on a bilingual lexicon of entities. Conceptually similar to cross-lingual word embedding models. For languages that do not share the same script, words are transcribed to phonemes.
- Zero-Shot Adaptive Transfer for Conversational Language Understanding: A model that performs zero-shot slot tagging by embedding the slot description and fine-tuning a pretrained model on the target domain.
- Unsupervised Transfer learning for Spoken Language Understanding in Intelligent Agents: A more light-weight ELMo model that pretrains a shared BiLSTM layer for intent classification and entity tagging and fine-tunes it with ULMFiT techniques.
- Latent Multi-task Architecture Learning: A multi-task learning architecture that enables more flexible parameter sharing between tasks and generalizes existing transfer and multi-task learning architectures. (Disclaimer: I'm a co-author of this paper.)
- GIRNet: Interleaved Multi-Task Recurrent State Sequence Models: A multi-task learning model that leverages the output from auxiliary models based on position-dependent gates. The model is applied to sentiment analysis and POS tagging of code-switched data and target-dependent sentiment analysis.
- A Generalized Language Model in Tensor Space: A higher-order language model that builds a representation based on the tensor product of word vectors. The model achieves strong results on PTB and WikiText.
Word embeddings
Naturally there were also a number of papers that provided new methods for learning word embeddings:
- Unsupervised Post-processing of Word Vectors via Conceptor Negation: A post-processing method that uses conceptors (a linear transformation) to dampen directions where a word vector has high variances. Post-processed embeddings not only improve on word similarity, but also on dialogue state tracking.
- Enriching Word Embeddings with a Regressor Instead of Labeled Corpora: A method that enriches word embeddings during training with sentiment information based on a regressor trained on valence information from a sentiment lexicon. The enriched embeddings improve performance on sentiment and non-sentiment tasks.
- Learning Semantic Representations for Novel Words: Leveraging Both Form and Context: A model that learns representations for novel words both from the surface form and the context—in contrast to previous models that only leverage one of the sources.
Miscellaneous
Finally, here are some papers that I enjoyed that do not fit into any of the above categories:
- What Is One Grain of Sand in the Desert? Analyzing Individual Neurons in Deep NLP Models: A supervised method to extract relevant neurons with regard to a task (by correlating neurons with the target property) and an unsupervised method to extract salient neurons with regard to the model (by correlating neurons across models). Techniques are evaluated on NMT and language modelling.
- What Should I Learn First: Introducing LectureBank for NLP Education and Prerequisite Chain Learning: A dataset containing 1,352 NLP lecture files classified according to a taxonomy with 208 prerequisite relation topics. A model is trained to learn prerequisite relations to answer "what should one learn first".
Cover image: AAAI-19 Opening Reception